연합 인식 시스템을 위한 사전 배포 복잡도 추정
** 본 논문은 데이터의 차원성·희소성·이질성 등 고유 특성과 클라이언트 수·구성 등 연합 학습 환경 요인을 결합한 복합 복잡도 지표를 제안한다. 제안 지표는 사전 학습 없이도 연합 인식 작업의 정확도와 통신 비용을 예측하며, MNIST 변형 실험을 통해 실제 연합 학습 성능과 강한 상관관계를 보였다. **
저자: KMA Solaiman, Shafkat Islam, Ruy de Oliveira
**
본 논문은 연합 인식 시스템의 사전 배포 단계에서 학습 난이도와 통신 비용을 예측할 수 있는 **클래스파이어-비종속 복잡도 추정 프레임워크**를 제시한다. 연구 배경으로는 엣지 AI 환경에서 데이터가 분산되고 프라이버시와 제한된 통신·연산 자원 때문에 연합 학습이 필수적이지만, 실제 배포 전에는 해당 작업이 얼마나 어려울지 가늠하기 어렵다는 점을 들었다. 기존 연구들은 주로 중앙집중식 데이터셋의 복잡도나 연합 학습 알고리즘 자체의 효율성에 초점을 맞췄으며, 데이터 구조와 분산 환경을 동시에 고려한 정량적 지표는 부족했다.
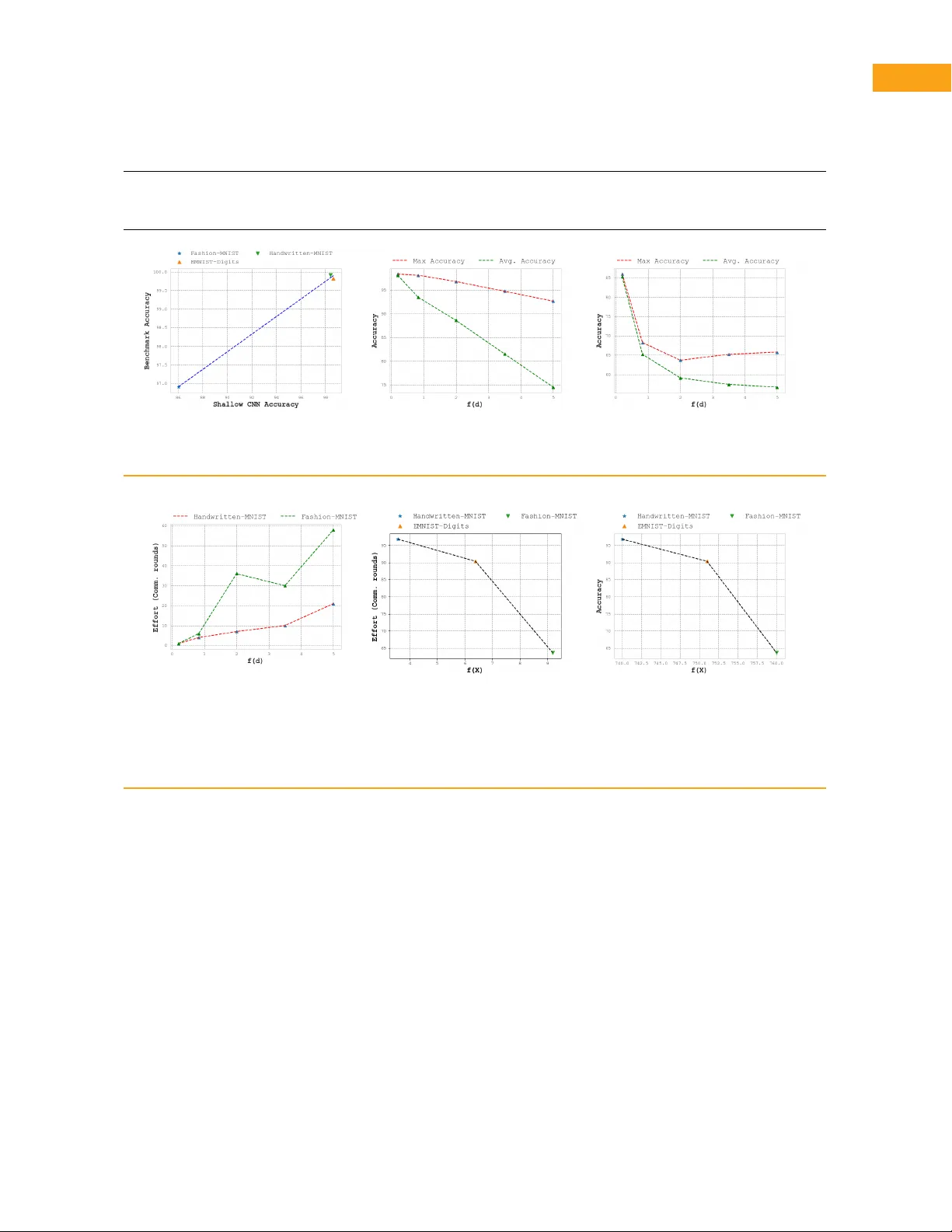
논문은 복잡도를 **내재 데이터 복잡도**와 **분산 환경 복잡도** 두 축으로 나누어 정의한다.
- **내재 데이터 복잡도**는 차원성, 희소성, 이질성으로 구성된다. 차원성은 샘플 수·특징 수·클래스 수의 곱으로 상한을 잡고, 실제 매니폴드 차원을 k‑NN 기반 최대우도 추정기로 측정한다. 희소성은 PCA와 Isomap을 이용해 데이터가 소수의 주성분에 얼마나 집중되는지를 정량화한다. 이질성은 픽셀 레벨 엔트로피를 통해 데이터의 불확실성을 평가한다. 이 세 측정값은 모두 라벨이나 모델 성능에 의존하지 않으며, 데이터 자체의 구조적 난이도를 객관적으로 드러낸다.
- **분산 환경 복잡도**는 연합 학습에서 클라이언트 수, 데이터 파티셔닝 방식, 참여 빈도 등을 포함한다. 논문은 연합 학습 과정을 트리 형태로 모델링해 각 경로가 서로 다른 클라이언트 집합을 순차적으로 참여시키는 시나리오를 가정한다. 이를 통해 동일 데이터셋이라도 클라이언트 구성에 따라 복잡도가 변한다는 점을 강조한다.
복합 복잡도 지표는 다음과 같이 수식화된다.
\(F(d,X)=\beta\|X\|_2 + f(d)\)
여기서 \(X=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기