LLM 숨은 상태에서 숫자 경계의 범주 인식: 구조적 왜곡 발견
본 연구는 아라비아 숫자(10·100) 전환점에서 대형 언어 모델(LLM)의 은닉층 표현이 범주 인식(CP)과 유사한 기하학적 왜곡을 보인다는 것을 입증한다. 6개 모델을 대상으로 대표성 유사성 분석(RSA)을 수행했으며, 로그 거리와 경계 부스트를 결합한 CP‑Additive 모델이 연속형 모델보다 모든 주요 층에서 더 높은 적합도를 보였다. 이 효과는 토큰화·문자수 변화를 포함한 구조적 불연속에만 나타났고, 온도와 같은 언어적 범주에는 나타…
저자: Jon-Paul Cacioli
이 논문은 ‘범주 인식(Categorical Perception, CP)’이라는 심리학적 현상을 대형 언어 모델(LLM)의 은닉 상태에 적용해, 구조적 입력 불연속이 어떻게 내부 표현을 왜곡시키는지를 체계적으로 조사한다. 연구자는 아라비아 숫자(4~20, 70~130 등)를 사용해 두 개의 명확한 경계, 즉 10(한 자리 → 두 자리)과 100(두 자리 → 세 자리) 전환점을 설정했다. 이 전환점은 문자 수, 토큰 수, 어휘 형태가 동시에 변하는 구조적 불연속을 제공한다.
실험에 사용된 모델은 Llama‑3‑Instruct, Llama‑3‑Base, Mistral‑7B‑Instruct, Gemma‑2‑9B‑IT, Qwen2.5‑7B‑Instruct, Phi‑3.5‑mini‑instruct 등 총 6개이며, 각각 서로 다른 토크나이저와 아키텍처를 갖는다. 특히 Llama‑3은 토큰화 단계에서 한 자리·두 자리 숫자를 모두 하나의 토큰으로 처리하지만, 문자 수와 어휘 형태가 변함으로써 경계 효과가 여전히 나타난다.
대표성 유사성 분석(RSA)에서는 각 숫자값에 대해 네 개의 문맥(sentence)에서 은닉 상태를 추출하고, 평균(centroid)을 구해 코사인 거리 기반의 경험적 RDM을 만든다. 이 경험적 RDM을 다섯 가지 이론적 모델(연속 로그, CP‑Additive, CP‑Multiplicative, 순수 범주형, 선형)과 스피어만 상관으로 비교했다. Mantel permutation(10,000회)과 Benjamini‑Hochberg FDR 보정을 통해 통계적 유의성을 검증한 결과, 모든 모델의 주요 층(primary layers)에서 CP‑Additive 모델이 연속 모델보다 높은 상관을 보였으며, 이는 100% 층에서 일관되었다.
경계 부스트 파라미터 β는 사전 고정(β=1.0)했음에도 효과가 유지되었고, 비경계 위치(예: 15, 150)와 온도 도메인(Hot/Cold)에서는 CP‑Additive 모델이 연속 모델을 능가하지 못했다. 이는 구조적 토큰화 불연속이 CP 효과의 필수 조건임을 시사한다. 또한, 계층적 회귀 분석을 통해 경계 교차 여부가 로그 거리 외에 5~27%의 추가 분산을 설명한다는 점을 확인했다.
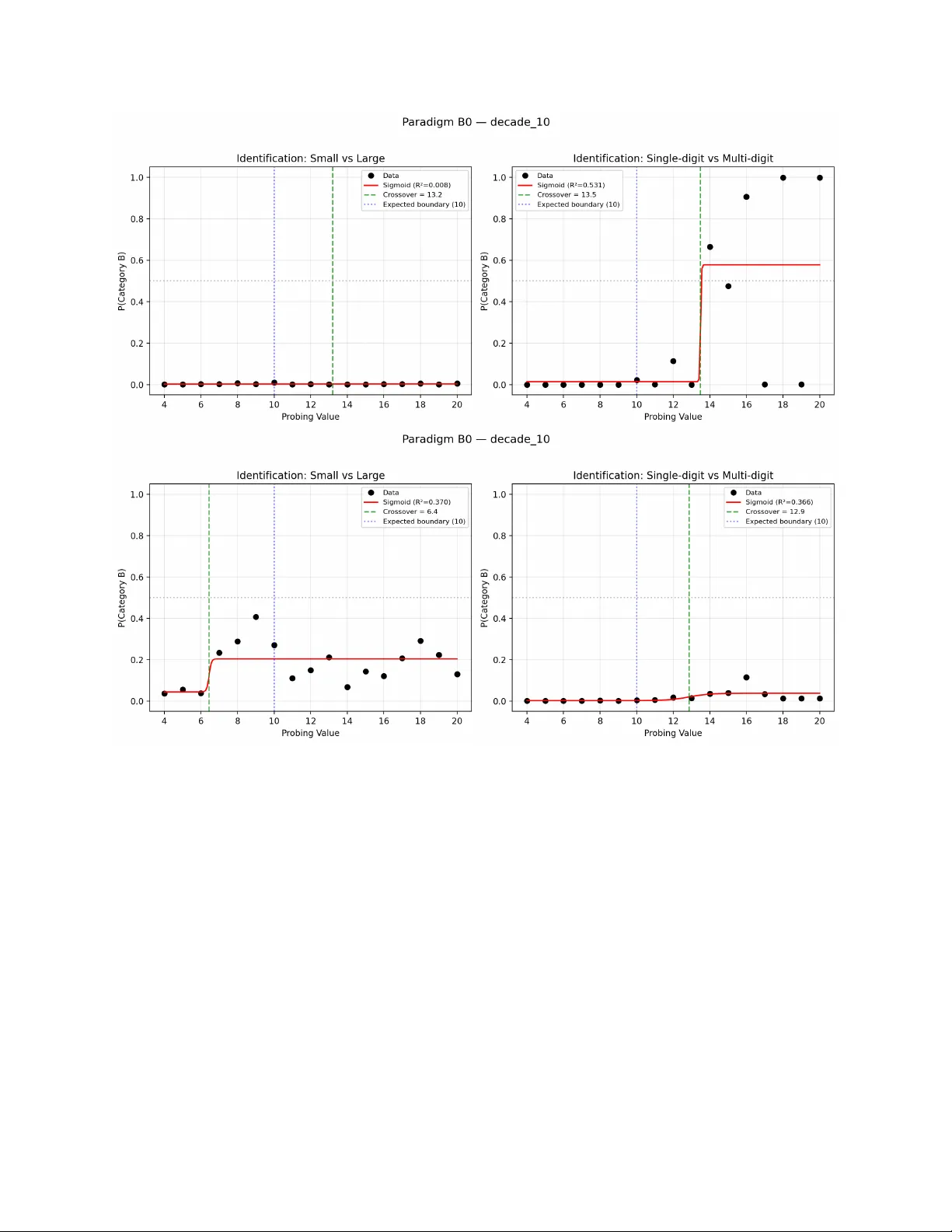
행동적 실험에서는 세 가지 패러다임을 사용했다. B0(식별)에서는 모델에게 “single‑digit vs multi‑digit” 등 세 가지 프레이밍을 제시했으며, Gemma와 Qwen은 명확히 경계를 식별했다. B(차별)에서는 두 숫자 중 큰 값을 선택하게 하여, 경계 근처에서 정확도·신뢰도(로그잇값 절대값)가 상승함을 관찰했다. C(정밀도 기울기)에서는 인접 숫자 쌍 사이의 표현 차이 역수(1/||h(n+1)-h(n)||)를 계산해, 경계에서 급격한 감소(precision dip)를 확인했다.
‘구조적 CP’와 ‘클래식 CP’의 차이는 모델이 경계 인식을 언어적으로 표현할 수 있느냐에 있다. Llama, Mistral, Phi는 은닉 공간에서 경계 왜곡을 보였지만, 식별 과제에서 명시적 범주 구분을 하지 못했다. 반면 Gemma와 Qwen은 언어적 식별과 기하학적 왜곡이 동시에 나타났다.
인과적 개입(E) 실험에서는 각 층의 은닉 상태에 경계 방향 벡터(v_cat)를 일정 비율(0.25~1.0)로 더해 보강했으며, 이는 차별 신뢰도(Δ|logit|)를 유의하게 증가시켰다. 무작위 방향 패치와 비교했을 때 효과가 현저히 크며, 이는 은닉 공간의 구조적 변형이 실제 모델 출력에 기능적 영향을 미친다는 증거다.
마지막으로, 논문은 여덟 가지 사전 등록 가설을 검증했으며, 모두(또는 대부분) 성공적으로 입증했다. 특히 H1(대표성 기하학에서 CP‑Additive 우세)과 H2(경계 기여도) 등이 강력히 지지되었다.
결론적으로, 이 연구는 (1) LLM의 은닉 상태가 구조적 입력 불연속에 의해 CP와 유사한 기하학적 왜곡을 나타낸다, (2) 이러한 왜곡은 토큰화·문자수·어휘 형태 변화와 같은 구조적 요인에 의해 독립적으로 발생한다, (3) 모델에 따라 범주 인식 능력과 왜곡이 일치하거나 분리될 수 있음을 보여준다. 이는 인공 신경망이 인간 인지와 유사한 ‘범주화’ 메커니즘을 자동으로 형성할 수 있음을 시사하며, LLM 설계·해석 및 인지 과학과의 교차 연구에 중요한 통찰을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기