현실감 넘치는 음성 디자인, MOSS‑VoiceGenerator
MOSS‑VoiceGenerator는 자연어 설명만으로 새로운 화자 음색을 생성하는 오픈소스 TTS 모델이다. 영화·드라마 등 실생활 음향이 담긴 대규모 인‑더‑와일드 데이터를 활용해 음성의 ‘살아있는’ 느낌을 재현한다. 디코더‑전용 LLM 기반의 오토레그레시브 구조와 1.7 B 파라미터 백본을 사용해 효율적인 학습·추론을 구현했으며, InstructTTSEval 벤치마크에서 경쟁 모델 대비 높은 지시 수행도와 자연스러움을 보였다.
저자: Kexin Huang, Liwei Fan, Botian Jiang
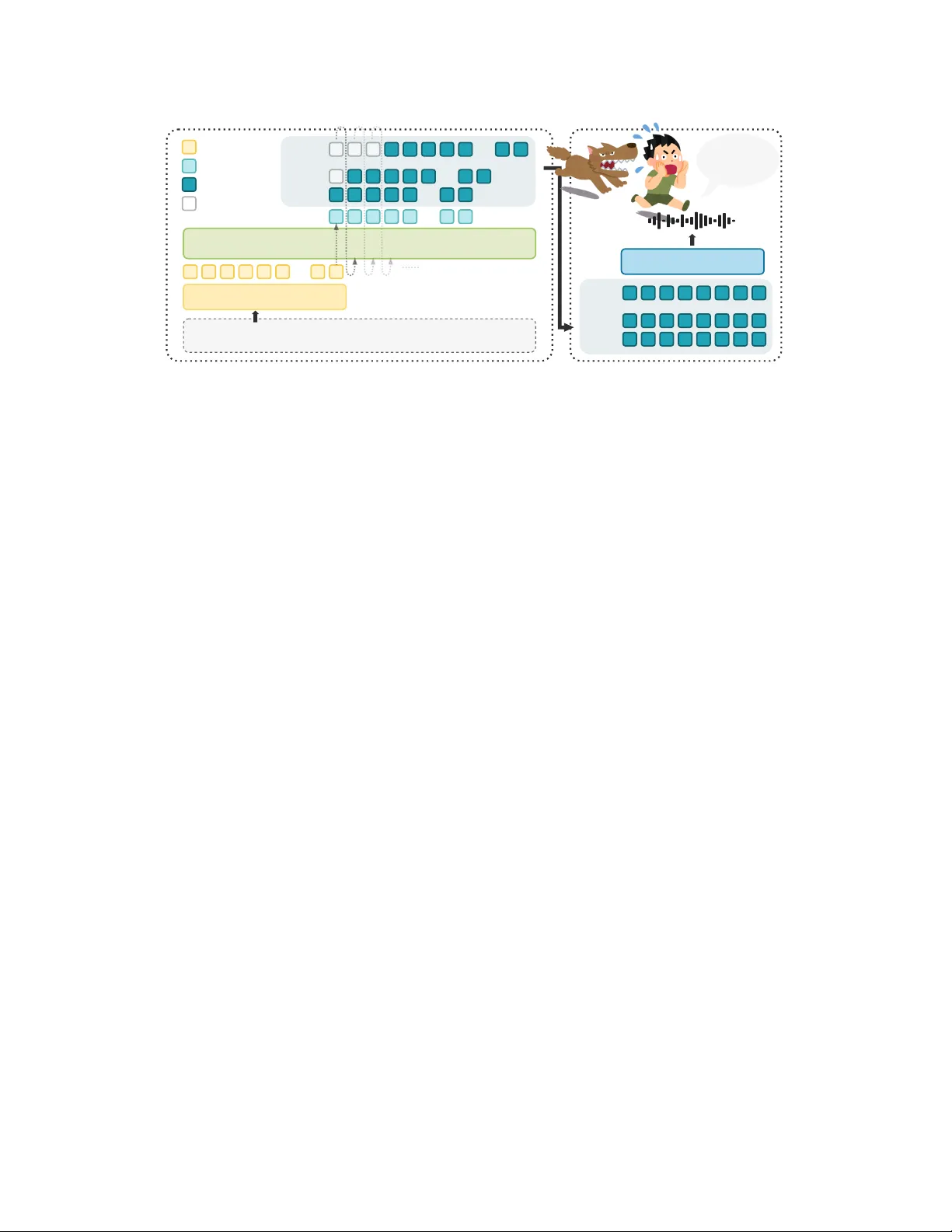
본 논문은 자연어 기반 음성 디자인을 목표로 하는 MOSS‑VoiceGenerator를 소개한다. 기존 TTS·음성 클로닝 모델은 스튜디오 녹음에 의존해 깨끗하고 정교한 음성을 생성하지만, 일상 대화에서 나타나는 호흡, 억양의 미세한 불규칙성, 배경 잡음 등 ‘삶의 흔적’이 결여돼 인간적인 자연스러움이 부족하다. 이를 해결하고자 연구팀은 영화·드라마·시리즈 등 실생활 음향이 풍부한 대규모 인‑더‑와일드 데이터를 수집·정제해 학습에 활용하였다.
데이터 수집 파이프라인은 두 단계로 구성된다. 첫 번째 단계에서는 영상 콘텐츠에서 음성을 추출하고, Diarization(스피커 구분)·MossFormer2 기반 노이즈 감소·DNSMOS ≥ 3.0 품질 필터링을 거쳐 단일 화자 구간만을 선별한다. 이어 Whisper‑large‑v3로 비중국·비영어 구간을 제외하고, Qwen3‑Omni‑30B‑A3B‑Instruct를 사용해 정확한 전사(ASR)를 수행한다. 전사된 텍스트는 Gemini‑2.5 Pro를 통해 상세 캡션으로 변환되고, Qwen3‑32B‑A3B‑Instruct가 캡션을 자연어 형태의 타임버(음색) 지시문으로 변환한다. 이렇게 구축된 5 000시간 규모의 초기 데이터셋은 이후 두 번째 단계에서 확대된다. 두 번째 단계에서는 (a) 초기 데이터로 파인튜닝한 스피치 캡션 모델을 이용해 대규모 음성에 자동 캡션을 부여하고, (b) 텍스트‑음성 정렬 임베딩을 학습해 스타일‑가이드 오디오 마이닝을 수행한다. GPT‑5가 생성한 풍부한 스타일 프롬프트를 임베딩 공간에 쿼리하면, 기존 중립적인 TTS 베이스 코퍼스에서 감정·톤·텍스처가 뚜렷한 10 000시간 추가 데이터를 추출한다. 최종적으로 내부 크라우드소싱 더빙 데이터와 결합해 총 25 000시간(중국어 18 025h, 영어 7 047h)의 고품질 데이터셋을 확보하였다.
모델 아키텍처는 MOSS‑TTS와 동일한 디코더‑전용 LLM에 MOSS‑Audio‑Tokenizer를 결합한 오토레그레시브 구조다. 입력은 “음성 지시 + 텍스트” 형태의 대화형 템플릿으로 구성되며, LLM은 이를 토큰 시퀀스로 인코딩한 뒤 다음 오디오 토큰을 예측한다. 훈련 시에는 전체 토큰 시퀀스에 대해 다음 토큰 예측 손실을 최소화하고, 파라미터 전체를 업데이트한다(LoRA 등 파라미터 효율 기법 미사용). 토큰화는 RVQ 코드북의 앞 16 레이어만 사용해 메모리와 연산량을 절감하였다. 이 설계는 (1) 언어 모델 훈련 파이프라인을 그대로 재사용해 대규모 사전학습과 지시 튜닝을 손쉽게 적용, (2) 오토레그레시브 특성으로 장기 프로소디와 음색 일관성을 자연스럽게 학습, (3) 디퓨전·플로우 기반 모델에 비해 추론 단계가 단순하고 실시간 배포가 용이하다는 장점을 제공한다.
학습은 Qwen3 체크포인트를 초기화점으로 사용했으며, 1.7 B와 8 B 두 규모를 비교했다. 1.7 B 모델이 8 B 대비 비슷한 지시 수행도와 더 높은 음성 다양성을 보였으며, 추가적인 TTS‑base 데이터(10 000시간)를 혼합해도 객관적 지표와 인간 평가에서 유의미한 향상이 없었다. 영어 데이터가 상대적으로 적어 초기 모델이 비정상적인 멈춤을 보였지만, 동일 음성에 대해 두 개의 서로 다른 자연어 지시를 생성해 학습량을 두 배로 늘리는 ‘Instruction Rewriting’ 기법으로 영어 프로소디의 안정성을 크게 개선했다.
평가는 공개 벤치마크 InstructTTSEval을 사용했다. 이 벤치마크는 APS(정밀 acoustic parameter 지정), DSD(자연어 서술형 지시), RP(역할‑플레이) 세 가지 과제로 구성되며, 각각 1 000개 샘플·2 언어(중국어·영어)로 이루어져 있다. MOSS‑VoiceGenerator는 APS에서 68.2 %(EN)·68.7 %(ZH), DSD에서 78.0 %·78.0 %의 지시 수행 정확도를 기록했으며, RP에서는 80.0 %·74.0 %를 달성해 경쟁 모델(Gemini‑TTS‑Pro, GPT‑4o‑mini‑TTS, VoxInstruct 등)과 비교해 전반적인 자연스러움과 다양성에서 우수함을 보였다. 특히 ‘Role‑Play’ 시나리오에서 인간적인 감정 표현과 억양 변화를 잘 구현한다는 주관적 평가 결과가 돋보인다.
논문의 주요 기여는 다음과 같다. (1) 실생활 음향을 대규모로 수집·정제해 자연스러운 음성 생성이 가능한 오픈소스 TTS 모델을 제시, (2) 영화·드라마 기반 데이터 파이프라인과 자동 캡션·스타일 지시 생성 방법을 제안해 비용 효율적인 데이터 증강을 실현, (3) 디코더‑전용 LLM 기반 오토레그레시브 구조를 통해 텍스트와 음성 지시를 하나의 시퀀스로 통합, (4) 객관적·주관적 평가에서 경쟁 모델 대비 높은 성능을 입증.
한계점으로는 영어 데이터 부족으로 인한 프로소디 불안정, 다국어 확장성 부족, 오토레그레시브 토큰 예측이 고해상도 파형을 직접 생성하는 디퓨전 모델에 비해 미세한 음향 디테일 재현에 한계가 있을 수 있다는 점을 들 수 있다. 향후 연구에서는 다국어 데이터 확대, 고해상도 토큰 스킴 도입, 사용자 피드백 기반 지속적 파인튜닝 등을 통해 실용성을 더욱 강화할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기