자동 프로토타입 선택을 통한 해석 가능한 강화학습
본 논문은 강화학습(RL) 에서 해석성을 제공하는 Prototype‑Wrapper Networks(PW‑Nets)의 한계를 극복하기 위해, 전문가가 직접 정의한 프로토타입 대신 데이터 자체에서 최적의 프로토타입을 자동으로 추출하는 방법을 제안한다. 저차원 매니폴드 학습과 메트릭 학습을 결합한 두 단계 구조를 통해, 인코딩된 상태 공간의 기하학적 구조를 보존하면서 클래스 간 구분력을 갖는 프로토타입을 선정한다. 실험 결과, 제안 방법은 기존 PW…
저자: Bodla Krishna Vamshi, Haizhao Yang
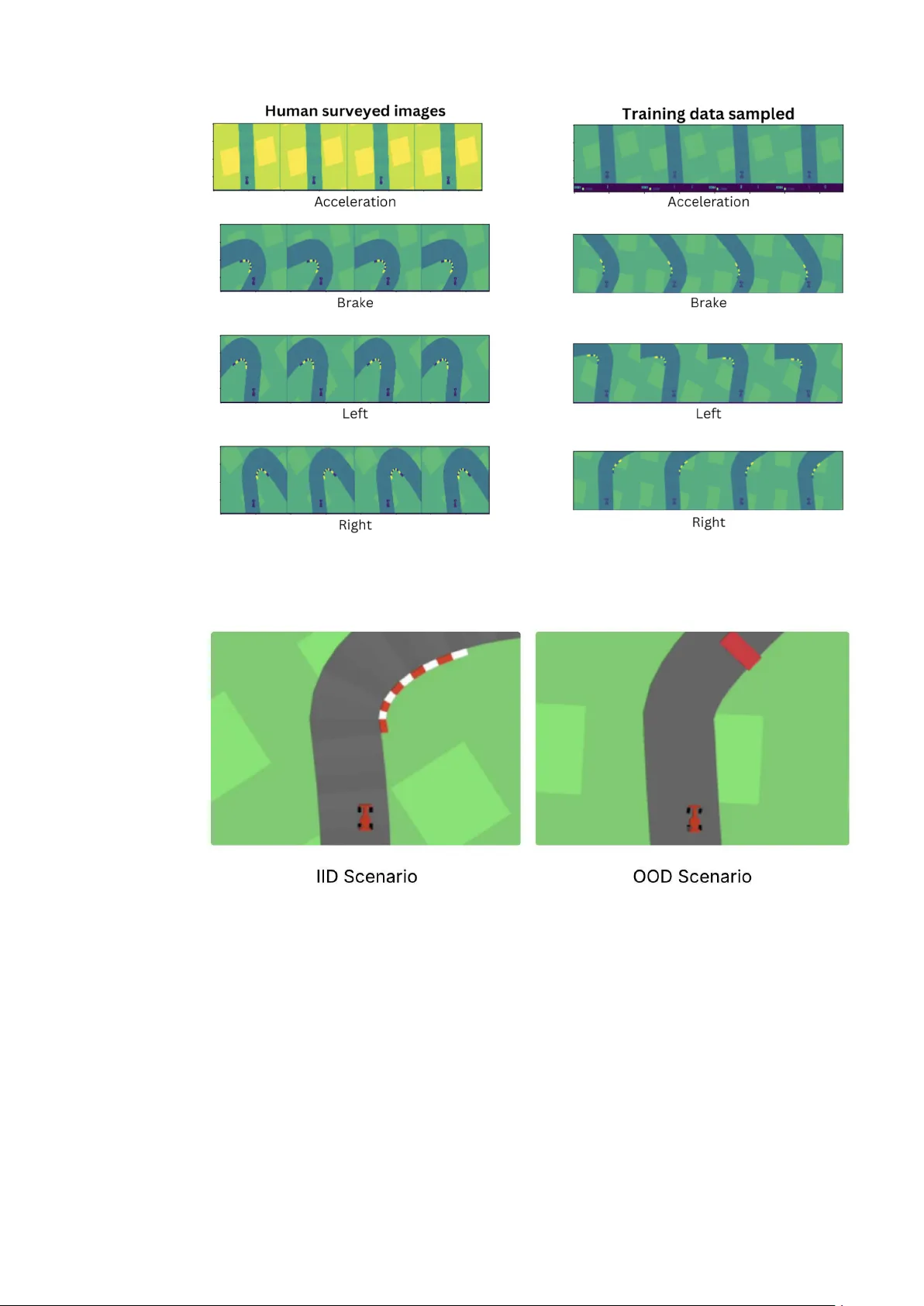
본 논문은 강화학습(RL) 에이전트의 의사결정을 인간이 이해할 수 있는 형태로 제공하기 위해, 기존 Prototype‑Wrapper Networks(PW‑Nets)의 핵심 한계인 ‘수동 프로토타입 정의’를 자동화하는 새로운 방법을 제안한다. 연구 배경으로는 RL이 게임, 로봇 제어, 대규모 언어 모델 정렬 등 다양한 분야에서 뛰어난 성과를 보이고 있으나, 정책이 블랙박스 형태로 동작해 신뢰성 확보가 어려운 점을 들었다. 기존 해석 기법은 주로 컴퓨터 비전·자연어 처리에 초점을 맞추었고, RL에 적용할 경우 해석성과 성능 사이의 트레이드오프가 심각했다. PW‑Nets는 프로토타입 기반 설명을 제공해 이러한 트레이드오프를 완화했지만, 프로토타입을 전문가가 직접 선정해야 하는 부담이 있었다.
논문은 이를 해결하기 위해 ‘Principal Prototype Analysis on Manifold’이라는 자동 프로토타입 선택 프레임워크를 설계한다. 핵심 아이디어는 다음과 같다. (1) 매니폴드 가설에 기반해 인코더가 만든 고차원 상태 표현을 저차원 매니폴드 상에 존재한다고 가정하고, 이를 조각별 선형 서브매니폴드로 분해한다. 배치 내에서 무작위 앵커 포인트를 선택하고, 각 앵커 주변의 최근접 이웃을 모아 로컬 m‑차원 선형 서브스페이스를 구성한다. 이렇게 하면 프로토타입이 실제 데이터의 지역 구조를 반영하게 된다. (2) 매니폴드 손실(L_manifold)과 메트릭 손실(L_PA, Proxy‑Anchor) 을 동시에 최소화한다. 매니폴드 손실은 같은 서브매니폴드 내 포인트 간 거리를 최소화하고, 서로 다른 서브매니폴드 간 거리를 늘려 지역 기하학을 보존한다. Proxy‑Anchor 손실은 클래스(여기서는 행동) 별 프록시 벡터를 학습해 같은 행동을 취하는 상태들을 군집화하고, 다른 행동과는 멀어지게 만든다. 프록시 벡터는 학습 후 가장 가까운 실제 인코딩 샘플에 매핑되어 실제 데이터 인스턴스로서의 프로토타입을 제공한다.
학습 절차는 두 단계로 나뉜다. 첫 단계에서는 위 두 손실을 결합한 총 손실 L_total = L_manifold + L_PA 를 사용해 경량 신경망 h_θ 를 학습한다. 이 단계에서 얻어진 프록시 벡터 θ_m 은 각 행동 클래스당 하나의 프로토타입 후보를 대표한다. 두 번째 단계에서는 이 프로토타입을 고정하고, 기존 PW‑Net 구조에 삽입한다. 이후 PW‑Net은 강화학습 목표(예: 정책 그라디언트, 가치 함수 손실)만을 최적화하므로, 프로토타입이 정책 성능에 부정적 영향을 주지 않는다.
실험은 OpenAI Gym의 CartPole, MountainCar, Acrobot 등 표준 환경을 사용했다. 비교 대상은 (1) 원본 블랙박스 정책, (2) 기존 PW‑Net(수동 프로토타입), (3) 제안 자동 프로토타입 PW‑Net. 결과는 제안 방법이 기존 PW‑Net과 거의 동등한 평균 보상을 기록했으며, 블랙박스 정책과도 큰 격차 없이 경쟁적인 성능을 보였다. 또한, 프로토타입이 실제 트레이닝 샘플에 매핑되므로, 사용자는 “이 행동은 이와 유사한 과거 상태에서의 행동과 일치한다”는 직관적인 설명을 얻을 수 있다. 정량적 평가 외에도 시각화 실험을 통해 프로토타입이 매니폴드 상에서 어떻게 분포하고, 행동별로 어떻게 구분되는지를 보여주었다.
논문의 주요 기여는 다음과 같다. 첫째, 프로토타입 선택을 자동화함으로써 전문가 의존성을 제거하고, 대규모 RL 시스템에 적용 가능한 확장성을 확보했다. 둘째, 매니폴드 기반 기하학적 정렬과 메트릭 기반 판별력을 결합한 손실 설계로, 프로토타입이 데이터 분포를 왜곡하지 않으면서도 높은 구분력을 갖도록 했다. 셋째, 프로토타입 선택과 정책 학습을 단계적으로 분리함으로써, 해석성 확보와 성능 유지 사이의 트레이드오프를 최소화했다. 마지막으로, 코드와 데이터셋을 공개하여 재현성을 높이고, 향후 연구자들이 다양한 RL 도메인에 적용할 수 있는 기반을 제공한다. 전반적으로, 이 연구는 강화학습 시스템의 투명성을 높이는 동시에 실용적인 성능을 유지하려는 목표에 크게 기여한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기