분산 SGD에서 전략적 에이전트를 위한 진실성 인센티브와 수렴 보장 메커니즘
본 논문은 중앙 서버 없이 완전 분산 환경에서 전략적 에이전트가 그래디언트를 조작하는 문제를 해결한다. 저자들은 ε‑인센티브 호환성과 예산 균형을 만족하는 분산 지급 메커니즘을 제안하고, 이를 적용한 분산 확률적 경사 하강법(Distributed SGD)의 수렴 속도를 일반 및 강볼록 함수에 대해 정량화한다. 또한, 전략적 행동으로 얻을 수 있는 누적 이득이 유한함을 증명하고, FEMNIST와 Shakespeare 데이터셋을 이용한 실험을 통해…
저자: Ziqin Chen, Yongqiang Wang
**1. 연구 배경 및 문제 정의**
분산 학습은 데이터와 연산을 여러 에이전트에 분산시켜 확장성, 프라이버시, 내결함성을 확보한다. 기존 알고리즘은 모든 참여자가 진실된 그래디언트를 제공한다는 전제 하에 설계되었으며, 중앙 서버가 존재하지 않는 완전 분산 환경에서는 이러한 가정이 깨지기 쉽다. 전략적 에이전트는 자신의 로컬 손실을 최소화하거나 경쟁자를 약화시키기 위해 그래디언트를 확대하거나 노이즈를 삽입한다. 이러한 조작은 전체 최적화 목표를 악화시키고, 기존 분산 SGD는 수렴을 보장하지 못한다.
**2. 기존 접근법의 한계**
- **인센티브 기반 메커니즘**(VCG 등)은 중앙 서버가 전체 정보를 수집해 지급을 계산해야 하며, 예산 균형을 보장하지 못한다.
- **연합 차등 프라이버시(JDP) 기반** 방법은 노이즈를 추가해 진실성을 확보하지만, 최적화 정확도가 손실된다.
- 두 접근 모두 무한 반복 시 전략적 행동에 대한 누적 이득이 무한히 증가할 수 있다.
**3. 제안 메커니즘 설계**
저자들은 완전 분산 환경에서 작동하는 지급 메커니즘을 제안한다. 주요 특징은 다음과 같다.
- **분산 지급 계산**: 각 에이전트는 자신의 로컬 그래디언트와 이웃으로부터 받은 파라미터를 이용해 지급을 산출한다. 중앙 서버가 필요 없으며, 지급 정보는 이웃 간에 직접 전파된다.
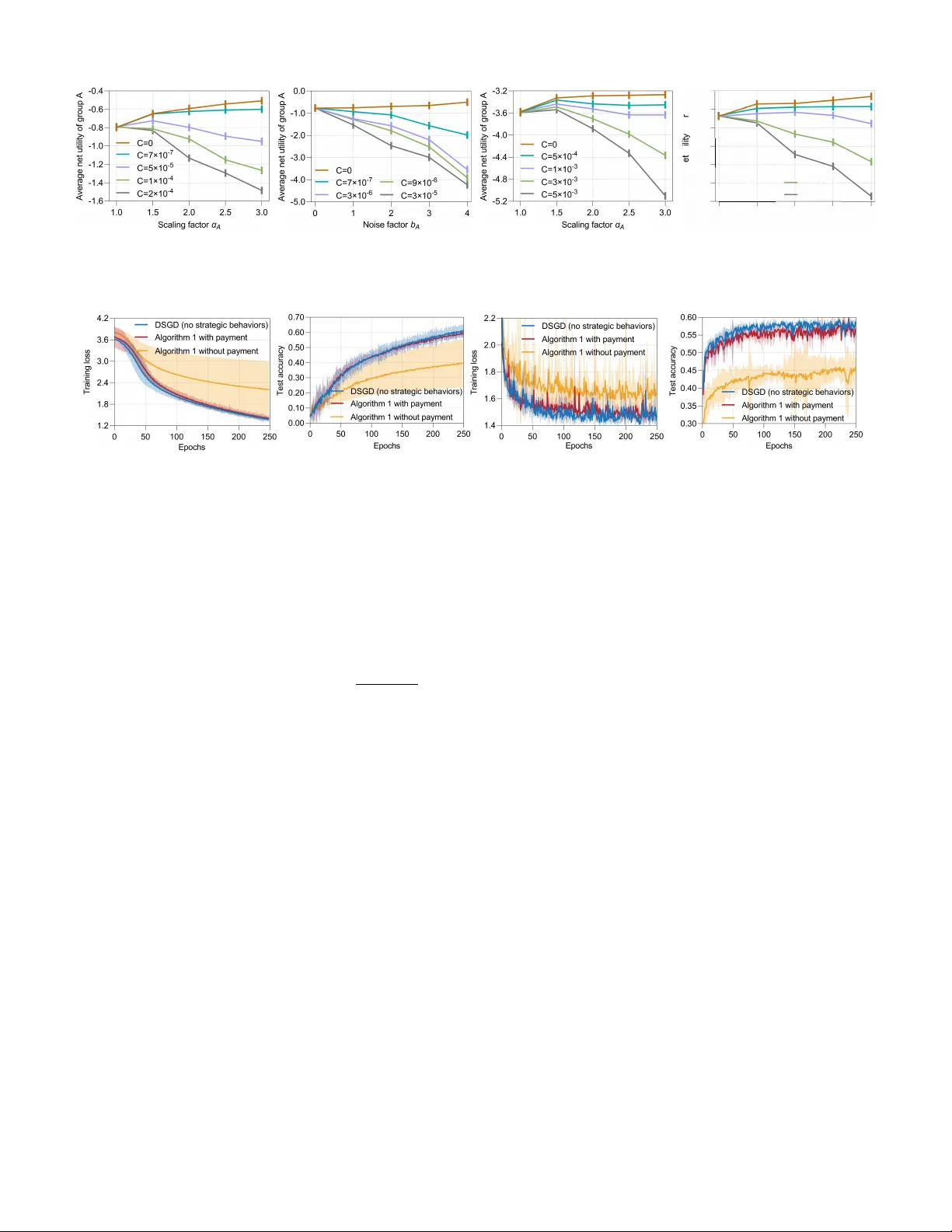
- **ε‑인센티브 호환성**: Lemma 1에서 전략적 행동에 대한 즉시 인센티브가 시간에 따라 0으로 수렴함을 보이고, Theorem 2에서 무한 반복에서도 누적 이득이 ε 이하로 제한됨을 증명한다. 이는 전략적 에이전트가 장기적으로 이득을 얻지 못하도록 만든다.
- **예산 균형**: 메커니즘 설계 시 전체 지급의 합이 0이 되도록 조정했으며, 이는 외부 자금 투입 없이 시스템이 자체적으로 지속 가능함을 의미한다.
**4. 알고리즘 통합 및 수렴 분석**
제안된 지급 메커니즘을 기존 Distributed SGD에 통합한다. 업데이트 식은
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기