분해 기반 심볼릭 밀도 추정 AI Kolmogorov 프레임워크
본 논문은 심볼릭 회귀를 활용해 연속 확률밀도함수를 해석 가능한 수식 형태로 복원하는 새로운 방법인 AI‑Kolmogorov을 제안한다. 데이터의 클러스터링·그래프 구조 학습을 통해 문제를 부분적으로 분해하고, 비모수 밀도 추정기로부터 얻은 근사값을 심볼릭 회귀의 목표로 사용한다. 합성 혼합 모델, 다변량 정규분포, 고에너지 물리학에서 유도된 특수 분포 등 다양한 실험을 통해 제안 방법이 복잡한 고차원 분포를 정확히 재구성하면서도 해석 가능한 …
저자: Angelo Rajendram, Xieting Chu, Vijay Ganesh
본 논문은 심볼릭 회귀(SR)를 이용해 연속 확률밀도함수를 해석 가능한 수식 형태로 복원하는 새로운 프레임워크인 AI‑Kolmogorov을 제안한다. 기존 SR은 주로 지도학습 회귀나 미분방정식 발견에 사용돼 왔으며, 밀도 추정이라는 비지도 과제에 직접 적용하기는 어려웠다. 그 이유는 (i) 확률밀도는 비음성 및 정규화라는 강력한 제약을 가져야 하고, (ii) 고차원에서는 탐색 공간이 급격히 커지며, (iii) 비모수 밀도 추정은 정확하지만 해석 가능성이 없기 때문이다. AI‑Kolmogorov은 이러한 문제를 단계별 파이프라인으로 해결한다.
첫 단계는 선택적 전처리로, 데이터의 구조에 따라 클러스터링과/또는 확률 그래프 구조 학습을 수행한다. 클러스터링은 다중 모드가 명확히 구분되는 경우 각 클러스터를 독립적인 서브밀도로 분해해 가산적 합성으로 재구성한다. 저자는 DBSCAN을 예시로 들며, 자동으로 클러스터 수와 형태를 결정할 수 있음을 강조한다. 구조 학습은 변수 간 독립성을 탐지해 곱셈적 분해를 가능하게 한다. 이때 PC 알고리즘을 사용해 연속형 데이터에 대한 조건부 독립 검정을 수행하고, 연결된 컴포넌트별로 SR을 적용한다. 이러한 분해는 차원의 저주를 완화하고, 각 서브문제에 대해 더 간단한 식을 찾을 확률을 높인다.
두 번째 단계는 비모수 밀도 추정이다. 저자는 기본적으로 Gaussian 커널을 이용한 KDE를 사용하고, 차원이 높아지면 Neural Spline Flow(NSF)를 도입한다. NSF는 베이스 분포(표준 다변량 정규)에서 복잡한 목표 분포로 변환하는 가역적 매핑을 학습하며, 스플라인 기반의 단조성 보장을 통해 경계에서의 추정 편향을 최소화한다.
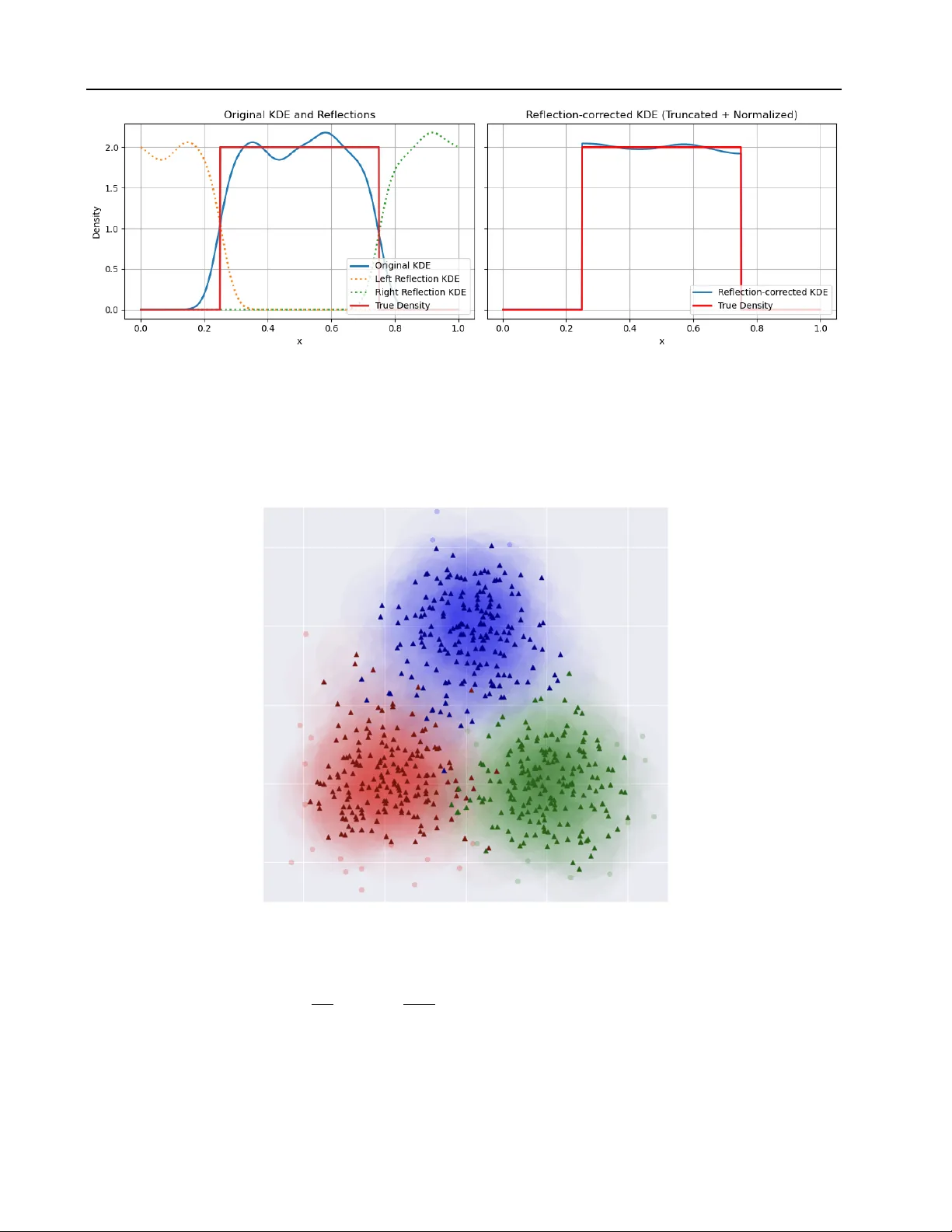
세 번째 단계는 지원 영역 추정이다. 밀도값이 일정 임계값 이하인 영역을 제외하거나, 복잡한 경우 샘플의 볼록 껍질을 사용해 지원을 근사한다. 경계가 직선인 경우 반사 기법을 적용해 경계 근처의 추정 오류를 보정한다.
네 번째 단계는 심볼릭 회귀이다. 비모수 추정기로부터 얻은 밀도값을 목표 변수로 삼아 PySR 엔진을 사용한다. 손실 함수는 MSE와 표현식 복잡도(트리 크기) 사이의 다목적 균형을 잡는다. 이를 통해 파레토 전선상의 여러 후보식을 제공하고, 사용자는 정확도와 해석 가능성 사이에서 원하는 모델을 선택할 수 있다. 또한, 최종 단계에서 “워밍 스타트” 재정제를 수행해 선택된 식을 미세 조정한다.
실험에서는 (1) 2차원 가우시안 혼합 모델, (2) 4차원 다변량 정규분포, (3) 고에너지 물리학에서 유도된 비대칭 피크와 레프터 분포 등 총 5개의 데이터셋을 사용했다. 클러스터링을 적용한 경우, 각 클러스터에 대해 독립적인 식을 찾은 뒤 합산했을 때 전체 MSE가 크게 감소했으며, 구조 학습을 적용한 경우 차원 축소 효과로 인해 복잡한 4차원 분포에서도 2차원 서브밀도에 대한 정확한 식을 복원했다. 특히, 비표준 지원을 갖는 물리학 분포에서는 지원 추정과 경계 반사 기법이 없을 때보다 정규화 오차가 30% 이상 감소했다.
비교 대상인 기존 방법으로는 MESSY(최대 엔트로피 기반)와 LLM‑SR(대규모 언어 모델 기반) 등을 들었으며, AI‑Kolmogorov은 보다 일반적인 함수 형태를 탐색할 수 있고, 고차원에서도 구조 학습을 통해 효율적으로 작동한다는 장점을 보였다.
결론적으로, AI‑Kolmogorov은 (1) 비모수 밀도 추정과 심볼릭 회귀를 연결하는 효과적인 브리지, (2) 클러스터링·구조 학습을 통한 문제 분해로 탐색 공간을 실질적으로 축소, (3) 정규화와 비음성 제약을 손실에 소프트하게 포함시켜 유효한 확률밀도식을 자동으로 도출한다는 점에서 기존 파라메트릭·비파라메트릭 접근법을 보완한다. 향후 연구에서는 더 복잡한 지원 형태와 대규모 실험 데이터에 대한 확장, 그리고 LLM과의 하이브리드 통합을 통한 사전 지식 활용이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기