음성 LLM 교차모달 온폴리시 증류 XOPD
X‑OPD는 음성 기반 대형 언어 모델이 텍스트 전용 LLM과 동일한 추론·지식 능력을 갖추도록, 학생 모델이 자체 생성한 음성‑텍스트 시퀀스를 텍스트 교사 모델이 토큰 수준에서 평가·피드백하는 온‑폴리시(distillation) 프레임워크이다. 다중 샘플 롤아웃과 인‑모달·크로스‑모달 어드밴티지 함수를 결합해 KL‑기반 정책 그래디언트를 최적화함으로써, 기존 SFT·RL 방식이 남긴 성능 격차를 크게 줄이고, 음성·텍스트 양쪽 모두에서 원본 …
저자: Di Cao, Dongjie Fu, Hai Yu
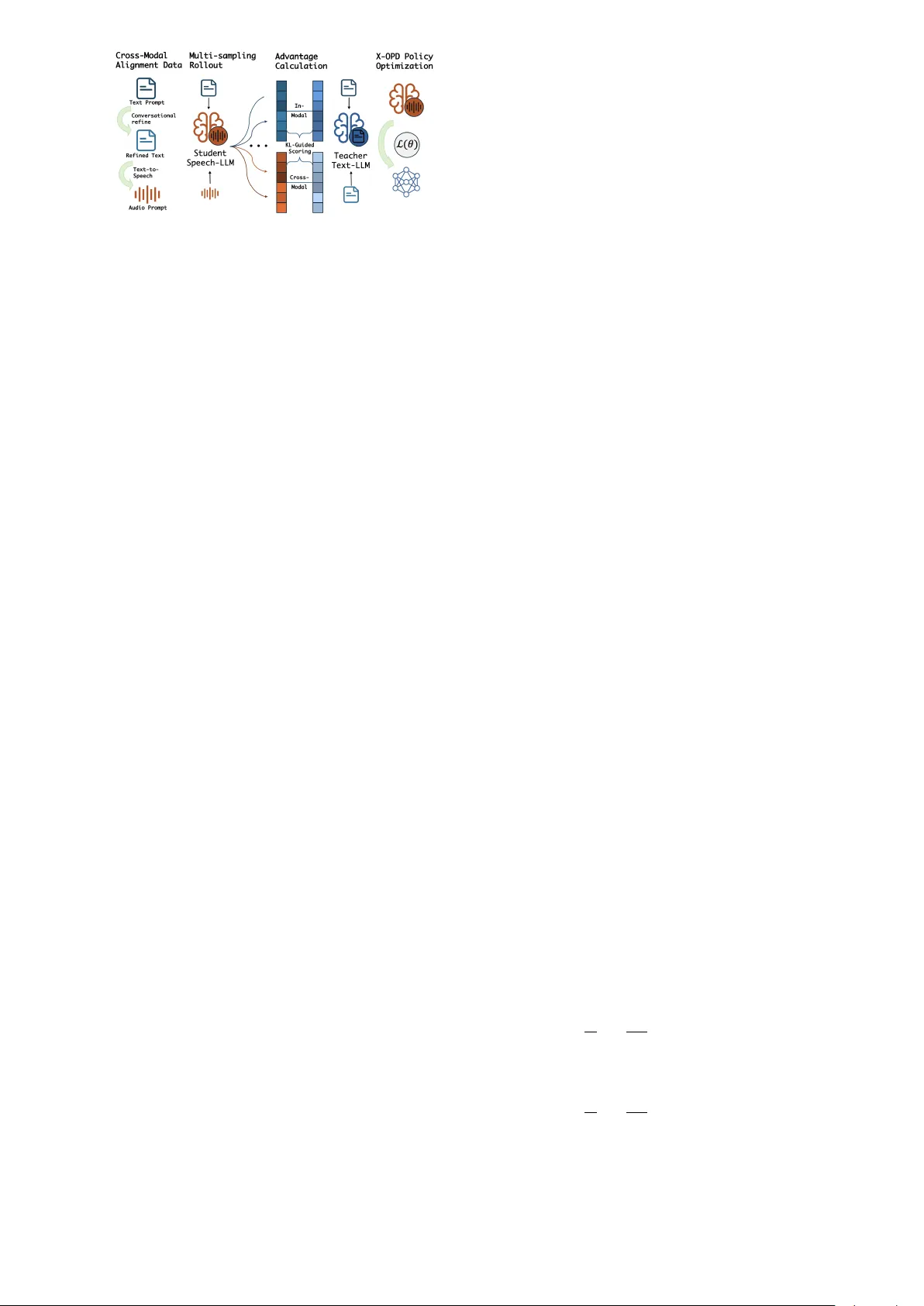
본 논문은 음성 기반 대형 언어 모델( Speech LLM )이 텍스트 전용 LLM에 비해 복잡한 추론·지식 질문에서 현저히 낮은 성능을 보이는 문제를 해결하고자 한다. 기존의 Supervised Fine‑Tuning(SFT)과 Reinforcement Learning(RL) 기반 파인튜닝은 고품질 텍스트 데이터와 음성‑텍스트 간의 모달리티 격차를 극복하지 못한다. 이를 극복하기 위해 저자들은 **X‑OPD(Cross‑Modal On‑Policy Distillation)** 라는 새로운 학습 프레임워크를 제안한다.
X‑OPD의 핵심 아이디어는 학생 모델(음성 LLM)이 현재 정책에 따라 스스로 음성 입력을 받아 토큰 시퀀스를 생성하고, 동일 텍스트 프롬프트를 입력받은 텍스트 교사 모델이 해당 시퀀스에 대한 확률 분포를 제공함으로써 토큰‑레벨 피드백을 주는 것이다. 이 과정은 **온‑폴리시** 방식으로, 모델이 실제 inference 시 겪는 분포와 동일한 데이터에서 학습한다는 점에서 기존 오프‑라인(distillation) 방식의 exposure bias 문제를 근본적으로 해결한다.
프레임워크는 두 가지 어드밴티지 함수를 도입한다. 첫 번째 **인‑모달 어드밴티지(A_im)** 는 텍스트 프롬프트만을 조건으로 교사와 학생의 로그 확률 차이를 측정해, 학생이 텍스트 기반 기본 능력을 유지하도록 돕는다. 두 번째 **크로스‑모달 어드밴티지(A_cm)** 은 교사는 텍스트 프롬프트, 학생은 실제 음성 입력을 조건으로 동일 토큰에 대한 로그 확률 차이를 계산한다. A_cm 은 음성 입력이 텍스트 논리와 얼마나 일치하는지를 직접적인 보상 신호로 제공한다.
두 어드밴티지는 각각 KL‑다이버전스 형태의 정책 그래디언트 손실 L_im, L_cm 으로 변환된다. 손실은 다중 롤아웃(각 프롬프트당 n=4)에서 샘플된 여러 경로에 대해 평균을 취해 분산을 감소시키고, 중요도 샘플링 비율 r_j,t(θ)=π_θ/π_old 로 현재 정책과 과거 정책 간의 차이를 보정한다. 최종 목표는 λ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기