RAG에서 환각 탐지를 위한 계층적 검증 기반 역형 테스트 프레임워크
RT4CHART는 생성된 답변을 독립적인 주장으로 분해하고, 겹치는 문맥 청크를 이용한 로컬 검증과 전체 문맥을 활용한 글로벌 검증을 계층적으로 수행한다. 각 주장에 ‘엔테일드·컨트라디드·베이스리스’ 라벨을 부여하고, 해당 라벨과 근거 문장을 함께 반환함으로써 미세한 환각을 증거 기반으로 진단한다. RAGTruth++와 새롭게 재주석된 RAGTruth‑Enhance 벤치마크에서 기존 방법 대비 답변‑레벨 F1 0.776(83% 향상) 및 스팬‑…
저자: Boxi Yu, Yuzhong Zhang, Liting Lin
**1. 연구 배경 및 문제 정의**
대형 언어 모델(LLM)을 검색된 문서와 결합한 Retrieval‑Augmented Generation(RAG) 방식은 파라미터 메모리에 의존하는 전통적인 생성 모델보다 최신 정보를 반영하고 사실성을 높일 수 있다는 장점이 있다. 그러나 실제 서비스 환경에서는 여전히 모델이 **문맥에 근거하지 않은 주장**을 생성하는 ‘환각(hallucination)’ 문제가 발생한다. 특히, 운영 환경에서는 **검색된 문서가 유일한 권위 있는 근거**가 되므로, 모델이 외부 지식에 의존해 답변을 만들 경우 사용자는 잘못된 정보를 받을 위험이 있다. 기존 환각 탐지기들은 전체 답변에 대한 점수만 제공하거나, 스팬 수준에서 문제 영역을 표시하지만, 해당 스팬이 왜 문제인지, 어떤 문맥 증거와 충돌하는지에 대한 설명을 제공하지 못한다. 이는 실무에서 ‘감사(audit)’가 어려운 원인이다.
**2. 핵심 아이디어 – 역형 테스트와 계층적 검증**
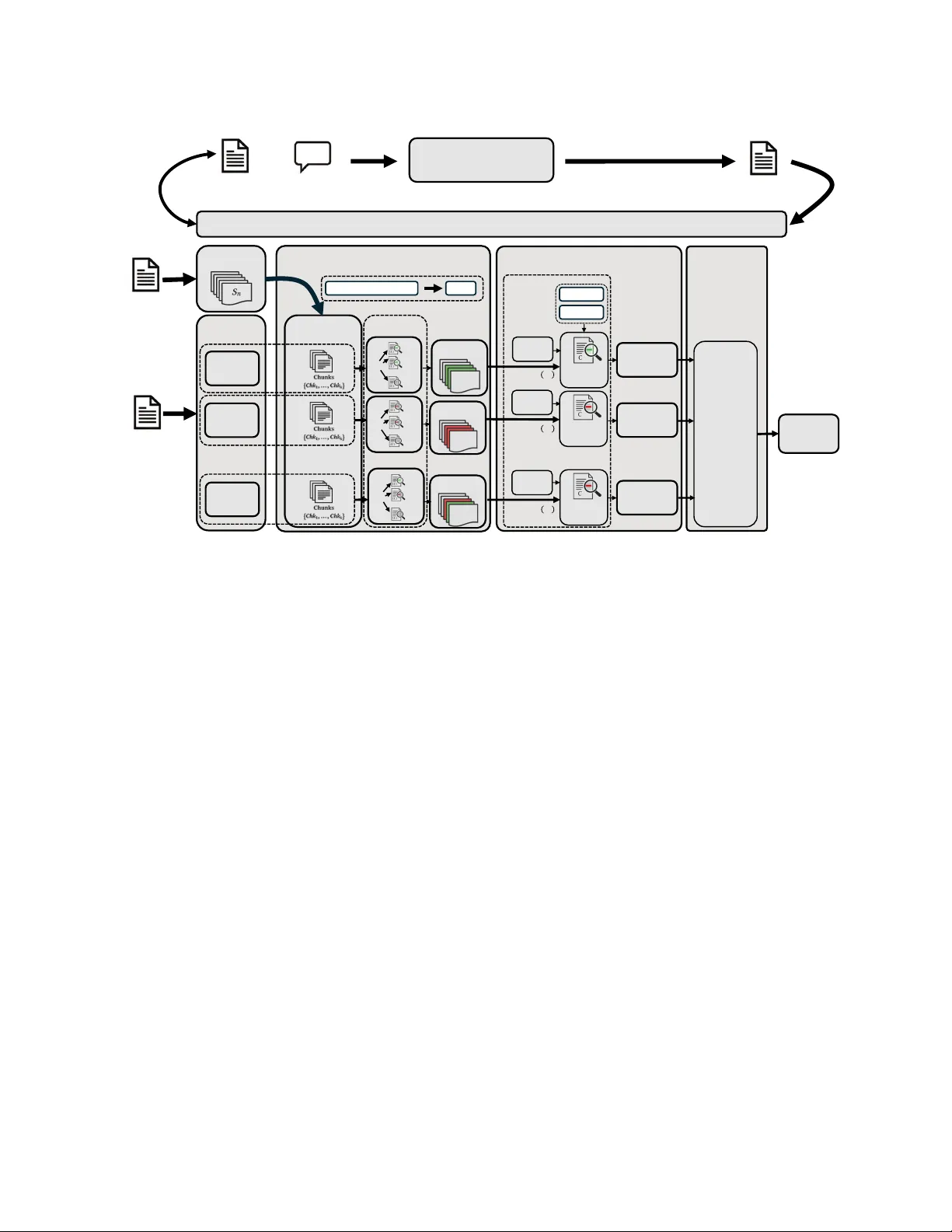
본 논문은 이러한 한계를 극복하기 위해 **역형 테스트(retromorphic testing)** 개념을 도입한다. 역형 테스트는 생성된 출력(A)을 다시 입력(문맥 C, 질문 Q)으로 매핑해, 출력이 원 입력에 의해 정당화될 수 있는지를 검증한다. 이를 위해 저자들은 **RT4CHART**라는 프레임워크를 설계했으며, 네 단계 파이프라인으로 구성한다.
- **주장 분해(Claim Decomposition)**: 답변 A를 의미적으로 독립적인 주장(Claim)들로 나눈다. 문장 단위로 분할한 뒤, LLM에게 각 문장을 여러 주제로 세분화하도록 요청한다. 이때 문맥 C는 제공하지 않아, 주장이 답변 자체에 기반하도록 한다.
- **로컬 검증(Local Verification)**: 문맥 C를 슬라이딩 윈도우(크기 W, 겹침 O)로 청크(Chunk)화한다. 각 주장에 대해 청크별 LLM 판정을 수행하고, ‘엔테일드(Entailed)’, ‘컨트라디드(Contradicted)’, ‘베이스리스(Baseless)’ 라벨을 부여한다. 청크별 결과는 OR‑join을 통해 하나의 로컬 라벨로 합산한다. 겹침을 두어 증거가 두 문장에 걸쳐 있을 경우에도 하나의 청크에서 포착할 수 있다.
- **글로벌 검증(Global Verification)**: 전체 문맥 C에 대해 다시 한 번 판단한다. 로컬 라벨을 힌트로 제공해, 로컬 단계에서 놓친 미세한 모순이나 추가 증거를 발견한다. 최종 주장 라벨은 로컬과 글로벌 결과를 AND‑join하여 결정한다; 즉, 하나라도 ‘컨트라디드’ 혹은 ‘베이스리스’가 있으면 해당 주장은 환각으로 간주한다.
- **답변‑레벨 집계(Answer‑Level Aggregation)**: 모든 주장 라벨을 종합해 답변 전체의 환각 여부를 출력한다. 동시에 각 주장 라벨과 **증거 스팬(Evidence Spans)**을 반환한다. 엔테일드 주장은 지원 증거, 컨트라디드 주장은 반증 증거, 베이스리스 주장은 증거 없음으로 표시한다.
**3. 데이터셋 구축 및 재주석**
기존 RAGTruth 벤치마크는 환각 라벨이 부족해 검증이 어려웠다. 이를 보완하기 위해 저자들은 두 가지 데이터셋을 사용한다.
- **RAGTruth++**: 기존 408 샘플을 두 명의 독립 어노테이터가 재검토해 환각 스팬을 86개 → 865개로 확대한 데이터.
- **RAGTruth‑Enhance**: 전체 RAGTruth 평가 셋(2,675 샘플)을 두 명이 재주석한 확장 버전. 재주석 결과 원래 라벨 대비 **1.68배** 많은 환각 사례가 발견돼, 기존 벤치마크가 환각을 크게 과소평가하고 있음을 입증한다.
**4. 실험 설정 및 결과**
RT4CHART와 기존 답변‑레벨, 스팬‑레벨 탐지기들을 동일한 설정으로 비교했다. 주요 지표는 **F1 점수**이며, 두 데이터셋 모두에서 RT4CHART가 최고 성능을 기록했다.
- **RAGTruth++**: 답변‑레벨 F1 0.776 (기존 최고 0.424 대비 83% 상대 향상)
- **RAGTruth‑Enhance**: 스팬‑레벨 F1 47.5% (기존 최고 40.5% 수준)
또한 **Ablation Study**를 통해 계층적 검증이 핵심임을 확인했다. 로컬 검증만 사용하거나 글로벌 검증만 사용할 경우 F1가 각각 0.62, 0.68로 크게 떨어졌다. 청크 크기(W)와 겹침(O) 파라미터도 성능에 민감하게 작용했으며, 적절한 값(예: W=4, O=2)이 최적 성능을 제공했다.
**5. 의의 및 한계**
RT4CHART는 **증거 기반 traceability**를 통해 RAG 시스템에서 발생하는 환각을 정량·정성적으로 파악한다. 이는 특히 법률, 의료, 금융 등 고신뢰성이 요구되는 도메인에서 모델 출력의 신뢰성을 검증하고, 문제 발생 시 빠르게 원인을 추적·수정할 수 있게 한다. 다만, 현재는 LLM을 검증 단계에 사용하기 때문에 검증 비용이 높으며, 청크 기반 로컬 검증이 문맥이 매우 길거나 복잡한 경우 여전히 놓칠 가능성이 있다. 향후 경량화된 검증 모델이나, 청크 선택을 동적으로 최적화하는 방법이 필요하다.
**6. 결론**
본 논문은 “역형 테스트 + 계층적 검증”이라는 새로운 프레임워크를 제시함으로써, RAG 환경에서의 환각 탐지를 **답변‑레벨 정확도와 스팬‑레벨 증거 제공** 두 축에서 크게 향상시켰다. 또한 재주석된 대규모 벤치마크를 공개해, 향후 연구자들이 보다 신뢰할 수 있는 평가 기반 위에서 새로운 탐지 기법을 개발할 수 있도록 기여한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기