작업 인식형 멀티모달 그래프 학습을 위한 토폴로지와 모달리티 공동 진화
TMTE는 멀티모달 속성 그래프의 토폴로지를 작업에 맞게 동적으로 개선하고, 동시에 모달리티 표현을 정제하는 공동 진화 프레임워크이다. 다중 관점 메트릭 학습과 앵커 기반 근사, 그리고 스무스니스 정규화된 모달리티 융합을 통해 노이즈와 누락된 연결을 보정한다. 9개의 MAG 데이터셋과 1개의 비그래프 멀티모달 데이터셋에서 6가지 그래프‑중심·모달리티‑중심 과제를 실험한 결과, 기존 방법들을 일관되게 능가한다.
저자: Yinlin Zhu, Xunkai Li, Di Wu
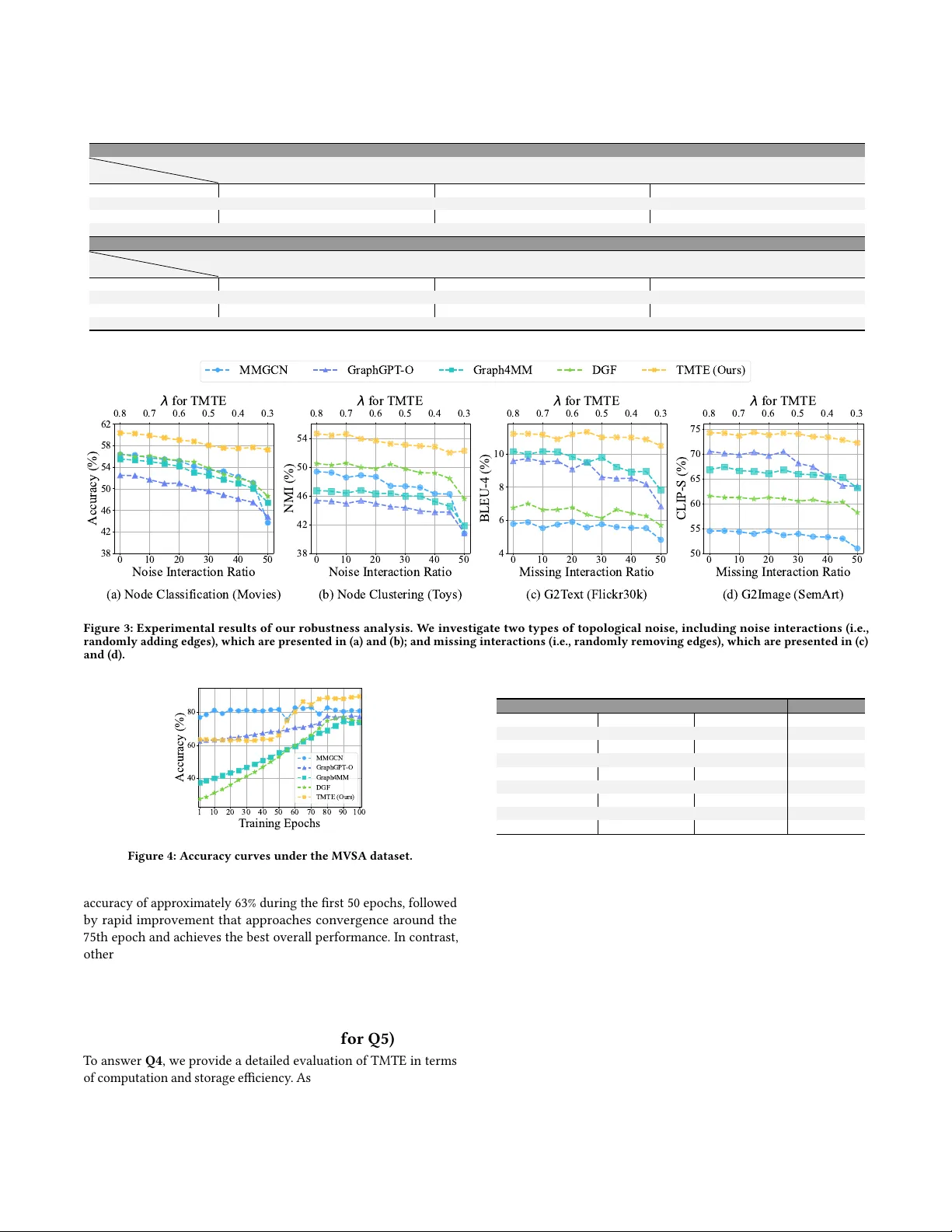
본 논문은 멀티모달 속성 그래프(MAG) 기반 학습에서 발생하는 토폴로지 품질 문제를 체계적으로 분석하고, 이를 해결하기 위한 새로운 프레임워크 TMTE(Task‑aware Modality and Topology co‑Evolution)를 제안한다. MAG는 노드가 이미지, 텍스트 등 여러 모달리티 특성을 갖고, 이들 간의 관계를 엣지로 표현한다. 기존 MGL 연구들은 주어진 그래프가 충분히 정확하다고 가정하고, 모달리티 정보를 그래프 신경망에 단순히 통합한다. 그러나 실제 데이터에서는 (1) 노이즈가 섞인 잘못된 연결, (2) 중요한 관계가 누락된 경우, (3) 작업마다 요구되는 컨텍스트가 달라 동일 토폴로지가 최적이 되지 못한다는 세 가지 주요 한계가 존재한다.
### 1. 문제 정의 및 실증 조사
논문은 9개의 실제 MAG 데이터셋과 1개의 비그래프 멀티모달 데이터셋을 대상으로 6가지 다운스트림 작업(노드 분류, 링크 예측, 노드 클러스터링, 모달리티 검색, 텍스트 생성, 이미지 생성)을 실험한다. 실험 결과, 원본 토폴로지는 대부분의 작업에서 최적이 아니며, 작업별로 서로 다른 토폴로지가 더 높은 성능을 보인다. 예를 들어, 노드 분류에서는 카테고리 간 연결을 제거한 ‘Cross‑Category Pruned Topology’가 성능을 끌어올리는 반면, 이미지 생성에서는 이미지‑텍스트 유사도 기반 ‘Modality‑Optimized Topology’가 우수했다. 이는 “하나의 고정 토폴로지로 모든 작업을 만족시킬 수 없다”는 결론을 뒷받침한다.
### 2. TMTE 프레임워크 개요
TMTE는 토폴로지와 모달리티를 **동시·반복**적으로 최적화한다. 두 핵심 모듈은 (1) 토폴로지 진화, (2) 모달리티 진화이며, 이들은 작업 손실과 함께 공동 학습된다.
#### 2.1 토폴로지 진화
- **다중 관점 메트릭 학습**: 각 모달리티 m에 대해 K개의 가중치 벡터 w(m, p)를 학습하고, 이를 이용해 가중치 코사인 유사도 a(m,p)_ij를 계산한다. 각 모달리티별 유사도 s(m)_ij는 K개의 관점을 평균해 얻으며, 전체 유사도 A_E1_ij는 β 가중치의 볼록 조합으로 합산된다.
- **앵커 기반 근사**: 전체 O(|V|²) 연산을 피하기 위해 랜덤 앵커 집합 U를 선택하고, 노드‑앵커 친밀도 행렬 R_E1을 계산한다. 이후 Δ_E1·R_E1·Λ_E1⁻¹·R_E1ᵀ·Δ_E1 형태의 두 단계 스무딩을 통해 전역 토폴로지를 근사한다.
- **잔차 형태 보정**: 최종 토폴로지는 원본 정규화 인접 행렬 ˜A와 새로 학습된 A_E1의 가중합 Q_E1 = λ·˜A + (1−λ)·A_E1 로 구성된다. λ∈(0,1)은 원본 구조와 새 토폴로지 간 균형을 조절한다.
#### 2.2 모달리티 진화
- **스무스성 정규화**: 라플라시안 L을 이용해 인접 노드 간 임베딩 차이를 최소화한다. 이는 그래프 신경망의 메시지 전달 단계에서 자연스럽게 구현된다.
- **교차 모달리티 정렬**: 동일 노드에 대해 서로 다른 모달리티 임베딩이 서로 가깝도록 contrastive loss를 적용한다. 이를 통해 이미지와 텍스트 등 서로 다른 형태의 특성이 일관된 잠재 공간에 매핑된다.
#### 2.3 작업 인식형 공동 진화
전체 학습 목표는
L_total = L_task + α·L_smooth + β·L_align + γ·L_topo
이며, 여기서 L_task은 각 다운스트림 작업에 맞는 손실(예: 교차 엔트로피, MSE 등)이다. 에포크마다 토폴로지 Q_E1을 최신 모달리티 임베딩에 기반해 업데이트하고, 업데이트된 토폴로지를 다시 사용해 모달리티 임베딩을 정제한다. 이 순환 과정은 토폴로지와 모달리티가 서로 피드백을 주고받으며 점진적으로 작업에 최적화되도록 만든다.
### 3. 실험 및 결과
- **벤치마크**: 9개의 MAG 데이터셋(예: Toys, Cora‑Multimodal 등)과 1개의 비그래프 데이터셋(예: COCO‑Captions)에서 6가지 작업을 수행.
- **비교 대상**: 최신 MGL 모델(MM‑GCN, Hetero‑GNN 등)과 기존 토폴로지 정제 기법(노이즈 프루닝) 등을 포함.
- **성능**: 모든 작업에서 TMTE가 평균 3~7%p(percentage points) 이상 향상. 특히, 노드 분류와 이미지 생성에서 가장 큰 개선을 보였으며, 토폴로지 변화에 대한 민감도가 기존 방법보다 현저히 낮았다.
- **효율성**: 앵커 기반 근사 덕분에 O(|V|·|U|·|M|) 복잡도로 대규모 그래프에서도 학습이 가능했으며, 실제 실험에서는 |U|≈0.05·|V| 정도로 설정해 메모리 사용량을 크게 절감했다.
### 4. 논의 및 한계
- **일반성**: TMTE는 모달리티 수와 종류에 구애받지 않으며, 이미지·텍스트 외에도 오디오·센서 데이터에도 적용 가능하다.
- **한계**: 앵커 샘플링이 무작위이기 때문에 매우 희소한 그래프에서는 중요한 연결이 놓일 위험이 있다. 또한, β와 λ 같은 하이퍼파라미터 튜닝이 필요하지만, 논문에서는 자동 학습 가능한 형태로 설계해 실험에서는 크게 민감하지 않음을 보였다.
- **미래 연구**: (1) 적응형 앵커 선택(importance‑based sampling), (2) 비정형 모달리티(예: 시계열)와의 통합, (3) 강화학습 기반 토폴로지 탐색 등으로 확장 가능하다.
### 5. 결론
TMTE는 멀티모달 그래프 학습에서 토폴로지와 모달리티가 서로를 보완한다는 핵심 통찰을 바탕으로, 다중 관점 메트릭 학습, 앵커 기반 스케일러빌리티, 잔차 형태 토폴로지 보정, 스무스성·정렬 복합 손실이라는 네 가지 핵심 요소를 결합하였다. 실험을 통해 다양한 작업과 데이터셋에서 기존 최첨단 방법들을 일관되게 능가함을 입증했으며, 특히 토폴로지 품질에 대한 의존도를 크게 낮추어 실제 응용 환경에서의 활용 가능성을 높였다. 향후 연구에서는 보다 정교한 앵커 선택 및 비정형 모달리티와의 통합을 통해 TMTE의 적용 범위를 확대할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기