훈련 없이도 가능한 의료 영상 소수샷 분할을 위한 RAP 프레임워크
RAP는 DINOv3와 SAM2를 결합해 지원 이미지 검색, 형태 적응, 그리고 구조‑인식 프롬프트 생성까지 전 과정을 훈련 없이 수행한다. 형태 적응 단계에서 방향성 챔퍼 매칭과 주파수 도메인 스타일 변환을 사용해 해부학적 구조를 정확히 정렬하고, Voronoi 기반 양·음성 포인트를 SAM2에 전달해 최종 마스크를 얻는다. 다중 의료 데이터셋에서 기존 소수샷 방법들을 능가하는 성능을 보인다.
저자: Zhihao Mao, Bangpu Chen
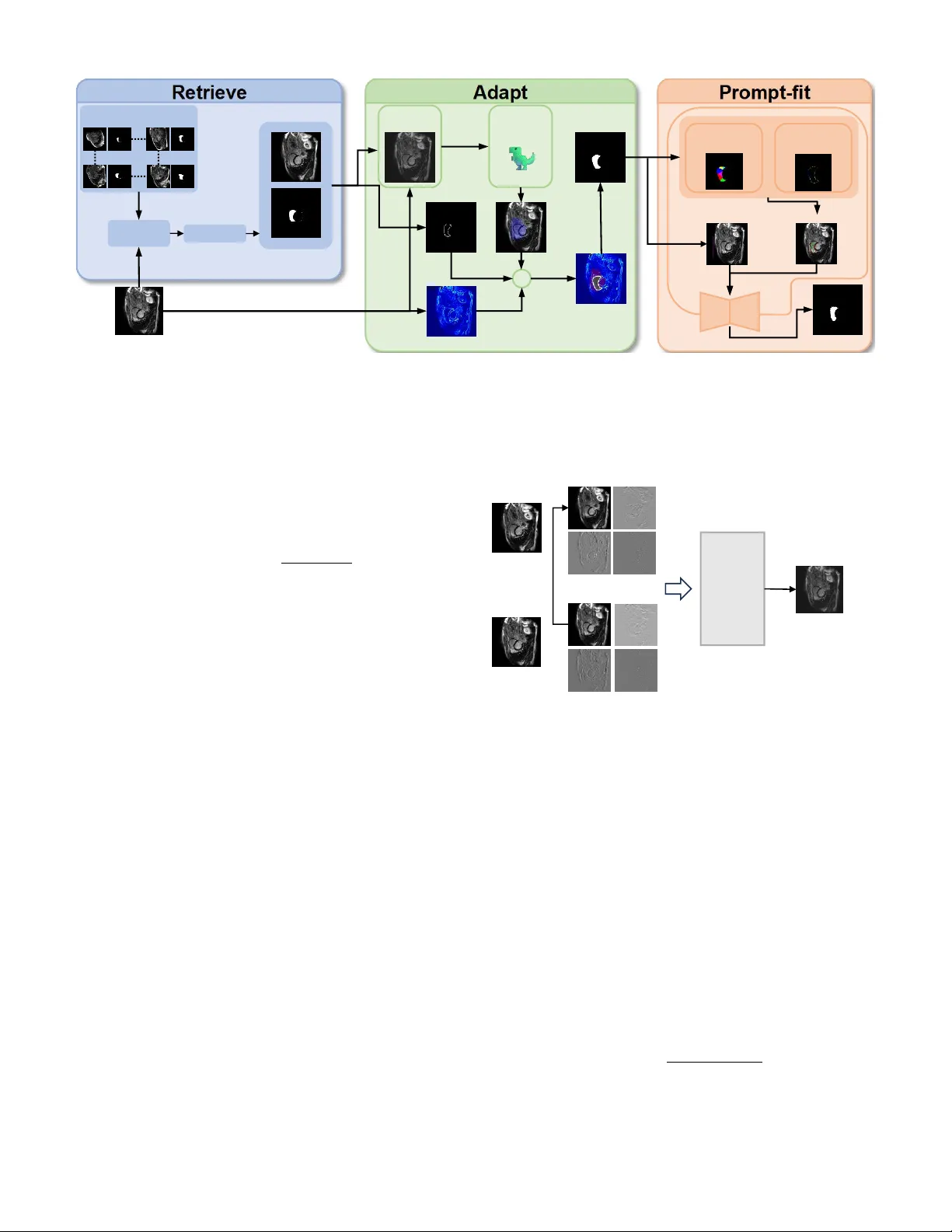
본 논문은 의료 영상에서 소수의 라벨만으로도 정확한 세그멘테이션을 수행할 수 있는 훈련‑프리 프레임워크 RAP(Retrieve‑Adapt‑Prompt‑Fit)를 제안한다. 기존 소수샷 의료 세그멘테이션 방법들은 주로 지원 이미지와 질의 이미지 사이의 의미적 유사성에 의존했으며, 해부학적 형태의 반복성을 충분히 활용하지 못했다. RAP는 이러한 한계를 극복하기 위해 두 가지 사전 학습된 foundation model, DINOv3와 SAM2를 핵심 구성 요소로 채택한다.
1️⃣ **Retrieve 단계**에서는 DINOv3‑ViT‑L/16을 이용해 지원 이미지와 질의 이미지 각각의 전역 특징 벡터를 추출한다. 특징은 전체 이미지 평균과 마스크 영역 마스크 평균을 각각 계산해 얻으며, 코사인 유사도 기반으로 데이터베이스에서 가장 유사한 지원 이미지를 검색한다. 여기서 저자들은 가장 높은 유사도(1위) 대신 두 번째 후보(2위)를 선택함으로써 동일 환자 내 자기 매칭을 방지하고, 다중 환자 데이터베이스에서 보다 일반화된 지원을 확보한다.
2️⃣ **Adapt 단계**는 세부적인 형태 적응을 담당한다. 먼저, 지원 이미지와 질의 이미지에 대해 이산 웨이브렛 변환(DWT)을 수행해 저주파(LL)와 고주파(LH, HL, HH) 서브밴드로 분해한다. 지원 이미지의 LL 서브밴드를 질의 이미지의 LL 서브밴드로 교체하고 역변환을 수행함으로써 전반적인 밝기·대비 차이를 보정한다(주파수‑도메인 스타일 변환).
다음으로, DINO 기반 의미 게이팅을 적용한다. 지원 마스크 내부 픽셀들의 DINO 특징을 K‑means(K≈8)로 클러스터링하고, 각 클러스터의 프로토타입과 질의 이미지의 특징 맵 간 코사인 유사도를 계산한다. 평균 유사도가 높은 상위 K′ 클러스터를 선택해 의미 게이팅 마스크 G를 만든다. 이 마스크는 형태 매칭 탐색을 G 내부로 제한해 불필요한 배경 매칭을 억제한다.
마지막으로, 방향성 챔퍼 매칭을 수행한다. 지원 마스크 경계에서 법선 방향을 추출하고, 질의 이미지의 에지 픽셀을 8개의 각도 구간으로 나눈 뒤 각 구간마다 거리 변환(DT_k)을 사전 계산한다. 변환 파라미터(이동 t_x, t_y, 스케일 s, 회전 r)를 최적화해 평균 방향성 챔퍼 거리 C를 최소화한다. 최적 변환을 적용해 얻은 마스크를 G와 교집합해 최종 예비 마스크 M_pre을 만든다.
3️⃣ **Prompt‑Fit 단계**에서는 M_pre을 SAM2에 입력할 프롬프트로 변환한다. 양성 프롬프트는 Voronoi 파티션을 기반으로 한다. M_pre 내부에서 Farthest Point Sampling(FPS)으로 N_v≈6개의 시드 포인트를 선택하고, 각 Voronoi 셀의 중심을 양성 포인트(P⁺)로 사용한다. 이는 SAM2가 객체 전체를 골고루 탐지하도록 돕는다. 음성 프롬프트는 M_pre 경계를 N_s≈8개의 각도 섹터로 나눈 뒤, 각 섹터 외부에서 DINO 유사도가 최소인 점을 선택해 음성 포인트(P⁻)로 만든다. 이렇게 배치된 음성 포인트는 경계 근처 배경을 명확히 구분하도록 SAM2에 신호를 제공한다. 또한, M_pre에서 추출한 바운딩 박스(B_box)를 추가 프롬프트로 제공해 SAM2의 관심 영역을 제한한다. 최종적으로 SAM2‑ViT‑H에 이미지와 (P⁺, P⁻, B_box)를 입력해 고품질 세그멘테이션 마스크 ˆM_q를 얻는다.
**실험 및 결과**
- 데이터셋: Abd‑MRI(4 장기), Abd‑CT(4 장기), Card‑MRI(3 심장 구조) 총 85명, 1‑way 1‑shot 설정.
- 평가 지표: Dice Similarity Coefficient(DSC).
- 비교 대상: PANet, SSL‑ALPNet, RPT, PATNet, IFA, FAMNet, MAUP 등 기존 소수샷 방법들.
- 주요 결과: RAP는 Abd‑MRI에서 평균 79.84% Dice, Abd‑CT에서 80.16% Dice를 기록, MAUP(78.16%, 78.25%)을 각각 1.68%p, 1.91%p 상회한다. 특히 간, 좌·우 신장, 비장 등 각각의 장기에서도 전반적으로 최고 성능을 달성했다.
**Ablation Study**
- 주파수‑스타일 변환 제거 → Dice 평균 2.3%p 감소.
- 의미 게이팅 제거 → 1.8%p 감소.
- 방향성 챔퍼 매칭 없이 단순 변환 → 3.1%p 감소.
- Voronoi 양성 포인트 대신 무작위 포인트 → 1.5%p 감소.
- 음성 포인트 없이 → 2.0%p 감소.
**장점 및 한계**
- 훈련 없이도 높은 성능을 달성해 라벨링 비용을 크게 절감한다.
- 해부학적 형태 정보를 명시적으로 활용해 도메인 간 일반화가 강력하다.
- 현재는 2‑D 슬라이스 기반이며, 3‑D 연속성 보장은 미흡하다.
- 지원 데이터베이스 규모와 품질에 민감하므로, 대규모 고품질 아카이브 구축이 필요하다.
**향후 연구**
- 다중 지원 샘플을 동시에 활용하는 집합 적합 알고리즘.
- 3‑D 볼륨 전체에 적용 가능한 연속형 형태 적응 및 프롬프트 생성.
- 다른 foundation model(SAM‑3, CLIP‑based)과의 연계 탐색.
본 논문은 “검색‑적응‑프롬프트”라는 삼단계 파이프라인을 통해, 사전 학습된 비지도 특징 추출기와 프롬프트 가능한 세그멘테이션 모델을 결합함으로써 의료 영상 소수샷 세그멘테이션 분야에 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기