강화학습으로 퀴즈 자동 구성 최적화
본 논문은 다중 선택형 문제(MCQ) 풀(pool)에서 교사의 주제·난이도 목표에 맞는 퀴즈를 자동으로 생성하기 위해 MDP를 정의하고, DQN, SARSA, A2C/A3C 세 가지 모델프리 강화학습 알고리즘을 적용한다. 합성·실제 데이터셋에서 실험한 결과, 모든 알고리즘이 빠르게 수렴하고 목표와 높은 유사도를 보이는 퀴즈를 찾아내며, 특히 DQN이 가장 높은 성능을 보였다. 또한 목표 분포가 편향된 경우에도 전이 학습이 가능함을 확인하였다.
저자: Ricardo Pedro Querido Andrade Silva, Nassim Bouarour, Dina Fettache
본 논문은 교사가 다중 선택형 문제(MCQ) 풀에서 원하는 주제와 난이도 분포를 만족하는 퀴즈를 설계하는 과정을 자동화하고자 한다. 이를 위해 저자들은 먼저 퀴즈를 크기 k인 MCQ 집합 Z 로 정의하고, 각 퀴즈에 대해 주제 비율 벡터와 난이도 비율 벡터를 계산한다. 교사가 원하는 목표는 두 개의 목표 벡터 TC(주제)와 TD(난이도)이며, 이와의 일치를 측정하기 위해 코사인 유사도를 사용한다. 최적화 문제는 주제 일치도와 난이도 일치도를 동시에 최대화하는 이중 목표 최적화(QuizComp)로 공식화된다.
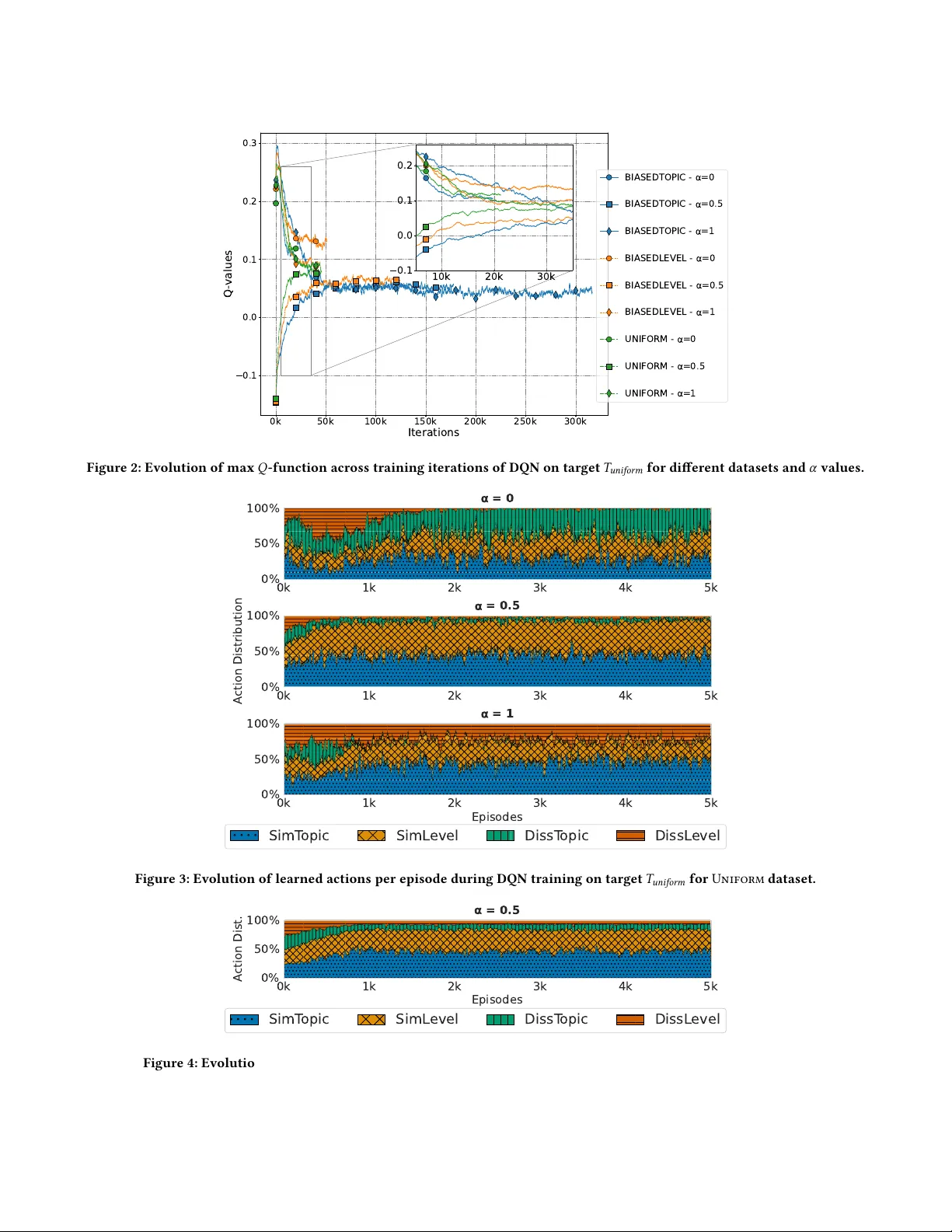
강화학습 접근을 위해 MDP를 설계한다. 상태 S는 현재 퀴즈 Z와 그에 대응하는 두 비율 벡터의 결합이며, 행동 A는 네 가지로 제한한다. ‘SimTopic’은 현재 퀴즈와 가장 주제 유사도가 높은 후보 퀴즈를 하나 교체하고, ‘SimLevel’은 난이도 유사도가 높은 후보를 교체한다. 반대로 ‘DissTopic’과 ‘DissLevel’은 각각 가장 비유사한 후보를 교체한다. 이러한 행동 정의는 전체 조합 공간(수천만 개) 대신 사전 계산된 25개의 가장 유사·비유사 퀴즈만을 고려함으로써 탐색 효율성을 크게 높인다.
보상은 목표와 현재 퀴즈 사이의 차이를 ΔtargetMatch 형태로 정의한다. 목표와의 유사도가 향상되면 양의 보상, 악화되면 음의 보상을 주어 에이전트가 목표에 수렴하도록 유도한다. 보상은 가중치 α∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기