언어와 시각 정렬을 위한 강화학습 기반 선호 최적화 LVRPO
LVRPO는 그룹 상대 정책 최적화(GRPO)를 활용해 언어‑시각 모델의 행동을 직접 정렬하는 프레임워크이다. 기존의 특징 수준 정렬 대신, 시각·언어 일관성을 평가하는 다중 차원 보상을 정의하고, 이를 그룹 샘플링과 상대적 어드밴티지 계산에 적용한다. 결과적으로 이해와 생성 양쪽 작업에서 기존 통합 모델을 능가하며, 특히 세밀한 의미 연결과 제어 가능한 이미지 편집에서 큰 향상을 보인다.
저자: Shentong Mo, Sukmin Yun
본 논문은 언어와 시각을 하나의 트랜스포머 백본에 통합한 최신 멀티모달 사전학습 모델이 직면한 핵심 문제를 진단하고, 이를 해결하기 위한 새로운 프레임워크 LVRPO(Language‑Visual Reinforcement‑based Preference Optimization)를 제안한다. 기존 연구는 크게 두 갈래로 나뉜다. 첫 번째는 BAGEL·Emu3와 같이 대규모 토큰 예측을 통해 암묵적으로 정렬을 기대하는 방식이며, 두 번째는 REP‑A·VILA‑U와 같이 사전 학습된 시각 교사의 특징을 손실 함수로 직접 모방하는 정렬 방식이다. 전자는 정교한 의미 연결이 부족해 복잡한 지시를 따르지 못하고, 후자는 시각 교사의 판별적 편향이 생성 작업에 맞지 않아 “시소 효과”를 일으킨다.
LVRPO는 이러한 한계를 극복하기 위해 모델을 “정책”으로 보고, 행동 수준에서 직접 정렬한다. 구체적인 절차는 다음과 같다. (1) 프롬프트 q에 대해 현재 정책 πθ가 G개의 독립적인 출력을 샘플링한다. 출력은 텍스트, 이미지 토큰, 혹은 이미지 편집 결과 등 다양하다. (2) 각 출력 o_i에 대해 다중 차원 보상 r_i를 계산한다. 보상은 크게 세 부분으로 구성된다. 첫 번째는 SigLIP‑2 인코더가 제공하는 시맨틱 임베딩 Φsig와 Ψsig 사이의 코사인 유사도(semantic grounding)이며, 이는 이미지와 텍스트 간 의미적 일치를 정량화한다. 두 번째는 규칙 기반 논리 제약 I(rules)으로, 이미지 해상도, 객체 개수, 텍스트 포맷 등 검증 가능한 제약을 만족하는지를 0/1으로 판단한다. 세 번째는 VQA 프록시(PaLI‑3 등)를 이용한 지식 일관성 검증으로, 프롬프트에 포함된 사실적 속성이 시각 결과와 일치하는지를 확률적으로 평가한다. 또한, 키워드‑패치 매핑을 강화하기 위해 dense grounding reward r_dense를 도입해, 프롬프트 내 각 키워드가 이미지의 특정 패치와 최대 코사인 유사도를 갖도록 유도한다.
보상이 정의되면, 그룹 내 상대 어드밴티지를 ˆA_i = (r_i – μ)/σ 로 계산한다. 여기서 μ와 σ는 그룹 전체 보상의 평균·표준편차이며, 이를 통해 개별 샘플이 전체 대비 얼마나 우수한지를 정량화한다. 이후 GRPO(Group Relative Policy Optimization) 방식을 적용해, 별도의 가치 네트워크 없이 정책 그라디언트를 ∇θJ = Σ_i ˆA_i ∇θ log πθ(o_i|q) – β ∇θ KL(πθ‖π_ref) 로 업데이트한다. KL‑제약은 초기 베이스라인 정책(예: BAGEL)과의 거리를 제한해 학습 안정성을 보장한다.
이론적 분석에서는 (1) GRPO 업데이트가 기대 보상의 하한을 최대화함을 보이고, (2) 그룹 평균을 베이스라인으로 사용함으로써 공통 노이즈를 억제하고 의미적 차이에 집중한다는 점을 증명한다. 또한, 다중 차원 보상이 서로 보완적으로 작용해, 단일 손실(예: MSE)보다 더 풍부한 신호를 제공함을 논증한다.
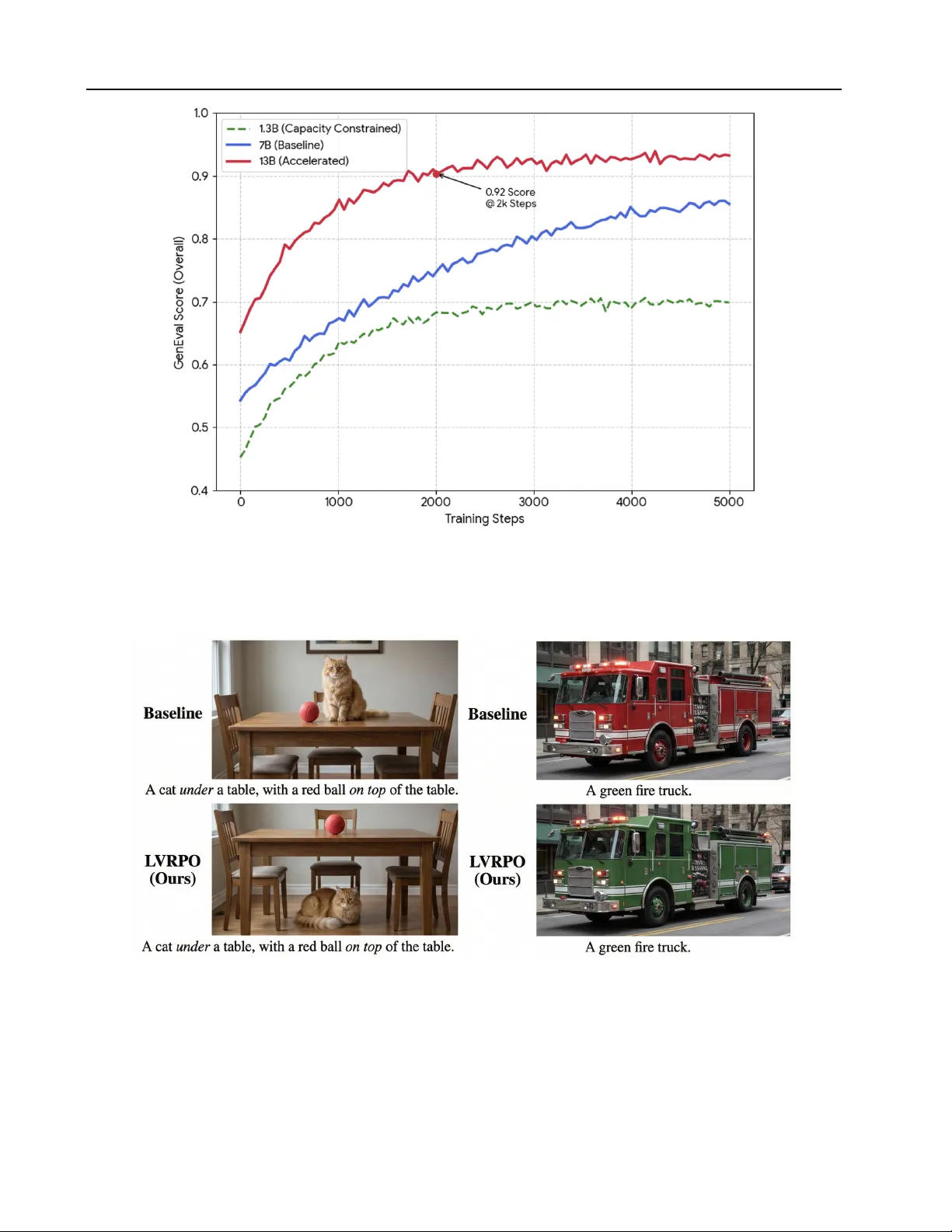
실험에서는 LVRPO를 BAGEL을 초기화 모델로 사용해 다양한 베치와 프롬프트에서 학습시켰다. 평가 벤치마크는 크게 세 영역으로 구분된다. (i) 멀티모달 이해: VQA, WISE 등에서 기존 통합 모델 대비 3~5%p 상승. (ii) 텍스트‑투‑이미지 생성: GenEval에서 색상·위치·속성 제어 정확도가 0.87~0.96 수준으로, 가장 높은 점수를 기록한 모델을 앞섰다. (iii) 이미지 편집·추론: GEdit‑Bench과 Intelligent‑Bench에서 복합 지시(예: “빨간 자동차를 파란 자동차로 바꾸고, 배경을 흐리게”)를 수행할 때, 논리 제약 만족도와 시맨틱 일치도가 크게 개선되었다. 특히, “blue car” 대신 “red car”을 생성하는 오류가 크게 감소했으며, 이는 보상 설계가 “통계적으로 그럴듯하지만 의미적으로 틀린” 출력을 효과적으로 억제함을 보여준다.
전체적으로 LVRPO는 (1) 정적 특징 정렬이 아닌 행동 기반 정렬, (2) 그룹 상대 정책을 통한 효율적 강화학습, (3) 시맨틱·논리·지식 세 축을 아우르는 보상 설계라는 세 가지 핵심 혁신을 통해 통합 멀티모달 모델이 이해와 생성 양쪽에서 일관된 고성능을 달성하도록 만든다. 이는 차세대 멀티모달 파운데이션 모델이 “언어와 시각을 진정으로 하나의 체계로 결합”할 수 있는 실용적인 로드맵을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기