프라이버시 보호 연속 개인화와 프로토타입 정렬 연합 소프트프롬프트
ProtoFed‑SP는 고정된 추천 백본에 두 가지 시간 스케일(단기·장기)의 소프트프롬프트를 삽입하고, 서버‑측에 유지되는 소규모 프로토타입 라이브러리와 연합 차등프라이버시(DP) 방식으로 지속적으로 동기화한다. 단기 프롬프트는 세션 의도를 빠르게 반영하도록 희소화하고, 장기 프롬프트는 프로토타입에 정렬돼 장기 선호를 안정적으로 보존한다. 실험 8개 벤치마크에서 NDCG@10 +2.9%, HR@10 +2.0%의 전반적 향상을 보이며, 특히 A…
저자: Canran Xiao, Liwei Hou
**1. 연구 배경 및 문제 정의**
웹 서비스는 사용자 선호와 아이템 공급, 플랫폼 정책이 지속적으로 변하는 비정상(non‑stationary) 환경에 놓여 있다. 이런 상황에서 모델은 새로운 신호를 빠르게 흡수하면서도 과거의 장기 선호를 잊지 않아야 하는 안정성‑가소성 딜레마에 직면한다. 동시에 개인정보 보호와 통신 비용 제약으로 인해 온‑디바이스 적응과 차등프라이버시(DP) 기반 연합 학습이 필수적이다. 기존 연구는 (① 전역 손실 기반 적응, ② 원시 데이터·그라디언트 전송, ③ 프롬프트 기반 적응이지만 전역·단일 시간 스케일) 등에서 한계가 있었다.
**2. 핵심 아이디어 – ProtoFed‑SP**
ProtoFed‑SP는 세 가지 핵심 요소로 구성된다.
- **이중 시간 스케일 소프트프롬프트**: 각 클라이언트 u는 장기 프롬프트 p_longᵤ와 단기 프롬프트 p_shortᵤ,ₜ을 유지한다. 장기 프롬프트는 느린 업데이트(예: 매 에포크마다)로 장기 선호를 저장하고, 단기 프롬프트는 세션마다 ℓ₁ 정규화와 proximal soft‑thresholding을 적용해 희소하게 빠르게 변한다.
- **프로토타입 라이브러리와 정렬**: 서버는 K개의 프로토타입 c_k (벡터 형태) 를 보관한다. 장기 프롬프트는 인코더 φ를 통해 임베딩 zᵤ=φ(p_longᵤ) 로 변환되고, Bregman 다이버전스 + InfoNCE 손실 A(zᵤ, C) 로 가장 가까운 프로토타입에 끌어당겨진다. 이는 장기 메모리가 인구 전체의 의미적 구조에 고정점(anchor)으로 묶이게 해, 급격한 드리프트에 대한 과잉 적응을 방지한다.
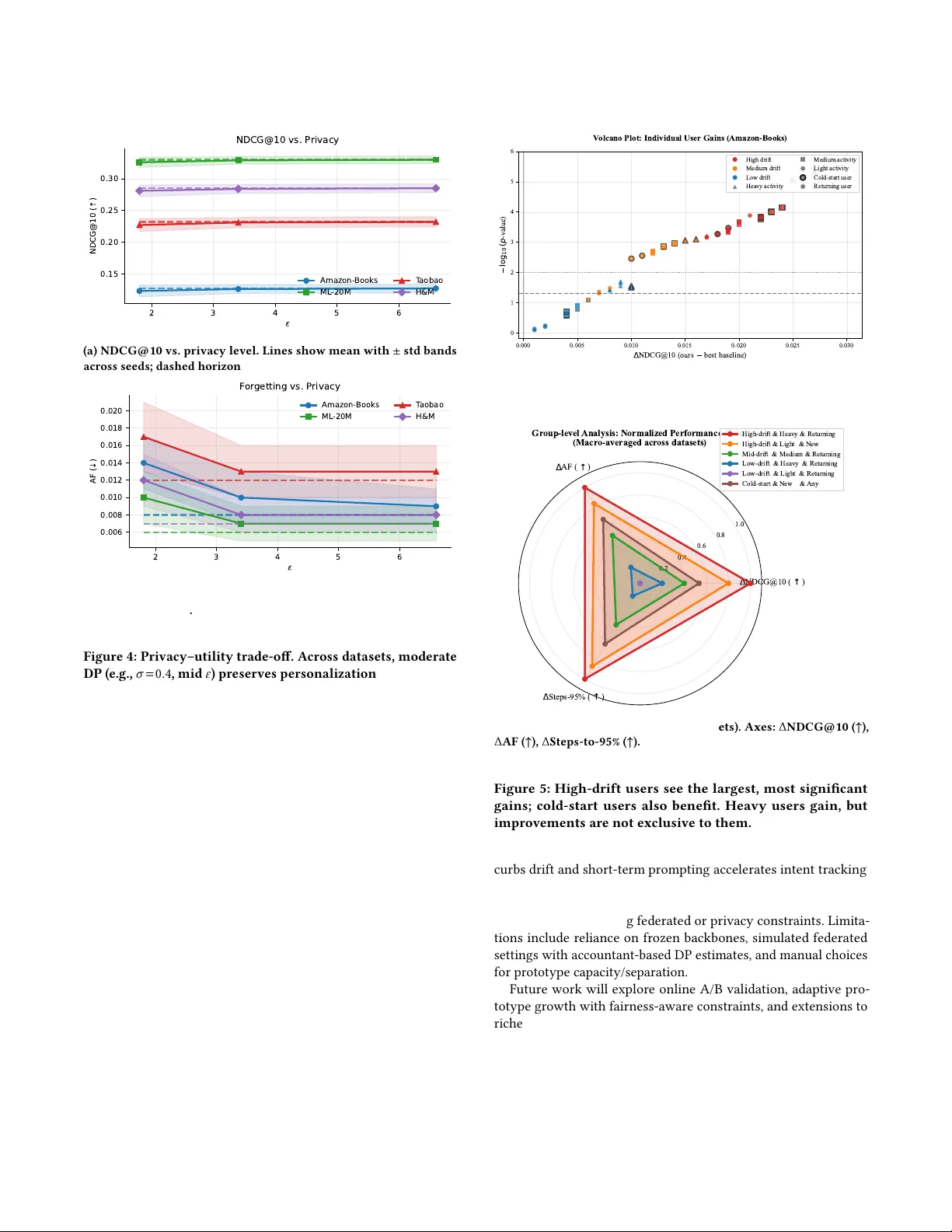
- **연합 차등프라이버시 기반 프로토타입 업데이트**: 클라이언트는 압축된 zᵤ에 클리핑 및 가우시안 노이즈를 추가해 서버에 전송한다. 서버는 DP‑FedKMeans, DP‑Geometric Median, 혹은 DP‑Wasserstein Barycenter 등으로 프로토타입을 갱신한다. 프로토타입 간 최소 거리 ρ 제약과 활용도 기반 프루닝을 통해 프로토타입 붕괴를 방지한다.
**3. 쿼리 라우팅 및 프롬프트 합성**
사용자 쿼리 qᵤ,ₜ는 쿼리 인코더 g 로 임베딩 hᵤ,ₜ 를 만든다. 내적 유사도 s_k=⟨hᵤ,ₜ, φ(c_k)⟩/τ 로 Top‑M 프로토타입을 선택하고, softmax 가중치 w_k 로 정규화한다. 최종 프롬프트는
\tilde pᵤ,ₜ = p_longᵤ + αᵤ,ₜ p_shortᵤ,ₜ + Σ_{k∈Top‑M} w_k c_k
이며, αᵤ,ₜ=σ(aᵀΔᵤ,ₜ) 로 세션 드리프트 Δᵤ,ₜ(예: 최근 쿼리 임베딩 차이) 를 기반해 가소성을 동적으로 조절한다.
**4. 학습 목표**
추천 손실은 점별 BCE 혹은 쌍별 BPR 형태이며, 전체 목표는
J = E_{u,t}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기