증거 우선 오디오 이해 EvA 모델과 데이터셋
본 논문은 대형 오디오 언어 모델(LALM)이 복잡한 음향 장면에서 증거를 충분히 보존하지 못하는 ‘증거 병목(evidence bottleneck)’ 문제를 제시하고, Whisper와 CED‑Base를 비압축 방식으로 시간 정렬하여 결합한 이중 경로 구조인 EvA를 제안한다. 또한 54 K개의 이벤트 순서 캡션과 500 K개의 QA 쌍을 포함하는 대규모 오픈소스 학습 데이터셋 EvA‑Perception을 구축하여, 제로샷 평가에서 기존 오픈소스…
저자: Xinyuan Xie, Shunian Chen, Zhiheng Liu
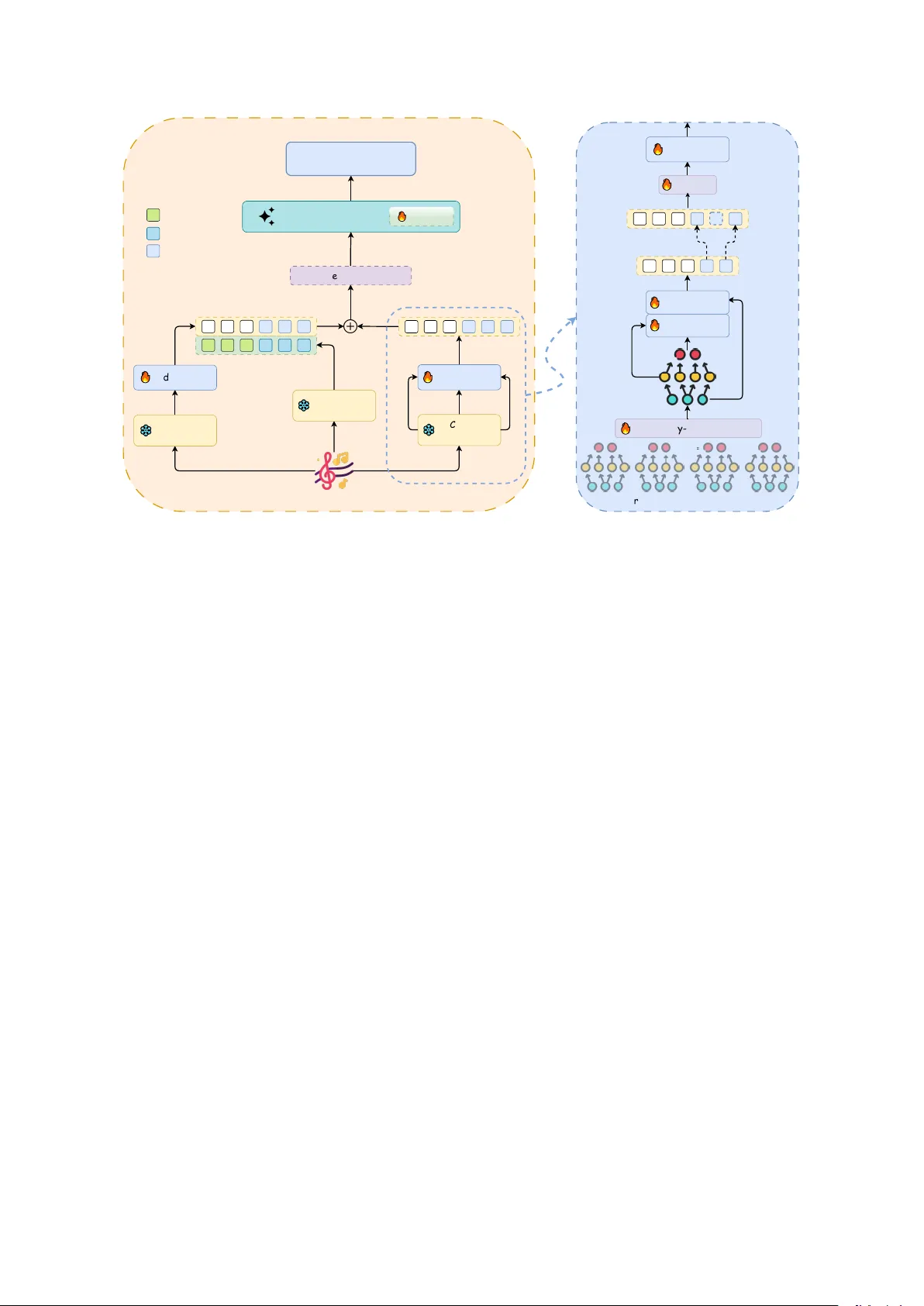
본 논문은 대형 오디오 언어 모델(LALM)이 복잡한 음향 환경에서 인간 수준의 이해에 미치지 못하는 원인을 ‘증거 병목(evidence bottleneck)’이라는 개념으로 규명한다. 기존 최첨단 모델(Qwen2.5‑Omni, Kimi‑Audio 등)은 음성 인식에 특화된 Whisper 인코더를 단일 경로로 사용하거나, 이중 경로 구조를 채택하더라도 Q‑Former와 같은 압축형 융합 모듈을 사용해 시간 정렬이 부정확하거나 정보가 손실되는 문제가 있다. 저자는 데이터 처리 불등식(DPI)을 활용해, 인코더‑프론트엔드에서 손실된 음향 증거는 이후 단계(프롬프트 튜닝, 정책 최적화)로 복구될 수 없으며, 따라서 모델 성능 향상의 핵심은 ‘전방 인코더에서 증거를 충분히 보존하는 것’이라고 주장한다.
이를 해결하기 위해 제안된 EvA(Evidence‑First Audio) 아키텍처는 두 개의 상보적 인코더를 병렬로 배치한다. 첫 번째는 Whisper(E_W)로, 대규모 ASR 데이터로 사전 학습돼 음성의 언어적 정보를 고품질로 추출한다. 두 번째는 CED‑Base(E_C)로, Vision Transformer 기반의 일반 오디오 이벤트 인식 모델이며, 비음성 이벤트(배경 소리, 음악, 전이음 등)를 포착한다. CED‑Base는 중간 레이어(4, 8, L)의 출력을 모두 활용해 다중 스케일 증거를 수집한다.
증거 집계 단계에서는 먼저 각 레이어의 주파수 차원을 가중 풀링(gated attention)하여 시간 축만 남긴 1D 시퀀스를 만든다. 이후 두 단계의 교차‑어텐션을 적용해 고수준 의미(H_L)와 중간 수준(H_8), 저수준(H_4) 특성을 순차적으로 결합한다. 이 과정을 통해 다중 주파수·다중 깊이 정보를 보존한 H_agg를 얻는다.
다음으로, Whisper와 CED‑Base 사이의 시간 불일치를 해결하기 위해 선형 보간(time‑aware linear interpolation)을 사용한다. Whisper 토큰은 80 ms 스트라이드, CED‑Base는 160 ms 스트라이드를 갖기 때문에, CED 특성을 Whisper 타임라인에 맞춰 업샘플링한다. 정렬된 CED 특성(H_aligned)은 각각 경량 프로젝션(ProJ_W, ProJ_C)을 거쳐 LLM 차원으로 변환된다. 최종 결합은 간단한 가중 덧셈 방식으로 이루어지며, α라는 학습 가능한 스칼라 게이트가 비음성 증거의 기여도를 조절한다. 이 방식은 시퀀스 길이를 유지하고, 기존 LLM(예: LLaMA‑2‑7B 기반) 구조를 변경하지 않으며, 초기 학습 단계에서 기존 언어 지식을 크게 교란하지 않는다.
데이터 측면에서는 기존 오디오 캡션 데이터가 시간 순서와 세밀한 음향 디테일을 제공하지 못한다는 한계를 지적한다. 이를 보완하기 위해 EvA‑Perception이라는 대규모 오픈소스 데이터셋을 구축한다. AudioSet‑Strong의 시간 라벨을 기반으로 Gemini‑2.5‑Pro가 이벤트 순서 캡션을 생성하고, Whisper가 음성 전사를, OpenMu가 음악 정보를, Qwen‑2.5‑VL‑72B가 시각적 힌트를, QwQ‑32B가 최종 통합 캡션을 만든다. 결과적으로 54 K개의 이벤트 순서 캡션(총 150 h)과 500 K개의 QA 쌍을 확보한다.
실험은 통합 제로샷 프로토콜을 적용해 MMAU, MMAR, MMSU, CochlScene 네 가지 벤치마크에서 평가한다. EvA는 오픈소스 모델 중 가장 높은 인지(perception) 점수를 기록했으며, 특히 인지 중심 서브셋에서 인간과의 격차를 크게 줄였다. Kimi‑Audio‑7B 대비 모든 메트릭에서 개선을 보였고, 특히 MMSU에서 인지 점수가 42.8 %에서 81.1 %로 38.3 포인트 상승했다. Ablation 실험에서는 (1) CED 중간 레이어 집계 제거, (2) 시간 정렬 없이 단순 concat, (3) 가중 게이트 없이 무조건 합산했을 때 각각 성능이 감소함을 확인했다. 이는 제안된 두 단계 비압축 융합과 증거 집계가 핵심임을 증명한다.
결론적으로, EvA는 ‘전방 인코더 강화’와 ‘시간 정렬 비압축 융합’이라는 두 설계 원칙을 통해 증거 병목을 해소하고, 복잡한 음향 장면에서 인간 수준에 가까운 이해를 달성한다. 향후 연구는 더 큰 규모의 멀티모달 데이터와 실시간 스트리밍 환경에 대한 적용, 그리고 증거 보존을 위한 새로운 인코더 구조 탐색을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기