OpenFOAM HPC 챌린지 첫 번째 대회 성과와 인사이트
본 논문은 OpenFOAM HPC Challenge(OHC‑1)에서 수집된 237개의 실험 데이터를 바탕으로, 최신 CPU·GPU 시스템에서의 시간‑대‑에너지 효율을 평가한다. 하드웨어 트랙은 25종 CPU와 256노드(32 768코어)까지 확장된 스케일링을 분석했으며, HBM 탑재 CPU가 단일노드 성능을 주도한다는 결론을 도출했다. 소프트웨어 트랙은 GPU 포팅·메모리 최적화 등 맞춤형 솔버 개선을 통해 최대 28 % 에너지 절감, 72 %…
저자: Sergey Lesnik, Gregor Olenik, Mark Wassermann
본 논문은 OpenFOAM HPC Technical Committee(HPCTC)이 주관한 첫 번째 OpenFOAM HPC Challenge(OHC‑1)의 전 과정을 상세히 기술한다. 목표는 최신 생산용 HPC 하드웨어에서 OpenFOAM®의 계산 성능을 스냅샷 형태로 수집하고, 하드웨어 기반 성능과 소프트웨어 최적화가 미치는 영향을 비교·분석하는 것이다. 이를 위해 참가자들은 공통 CFD 사례인 open‑closed cooling DrivAer(occDrivAer) 구성을 사용하였다. 이 사례는 자동차 외부 유동을 다루는 RANS 시뮬레이션으로, SIMPLE 알고리즘과 k‑ω SST 난류 모델을 적용했으며, 65 M, 110 M, 236 M 셀의 세 가지 메쉬 해상도를 제공한다.
챌린지는 두 트랙으로 나뉜다. ‘Hardware Track’은 공식 OpenFOAM v2412와 기본 설정만을 사용하도록 제한했으며, CPU 종류·코어 수·노드 수만 자유롭게 선택하도록 했다. ‘Software Track’은 솔버 수정, 분할 전략, GPU·FPGA 가속 등 맞춤형 최적화를 허용했지만, 물리 모델과 메쉬는 동일하게 유지해야 했다. 제출물은 총 237건(하드웨어 175건, 소프트웨어 62건)으로, 12개 기관(학계·산업·연구소)에서 제공하였다.
평가 지표는 Time‑to‑Solution(TTS), Energy‑to‑Solution(ETS), Pre‑processing Time, Time‑per‑Iteration(TPI), Energy‑per‑Iteration(EPI), FV OPS(셀·반복 횟수 ÷ 시간) 및 FV OPS per Energy 등이다. ETS는 직접 전력 측정이 불가능한 경우 CPU/GPU의 TDP를 이용해 추정했으며, 이는 오차를 내포한다. 소프트웨어 트랙 제출물은 C_d, C_l, C_s와 같은 힘 계수의 평균·표준오차를 통해 정확성을 검증했으며, 2σ(µ) < 0.0015 조건을 만족해야 했다.
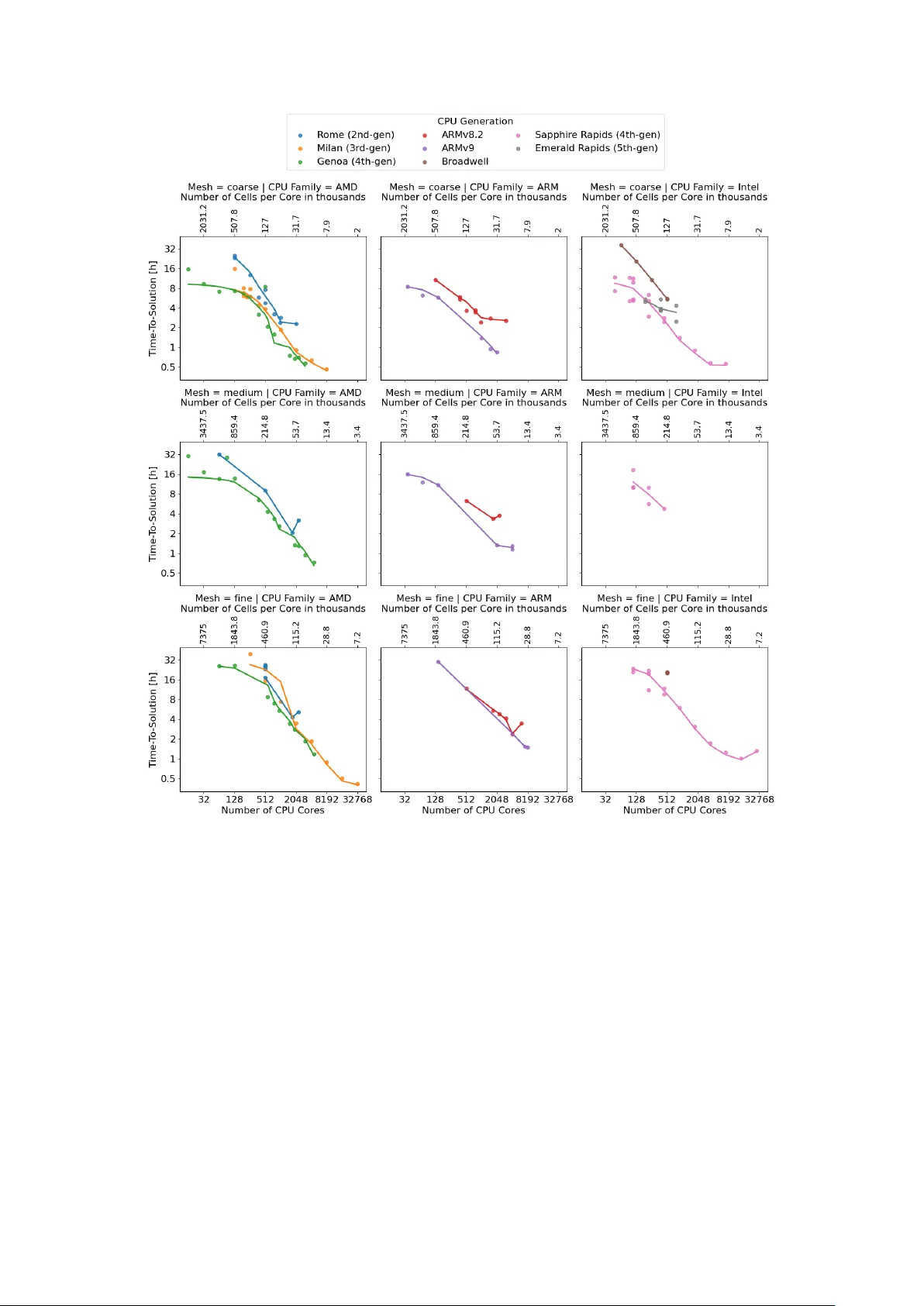
하드웨어 트랙 분석에서는 25종의 CPU(AMD, Intel, ARM)와 최대 256노드(32 768코어)까지 확장된 스케일링 결과가 제시되었다. TTS는 7.8 분에서 65.7 시간까지, ETS는 2.1 kWh에서 236.9 kWh까지 다양했다. 에너지‑시간 트레이드오프를 시각화한 Pareto front는 ‘Efficient’, ‘Fast’, ‘Balanced’ 세 영역을 구분한다. 특히 최신 HBM(High‑Bandwidth Memory)을 탑재한 CPU(예: AMD MI300, Intel Xeon Scalable 3세대)는 단일노드에서 메모리 대역폭이 제한적인 기존 CPU 대비 1.8‑2.2배 높은 FV OPS를 기록했으며, 이는 메모리‑바운드 CFD 워크로드에서 HBM이 핵심 성능 요인임을 입증한다.
강한 스케일링(Strong Scaling) 분석에서는 두 가지 제한 요인이 확인되었다. 첫째, 단일노드 내에서는 코어 수가 증가함에 따라 메모리 버스 경쟁이 심화되어 코어당 처리량이 포화된다. 둘째, 다노드 환경에서는 MPI 기반 통신 오버헤드가 도메인 분할의 표면‑대‑부피 비율에 비례해 급증한다. 실험 데이터는 약 10 000 셀/코어 이하에서 통신 비용이 지배적이며, 이를 초과하면 계산 효율이 급감한다는 ‘멀티노드 스케일링 한계’를 제시한다.
소프트웨어 트랙에서는 GPU 포팅, 혼합 정밀도 연산, 선형 솔버 전처리 개선, 메모리 접근 최적화 등이 주요 전략으로 나타났다. 전체 GPU 포팅(주로 NVIDIA A100·H100) 사례는 동일 노드당 FV OPS를 평균 17 % 상승시켰으며, 에너지당 FV OPS는 28 % 개선되었다. 특히 ‘Selective‑Memory’ 기법은 메모리 복제와 페이지 매핑을 최소화해 반복당 에너지를 28 % 절감했고, 혼합 정밀도 적용은 반복당 시간을 72 % 단축시켰다. 이러한 최적화에도 불구하고, 모든 소프트웨어 트랙 결과는 앞서 정의한 힘 계수 정확도 기준을 만족하였다.
결론적으로, OHC‑1은 OpenFOAM 기반 CFD 워크로드가 최신 HPC 시스템에서 메모리 대역폭(HBM)과 통신 토폴로지에 크게 의존한다는 사실을 정량화하였다. 또한, 소프트웨어 레벨에서 GPU 가속·메모리 최적화·혼합 정밀도 적용이 에너지 효율과 실행 시간 모두에서 현저한 개선을 제공한다는 점을 입증했다. 향후 챌린지는 더 다양한 물리 모델(비정상 흐름, 다물리 결합)과 실시간 전력 측정 인프라를 도입해 에너지 효율성을 보다 정확히 평가하고, 자동화된 최적화 파이프라인을 구축하는 것을 목표로 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기