FlowRL: 확산 정책을 위한 통합 분류와 모듈형 프레임워크
본 논문은 강화학습에서 확산·플로우 모델을 정책으로 활용하기 위한 체계적인 분류 체계와 JAX 기반 고성능 모듈형 구현체를 제시한다. 가이드 메커니즘과 기준 정책(Reference Policy)을 축으로 4가지 주요 접근법(BoN 샘플링, Q‑값 가이드, 재파라미터화, 가중 매칭)을 정리하고, 세 가지 연속 제어 벤치마크(Gym‑Locomotion, DeepMind Control, IsaacLab)에서 광범위한 실험을 수행해 알고리즘 선택 가이…
저자: Chenxiao Gao, Edward Chen, Tianyi Chen
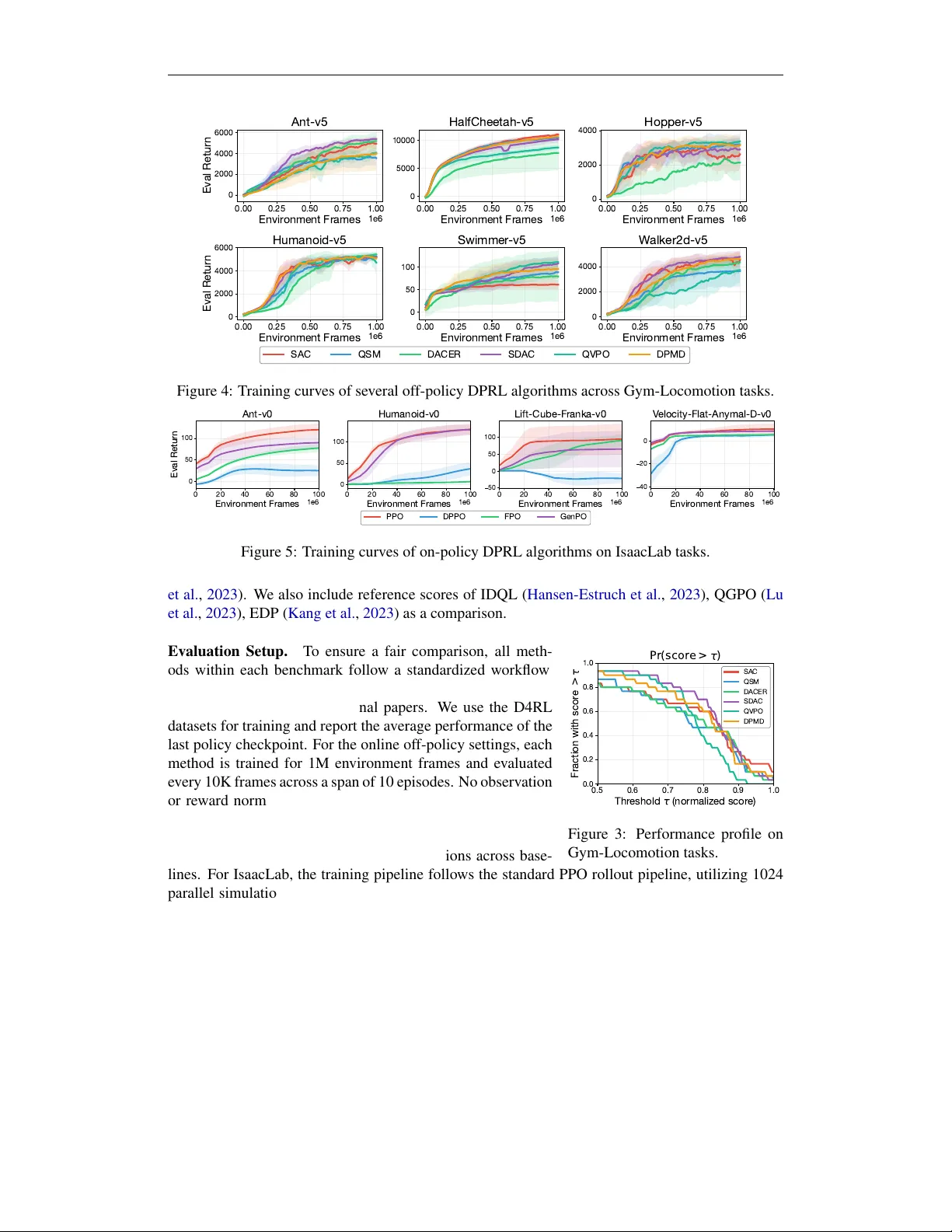
본 논문은 강화학습(RL)에서 확산 모델(DM)과 흐름 모델(FM)을 정책 표현으로 활용하려는 최근 연구 흐름을 체계적으로 정리하고, 이를 실험적으로 검증하기 위한 모듈형 프레임워크와 벤치마크를 제시한다.
1. **배경 및 동기**
전통적인 RL은 대각 가우시안이나 Dirac 델타와 같은 단순 확률분포를 정책으로 사용한다. 이러한 분포는 로그‑확률 계산이 용이하고 샘플링·재파라미터화가 간단해 다양한 정책 최적화 기법에 적합하지만, 고차원 연속 제어에서 나타나는 다중모달 행동 분포를 충분히 표현하지 못한다. 최근 확산·플로우 모델은 노이즈를 단계적으로 주입하고 역방향으로 제거하는 과정을 통해 복잡한 분포를 모델링할 수 있어, 정책 표현에 유망한 대안으로 떠오르고 있다. 그러나 확산 정책은 로그‑확률을 직접 구하기 어려워 기존 정책 그라디언트(Policy Gradient)나 재파라미터화 기반 방법을 그대로 적용하기 힘들다.
2. **통합 분류 체계**
저자들은 RL 목표식 (3) → π∗(a|s) ∝ ν(a|s) exp(Q(s,a)/λ) 를 출발점으로, 두 축을 중심으로 기존 방법을 분류한다.
- **가이드 메커니즘**: (i) Best‑of‑N(BoN) 샘플링, (ii) Q‑값 가이드, (iii) 재파라미터화, (iv) 가중 매칭.
- **기준 정책 ν**: (a) Uniform(A) → Maximum Entropy RL, (b) 이전 정책 πₖ₋₁ → Policy Mirror Descent, (c) 데이터셋 행동 정책 π_D → Offline RL.
표 1은 각 알고리즘을 위 두 축에 매핑해 보여준다. 예를 들어, BoN + π_D는 IDQL·SfBC, Q‑값 가이드 + Uniform은 QSM·iDEM·DPS, 재파라미터화 + Uniform은 D‑ACER·DACERv2·DIME, 가중 매칭 + Uniform은 SD‑AC·MaxEntDP·QVPO 등이다.
3. **기술적 핵심**
- **Q‑값 가이드**: 클래스‑조건부 가이드와 유사하게 ∇ₐQ(s,a) 를 스코어에 직접 주입한다. 하지만 중간 단계 t에서의 정확한 스코어는 (12)와 같이 복합적인 형태를 가지며, 직접 주입 시 편향이 발생한다. 이를 보정하기 위해 iDEM·DPS는 중요도 샘플링을 이용해 Monte‑Carlo 방식으로 중간 스코어를 추정한다.
- **재파라미터화**: BPTT를 통해 전체 확산 과정을 미분하지만 메모리·연산 비용이 크다. BDPO는 단계별 가치 함수 Q(s,a,t) 를 도입해 단일 스텝 최적화로 전환하고, EDP는 posterior mean ˆa₀을 이용해 근사 목표를 만든다. FQL은 다단계 확산을 단일 스텝 모델로 증류(distillation)한다.
- **가중 매칭**: 손실에 exp(Q/λ) 가중치를 곱해 정책 개선을 지도 학습 형태로 재구성한다. 식 (16)은 제안된 가중 매칭 손실이며, ν가 π_D 혹은 πₖ₋₁일 때 각각 QIPO·DPMD·FPMD가 해당 프레임워크에 해당한다. 이 접근법은 이론적으로 최적 정책이 (4)와 일치함을 증명한다.
4. **모듈형 구현**
JAX와 JIT 컴파일을 활용해 고성능·고확장성 코드를 제공한다. 핵심 설계는 (a) 환경 인터페이스, (b) 정책·가치 네트워크 모듈, (c) 가이드·정규화 전략 플러그인, (d) 학습 루프와 로그·시각화 도구로 구성된다. 연구자는 설정 파일만 바꾸면 BoN, Q‑값 가이드, 재파라미터화, 가중 매칭 중 원하는 조합을 손쉽게 실험할 수 있다.
5. **대규모 벤치마크**
세 가지 연속 제어 스위트(Gym‑Locomotion, DeepMind Control, IsaacLab)에서 12가지 알고리즘을 동일한 하이퍼파라미터와 평가 프로토콜로 비교했다. 주요 결과는 다음과 같다.
- **성능**: 가중 매칭 기반 오프라인 알고리즘(QIPO, DPMD 등)이 가장 일관된 높은 점수를 기록했으며, 특히 데이터 효율성이 뛰어났다.
- **샘플 효율**: Q‑값 가이드가 온라인 설정에서 빠른 수렴을 보였지만, 스코어 혼합 오류로 인해 최고 성능에 도달하는 데 한계가 있었다.
- **추론 비용**: BoN은 N개의 샘플을 평가해 최적 행동을 선택하므로 추론 시간이 크게 늘어나지만, 최고 성능을 원할 때는 유용했다.
- **메모리·연산**: 재파라미터화 방식은 BPTT 대비 메모리 사용량이 크게 감소했으며, JIT 최적화 덕분에 전체 학습 속도가 기존 구현 대비 2~3배 빨라졌다.
6. **실무 가이드**
논문은 적용 시나리오별 권고사항을 제시한다.
- **오프라인 RL**: 데이터가 풍부하고 실시간 제약이 없는 경우, 가중 매칭(QIPO, DPMD) 혹은 BoN을 선택한다.
- **온라인/실시간 제어**: 추론 지연을 최소화해야 하면 Q‑값 가이드(iDEM, DPS) 혹은 재파라미터화(D‑QL, BDPO) 중 메모리·연산 효율이 높은 방법을 채택한다.
- **탐색‑활용 균형**: Maximum Entropy가 필요하면 Uniform 기반 가이드(예: QSM, SD‑AC)를, 정책 안정성이 중요한 경우 Mirror Descent 기반(πₖ₋₁) 방법을 사용한다.
7. **결론 및 향후 연구**
FlowRL은 확산·플로우 정책을 RL에 적용하는 다양한 방법을 하나의 수학적 틀로 통합하고, 고성능 모듈형 구현과 광범위한 벤치마크를 제공함으로써 연구·산업 현장에서의 채택 장벽을 크게 낮춘다. 향후 연구는 (i) 다중 목표(멀티‑오브젝티브)와 메타‑러닝을 결합한 확산 정책, (ii) 하드웨어 가속기(GPU/TPU) 친화적인 샘플링 스케줄 최적화, (iii) 안전·신뢰성을 위한 KL‑제약의 정량적 분석 등에 초점을 맞출 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기