생성은 압축이다 확률적 직선 흐름을 통한 제로샷 비디오 코딩
기존 생성형 비디오 압축 방식과 달리, 사전 학습된 비디오 생성 모델 자체를 코덱으로 변환하는 제로샷 프레임워크 GVC를 제안한다. 결정론적 직선 흐름 ODE를 확률적 미분방정식(SDE)으로 변환해 코드북 기반 압축을 가능하게 하고, 세 가지 조건화 전략(I2V, T2V, FLF2V)을 통해 초저비트레이트에서도 고품질 복원을 달성한다.
저자: Ziyue Zeng, Xun Su, Haoyuan Liu
"Generation Is Compression: Zero-Shot Video Coding via Stochastic Rectified Flow" 논문은 초저비트레이트 비디오 압축의 근본적 한계에 대한 새로운 해법을 제시한다. 기존 하이브리드 방식은 전통적 코덱이 압축 표현을 생성한 후 생성 모델을 후처리기로 활용하는 반면, 본 연구에서 제안하는 Generative Video Codec(GVC)는 사전 학습된 비디오 생성 모델 자체를 코덱으로 삼는다. 전송되는 비트스트림은 생성적 디코딩 궤적을 직접 지정하며, 모델 재학습이 전혀 필요 없는 제로샷 프레임워크이다.
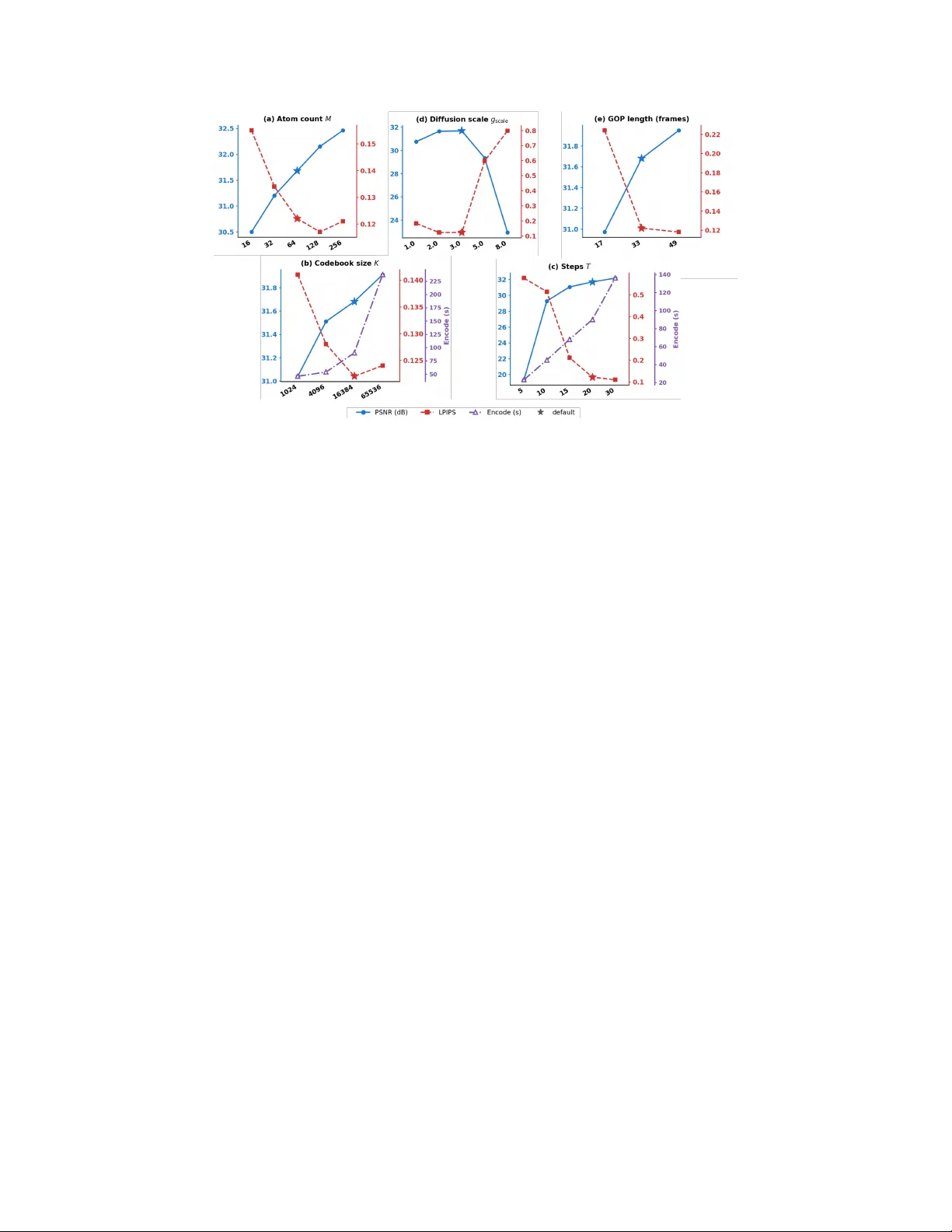
이를 구현하기 위한 첫 번째 기술적 장애는 최신 비디오 생성 모델(예: Wan 2.1)이 결정론적 직선 흐름(Rectified Flow) ODE를 기반으로 한다는 점이다. 이는 코드북으로 대체할 수 있는 단계별 확률적 노이즈 주입점이 없음을 의미한다. 저자들은 Score-SDE 이론을 활용해 추론 시 이 ODE를 등가의 SDE로 변환한다. 이 변환을 통해 각 디노이징 단계에 통제 가능한 확률성(확산 계수 g_t)을 도입하고, 이 지점에 재현 가능한 코드북 원자(atom)를 주입하여 정보를 압축한다. 코드북은 결정론적 시드로 생성되므로, 인코더와 디코더가 선택한 원자의 인덱스와 부호만 공유하면 동일한 생성 궤적을 재현할 수 있다.
이 통일된 SDE-코드북 백본 위에, 저자들은 서로 다른 압축 목표에 맞춘 세 가지 조건화 전략을 구체화한다. 1) Text-to-Video (T2V): 참조 프레임을 전송하지 않고, 비트스트림 전체가 코드북 인덱스로만 구성된다. 이는 생성 모델의 사전 지식만으로 복원이 가능한 최소 비트레이트의 하한선을 보여주는 '순수 생성 사전' 모드이다. 2) Image-to-Video (I2V): GOP의 첫 프레임을 무료 참조(I-프레임)로 사용하고, 이후 GOP는 이전 GOP의 복원된 마지막 프레임을 참조로 재사용하는 자동회귀적 체인을 형성한다. 오류 누적을 방지하기 위해, 시간적으로 먼 꼬리 프레임에 더 많은 코드북 원자를 할당하는 '적응형 꼬리 프레임 원자 할당'과 마지막 잠재 프레임에 대한 경량 잔차를 전송하는 '꼬리 잔차 보정' 기법을 도입한다. 3) First-Last-Frame-to-Video (FLF2V): 각 GOP의 첫 번째와 마지막 프레임을 모두 앵커로 사용하여 생성 궤적을 양쪽 끝에서 제약한다. 더 나아가, 한 GOP의 마지막 프레임이 다음 GOP의 첫 프레임으로 재사용되는 '경계 공유 GOP 연쇄' 방식을 도입하여 앵커 프레임의 오버헤드를 약 50% 절감하면서도 시퀀스 연결부의 매끄러운 연속성을 보장한다.
실험 결과, GVC는 UVG 등의 표준 벤치마크에서 0.002 bpp 미만의 초저비트레이트에서도 DCVC-RT나 GNVC-VD 같은 기존 방법 대비 월등한 perceptual 품질(낮은 LPIPS, 높은 사용자 선호도)을 보여준다. 특히 단일 하이퍼파라미터(g_scale)를 조정함으로써 넓은 범위의 비트레이트에 유연하게 대응할 수 있음을 입증하였다. 이 연구는 비디오 압축 패러다임을 '재구성'에서 '제어된 생성'으로 전환하는 중요한 이정표이며, 강력한 생성 모델을 다양한 멀티미디어 응용 분야에 활용할 수 있는 새로운 길을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기