혼합형 시계열 준우도 모델로 보는 코로나19 바이럴로드와 사망률 동역학
본 연구는 코로나19 바이럴로드(Ct값)와 사망자 수를 동시에 분석하기 위해 평균·분산만 지정하면 되는 혼합형 시계열 준우도(MixTSQL) 모델을 제안한다. 모델의 일관성·점근정규성을 증명하고, 평균·분산 모두에 대한 그랜저 인과관계 검정을 가능하게 한다. 실제 São Paulo 주의 주간 데이터에 적용해 바이럴로드가 사망률을 선행한다는 결과와, 기존 가우시안 VAR 대비 예측 정확도가 향상됨을 확인하였다.
저자: Kejin Wu, Raanju R. Sundararajan, Michel F. C. Haddad
본 논문은 코로나19 팬데믹 동안 바이럴로드(CT값)와 사망자 수라는 서로 다른 데이터 유형을 동시에 분석하기 위한 통계적 프레임워크를 제시한다. 기존 역학 연구에서는 보고된 확진자 수나 입원자 수와 같은 지표를 사용했지만, 이러한 지표는 보고 지연, 선택 편향, 미확인 감염 등으로 인해 신뢰도가 낮다. 반면, 역전사 정량 PCR(RT‑qPCR)에서 얻어지는 CT값은 바이러스 양을 직접적으로 반영하는 바이럴로드의 대리변수로서, 전염성 및 질병 진행 상황을 실시간으로 파악할 수 있는 장점이 있다. 그러나 CT값은 연속형이면서 0과 1 사이에 제한된 구간에 존재하고, 사망자 수는 비음이항 혹은 포아송 형태의 이산형 카운트 데이터이므로, 두 변수를 동시에 다룰 수 있는 모델이 필요했다.
이를 해결하기 위해 저자들은 ‘Mixed Time Series Quasi‑Likelihood (MixTSQL)’ 모델을 고안하였다. MixTSQL은 quasi‑likelihood(Q‑likelihood) 접근법을 기반으로 하며, 각 시계열에 대해 평균 μₜ와 분산 V(μₜ)만을 지정하면 된다. 구체적으로 Y₁ₜ(바이럴로드)와 Y₂ₜ(사망자 수)가 과거 정보 Fₜ₋₁에 조건부 독립이라고 가정하고, 각각 QL(μ₁ₜ,ϕ₁)와 QL(μ₂ₜ,ϕ₂) 분포를 따른다. 평균 구조는 일반적인 선형 예측식으로, 자기회귀와 교차회귀 항을 포함한다. 예를 들어, μ₁ₜ = β₁₀ + Σβ₁ᵢ·Y₁ₜ₋ᵢ + Σγ₁ⱼ·Y₂ₜ₋ⱼ와 같은 형태이며, μ₂ₜ도 동일하게 정의된다. 분산 함수 V(·)는 데이터 특성에 맞게 자유롭게 선택할 수 있어, 연속형 제한 구간 데이터에 적합한 베타‑형 분산이나 카운트 데이터에 적합한 포아송·음이항 분산 등을 적용할 수 있다.
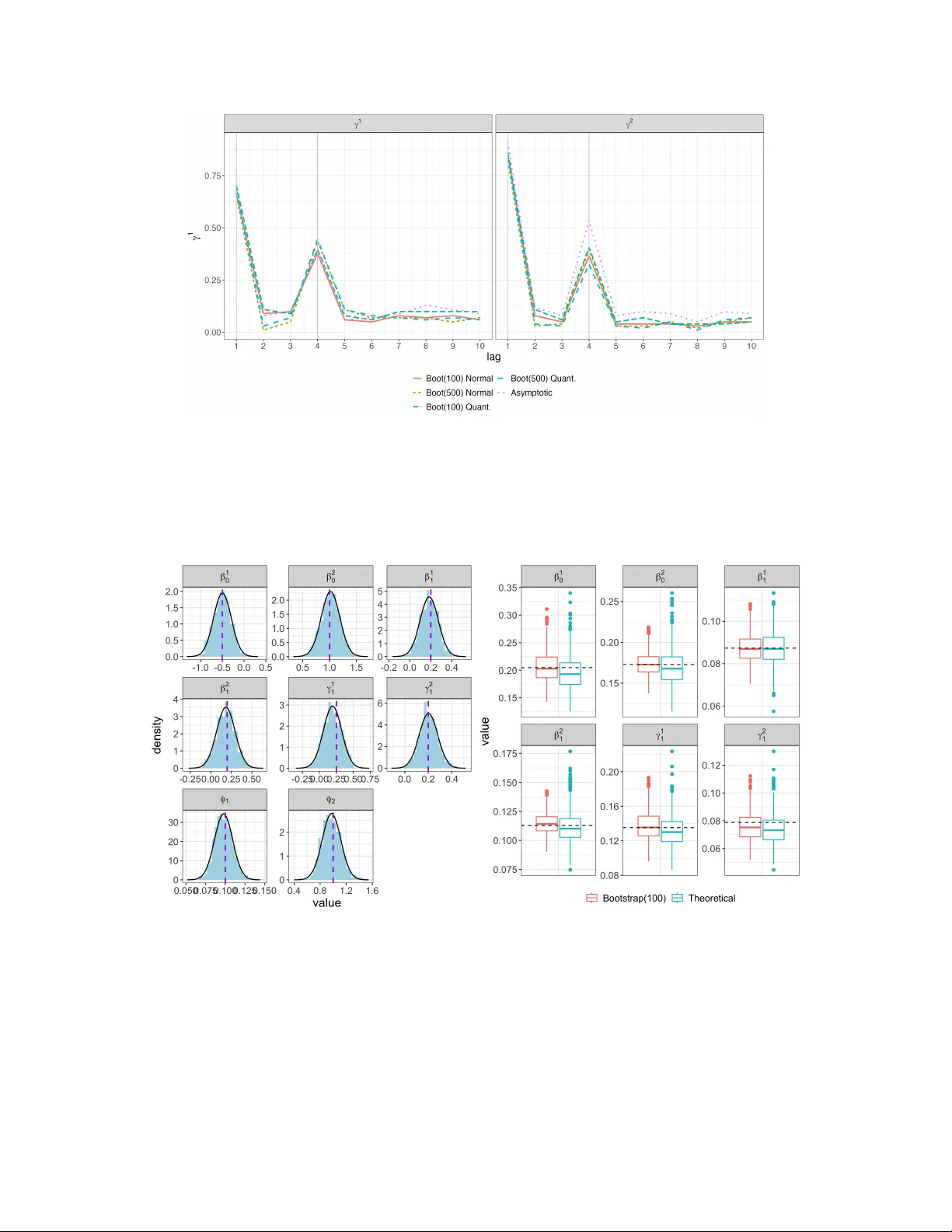
이론적 측면에서 논문은 세 가지 주요 결과를 제시한다. 첫째, 평균‑분산 지정만으로도 quasi‑maximum likelihood estimator(QMLE)가 일관성(consistency)과 점근정규성(asymptotic normality)을 만족한다는 정리를 증명하였다. 이는 ϕ(분산 파라미터)가 알려지지 않아도 추정량이 큰 표본에서 정상분포를 따른다는 의미이며, 표준 오차와 신뢰구간을 이론적으로 계산할 수 있게 한다. 둘째, 평균과 분산 모두에 대한 Granger 인과관계 검정을 일반화하였다. 기존 Granger 검정은 선형 정규 VAR에 국한돼 평균 수준에서만 인과관계를 판단했지만, MixTSQL에서는 μ₁ₜ와 μ₂ₜ의 회귀계수가 0인지 여부를 검정함으로써, 바이럴로드가 사망자 수의 평균뿐 아니라 변동성(분산)까지 선행하는지를 동시에 평가한다. 셋째, 이러한 검정 절차가 실제 데이터와 시뮬레이션에서 유효함을 보였다.
시뮬레이션 연구에서는 실제 São Paulo 데이터의 특성을 모방해 다양한 시나리오(다양한 분산 함수, 서로 다른 상관구조, 샘플 크기 등)를 설정하였다. 결과는 (1) QMLE가 평균과 분산 파라미터를 정확히 복원하고, (2) 이론적 표준오차와 부트스트랩 기반 표준오차가 모두 근사적으로 일치하며, (3) Granger 인과관계 검정의 제1종 오류와 검정력도 기대 수준에 부합함을 보여준다.
실증 분석에서는 2020년 3월 20일부터 2022년 5월 22일까지 São Paulo의 일일 PCR 검사 결과(총 342,699건)와 사망자 수를 사용하였다. 일일 데이터는 주말에 보고가 지연되는 등 0값이 많이 발생해 변동성이 과도했으므로, 주간 평균으로 집계해 112개의 관측치를 얻었다. 바이럴로드는 1−표준화(Ct) 형태로 (0,1) 구간에 정규화하였다. MixTSQL 모델을 추정한 결과, 바이럴로드의 1주 및 2주 lag가 사망자 수의 평균을 유의하게 설명했으며, 특히 lagged 바이럴로드가 사망자 수의 분산을 증가시키는 효과도 확인되었다. Granger 인과관계 검정에서는 “바이럴로드 → 사망자 수”가 평균·분산 모두에서 유의(p < 0.01)했으며, 반대 방향은 통계적으로 유의하지 않았다.
예측 성능 비교에서는 동일한 데이터에 전통적인 Gaussian VAR(2) 모델을 적용했을 때와 MixTSQL을 적용했을 때의 루트 평균 제곱 오차(RMSE)를 계산하였다. MixTSQL은 사망자 수 예측에서 약 15 % 낮은 RMSE를 기록했으며, 바이럴로드 예측에서도 소폭 개선되었다. 이는 모델이 데이터의 비정규성(바운드와 카운트 특성)을 적절히 반영했기 때문으로 해석된다.
논문의 의의는 다음과 같다. 첫째, 평균·분산만 지정하면 되는 quasi‑likelihood 기반 혼합형 시계열 모델을 제시해, 다양한 데이터 유형을 하나의 프레임워크로 통합했다. 둘째, Granger 인과관계를 평균·분산 두 차원에서 동시에 검정할 수 있는 방법을 제공해, 전염병 역학에서 선행‑후행 관계를 보다 정밀하게 파악할 수 있게 했다. 셋째, 실제 대규모 바이럴로드·사망자 데이터에 적용해 바이럴로드가 사망률을 선행한다는 실증적 증거를 제시했으며, 예측 정확도 향상도 입증했다.
한계점으로는 (1) 평균 구조가 잘못 지정될 경우 일관성 보장이 무너지며, (2) 분산 함수 선택이 경험적으로 이루어져야 하므로 모델링 과정에 주관성이 개입될 수 있다. 또한, ϕ 파라미터 추정 시 초기값에 민감할 수 있어, 복잡한 다변량(>2) 확장 시 수렴 안정성을 확보해야 한다. 향후 연구에서는 (a) 비선형 평균 함수(예: 신경망)와 결합한 MixTSQL, (b) 다변량 혼합형 시계열에 대한 차원 축소 및 변수 선택 방법, (c) 실시간 스트리밍 데이터에 대한 온라인 추정 알고리즘 개발 등을 제안한다. 이러한 확장은 전염병뿐 아니라 금융, 환경, 신경과학 등 다양한 분야에서 이질적인 시계열 데이터를 동시에 분석하는 데 활용될 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기