멀티모달 대형 언어 모델의 얼굴 검증에서 인구통계적 공정성 평가
본 논문은 2B~8B 파라미터 규모의 9개 오픈소스 멀티모달 대형 언어 모델(MLLM)을 IJB‑C와 RFW 두 얼굴 검증 벤치마크에 적용해 인종·성별별 정확도와 공정성을 정량화한다. FaceLLM‑8B가 전용 얼굴 인식 모델을 능가하지만, 정확도가 높은 모델이 반드시 공정한 것은 아니며, 오류율이 전반적으로 낮은 모델이 특정 그룹에 불리하게 작용한다는 점을 발견했다.
저자: Ünsal Öztürk, Hatef Otroshi Shahreza, Sébastien Marcel
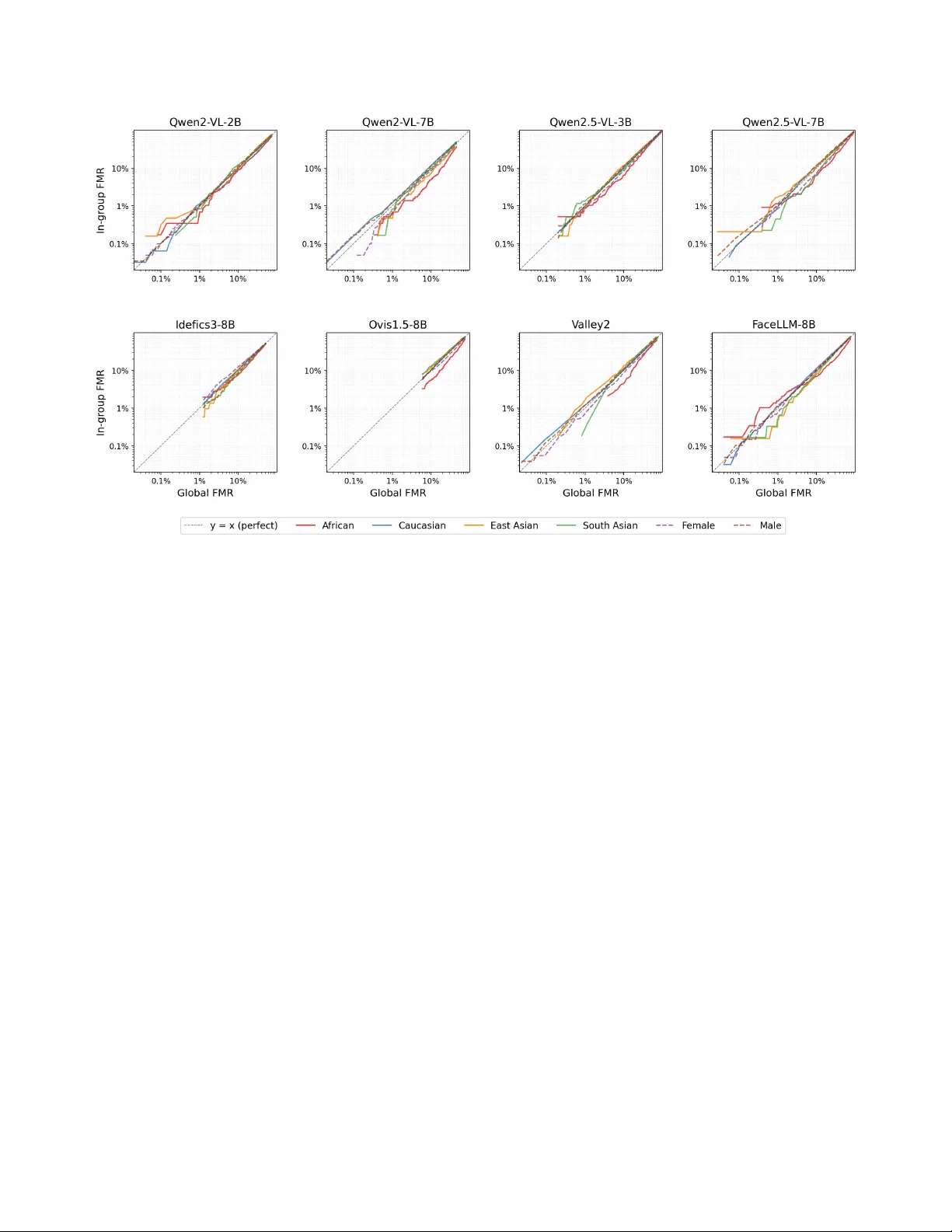
본 논문은 멀티모달 대형 언어 모델(MLLM)이 얼굴 검증 작업에 적용될 때 나타나는 인구통계적 공정성을 체계적으로 조사한다. 기존 얼굴 인식 시스템은 대규모 라벨링된 얼굴 데이터로 학습된 임베딩 네트워크를 사용해 고정 길이 벡터를 추출하고, 거리 기반 임계값으로 동일인 여부를 판단한다. 반면, MLLM은 이미지와 텍스트 프롬프트를 동시에 처리하는 비전‑언어 모델로, “두 얼굴이 같은 사람인지 0~100 점으로 답하라”는 질문에 텍스트 형태의 점수를 반환한다. 이 점수를 정규화해 유사도 스코어로 활용하고, 템플릿(다중 이미지) 경우 모든 이미지 쌍에 대해 점수를 얻어 평균을 내는 방식을 채택한다.
평가에 사용된 데이터는 IJB‑C와 RFW 두 벤치마크이다. IJB‑C는 3,531명의 피험자를 포함한 19,557개의 1:1 템플릿 쌍을 제공하며, 성별(남·여)과 인종(아프리카, 동아시아, 남아시아, 백인) 라벨이 있다. 전체 프로토콜이 방대해 실험에서는 10,000개의 템플릿 쌍을 무작위 추출해 사용했으며, 각 모델당 약 20일의 H100 GPU 연산이 소요되었다. RFW는 인종별로 각각 3,000개의 genuine와 3,000개의 impostor 쌍을 균등하게 제공해 인종 편향 분석에 특화된 데이터셋이다.
실험에 포함된 모델은 총 9개이며, 6개 패밀리(Idefics‑3‑8B, Ovis‑1.5‑8B, Qwen2‑VL‑2B/7B, Qwen2.5‑VL‑3B/7B, Valley‑2‑7B, LLaVA‑NeXT‑Mistral‑7B)와 얼굴 전용 파인튜닝 모델(FaceLLM‑8B)이다. 파라미터 수는 2 B에서 8 B까지 다양하고, 모두 zero‑shot 설정으로 평가했다. LLaVA‑NeXT‑Mistral‑7B는 유사도 점수가 두 종류만 나오면서 실질적인 검증 성능을 제공하지 못해 분석에서 제외했다.
성능 평가는 전통적인 FMR/FNMR을 기반으로 EER, 고정 FMR(10 %, 1 %, 0.1 %)에서의 TMR을 보고한다. 공정성 평가는 네 가지 FMR 기반 메트릭을 사용한다. (1) Δ = 최대 − 최소 FMR 차이, (2) R = 최대 / 최소 비율, (3) M = 최대 / 기하 평균 비율, (4) Gini 계수 G. 또한, decidability index(d′)를 통해 임계값에 의존하지 않은 genuine와 impostor 점수 분포의 구분 정도를 측정한다.
결과는 다음과 같다. IJB‑C에서 FaceLLM‑8B는 전역 EER 5.13 %로 가장 낮은 오류율을 기록했으며, Qwen2‑VL‑7B(8.54 %)와 Qwen2.5‑VL‑7B(10.43 %)가 그 뒤를 이었다. RFW에서도 FaceLLM‑8B가 가장 낮은 EER를 보였지만, 전체적인 오류율은 IJB‑C보다 높았다. 공정성 측면에서는 모델마다 편향 패턴이 크게 달랐다. 예를 들어 Qwen2‑VL‑7B는 아프리카계 그룹에서 FMR이 현저히 높아 Δ와 G가 크게 나타났으며, 반면 동일 모델은 전체 EER이 비교적 낮아 “정확하지만 불공정”한 사례가 된다. 반대로 Idefics‑3‑8B는 모든 그룹에서 비슷한 수준의 높은 오류율을 보여 Δ와 G가 작게 나오지만, 이는 실제 공정성을 의미하기보다 전반적 성능 부진을 반영한다.
고정 FMR 0.1 %와 같은 엄격한 보안 수준에서는 모든 모델의 TMR이 급격히 감소했으며, 특히 여성·아프리카계 그룹에서 FNMR이 크게 상승했다. 이는 멀티모달 LLM이 이미지 품질·조명·표정 등 시각적 변동에 민감함을 시사한다. decidability index는 FaceLLM‑8B가 가장 높은 d′ 값을 기록해 genuine와 impostor 점수 분포가 가장 명확히 구분됨을 확인했다.
논문은 두 가지 주요 시사점을 제시한다. 첫째, 현재 공개된 일반 목적 비전‑언어 모델은 전용 얼굴 인식 시스템에 비해 정확도와 공정성 모두에서 뒤처진다. 얼굴 전용 파인튜닝이 성능·공정성 모두에 큰 이점을 제공한다는 점은 향후 도메인‑특화 파인튜닝 전략이 필요함을 강조한다. 둘째, 공정성 평가 시 단일 오류율만으로는 충분치 않으며, Δ, R, M, G와 같은 다중 메트릭을 함께 고려해야 편향 현상을 정확히 파악할 수 있다. 이러한 접근은 ISO/IEC 19795‑10:2024 표준이 제시하는 “FMR 및 FNMR 차이와 비율 보고”와 일맥상통한다.
결론적으로, 멀티모달 LLM은 기존 얼굴 검증 파이프라인을 대체하거나 보완할 잠재력을 가지고 있지만, 현재 단계에서는 정확도·공정성 모두에서 전용 모델에 미치지 못한다. 향후 연구는 (1) 대규모 얼굴 데이터로 사전 학습된 멀티모달 모델 개발, (2) 인구통계적 편향을 최소화하는 프롬프트 설계 및 후처리 기법, (3) 다양한 운영점에서의 공정성 메트릭을 통합한 평가 프레임워크 구축에 초점을 맞춰야 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기