계층 인식 멀티모달 학습으로 생물 분류 정확도 혁신
본 논문은 이미지와 DNA 바코드 등 여러 모달리티를 이용해 생물의 계통학적 라벨을 예측할 때, 기존의 평면 라벨 방식이 갖는 한계를 극복하고자 계층 정보를 직접 정규화에 포함하는 두 가지 엔드‑투‑엔드 모델인 CLiBD‑HiR과 CLiBD‑HiR‑Fuse를 제안한다. 계층 정규화(Hierarchical Information Regularization, HiR)를 통해 임베딩 공간에 상위‑하위 관계를 구조화하고, Fuse 변형에서는 가벼운 게이…
저자: Sk Miraj Ahmed, Xi Yu, Yunqi Li
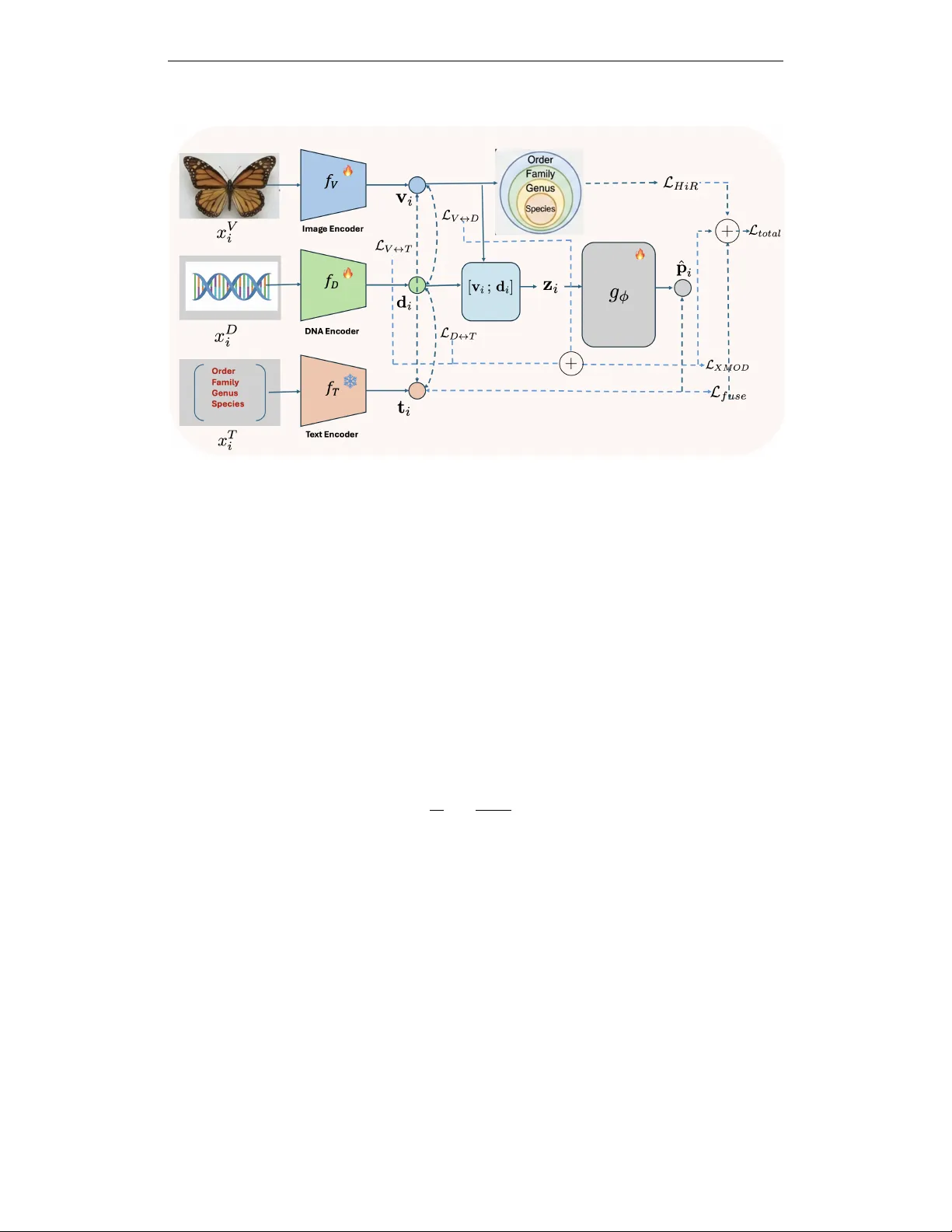
본 연구는 대규모 현장 생물다양성 데이터에서 흔히 발생하는 ‘이미지와 DNA 바코드가 불완전하거나 하나만 존재하는’ 상황을 고려한 새로운 멀티모달 학습 프레임워크를 제시한다. 기존 멀티모달 방법은 이미지‑텍스트 혹은 이미지‑DNA 간의 대조학습을 통해 서로 다른 모달리티를 동일한 임베딩 공간에 정렬하지만, 생물학적 라벨이 갖는 계층적 구조(계, 목, 과, 속, 종)를 반영하지 못한다. 이로 인해 동일 과에 속하는 종들이 서로 멀리 떨어지는 현상이 발생하고, 노이즈가 섞인 입력이 임베딩을 임의의 클러스터로 이동시켜 상위 레벨까지 오류가 전파되는 문제가 있다.
논문은 이러한 한계를 극복하기 위해 두 가지 엔드‑투‑엔드 모델을 설계한다. 첫 번째 모델인 CLiBD‑HiR은 ‘Hierarchical Information Regularization (HiR)’이라는 새로운 정규화 손실을 도입한다. HiR은 각 계층(예: order, family, genus, species)에 대해 같은 라벨을 가진 이미지 쌍을 Positive, 다른 라벨을 가진 이미지를 Negative로 설정한 SupCon 기반의 계층적 대조학습을 수행한다. 특히, 더 세밀한 레벨의 손실이 상위 레벨의 최대 손실을 초과하지 않도록 클리핑(max‑rectification)함으로써, 모델이 먼저 상위 레벨의 군집을 안정화시키고 그 후에 세부 레벨을 미세조정하도록 강제한다. 이 메커니즘은 임베딩 공간에 d1 < d2 < d3 형태의 거리 순서를 자연스럽게 형성시켜, 노이즈가 발생해도 ‘species 수준’ 오류가 발생하더라도 ‘genus·family·order 수준’에서는 올바른 예측을 유지하도록 만든다.
두 번째 모델인 CLiBD‑HiR‑Fuse는 위의 구조에 가벼운 게이트형 융합 모듈(GatedFusion)을 추가한다. 이미지와 DNA 임베딩을 각각 추출한 뒤, 존재하는 모달리티에 따라
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기