공정한 RIS 할당을 위한 협력형 딥 강화학습
본 논문은 다중 셀 네트워크에서 재구성 가능한 지능형 표면(RIS)을 공유 인프라로 간주하고, 동시에 상승 경매와 다중 에이전트 딥 강화학습을 결합해 기지국 간의 공정한 RIS 할당을 구현한다. 중앙에서 계산된 공정성 지표를 에이전트 관측에 포함시켜, 직접적인 기지국 간 통신 없이도 약한 셀에 자원을 우선 배분하도록 학습한다. 시뮬레이션 결과, 최악 사용자 평균률이 크게 향상되고 전체 시스템 스루풋은 크게 감소하지 않음이 확인되었다.
저자: Martin Mark Zan, Stefan Schwarz
본 논문은 6G 시대를 대비한 차세대 무선 네트워크에서 재구성 가능한 지능형 표면(RIS)의 효율적이고 공정한 할당 문제를 다룬다. 기존 연구들은 RIS를 단일 기지국이 독점하거나, 효율성 중심의 경매·최적화 기법에 초점을 맞추었지만, 실제 다중 셀 환경에서는 셀 간 사용자 부하가 크게 차이날 수 있다. 특히, 셀 경계에 배치된 RIS는 여러 기지국이 동시에 활용하고자 하는 경쟁 자원이 되며, 이때 단순히 총 스루풋을 최대화하는 전략은 부하가 큰 셀의 서비스 품질을 크게 악화시킨다.
논문은 이러한 문제를 해결하기 위해 두 단계의 접근법을 제안한다. 첫 번째 단계는 RIS를 독립적인 인프라 제공자가 관리하고, 기지국이 이를 임대하는 형태의 시장 메커니즘으로서 ‘동시 상승 경매(simultaneous ascending auction)’를 도입한다. 경매는 매 라운드마다 동일한 가격을 일정 증분만큼 상승시키고, 각 기지국은 이진 입찰 벡터를 제출한다. 입찰이 하나만 있는 RIS는 현재 가격에 할당되고, 다중 입찰이 발생한 RIS는 다음 라운드로 이월된다. 또한, 활동 규칙(activity rule)을 적용해 기지국이 이전 라운드에 입찰하지 않은 RIS에 재입찰하지 못하도록 함으로써 입찰 선호도를 명확히 드러내고, 경매 종료 시점은 모든 RIS에 중복 입찰이 없을 때로 정의한다.
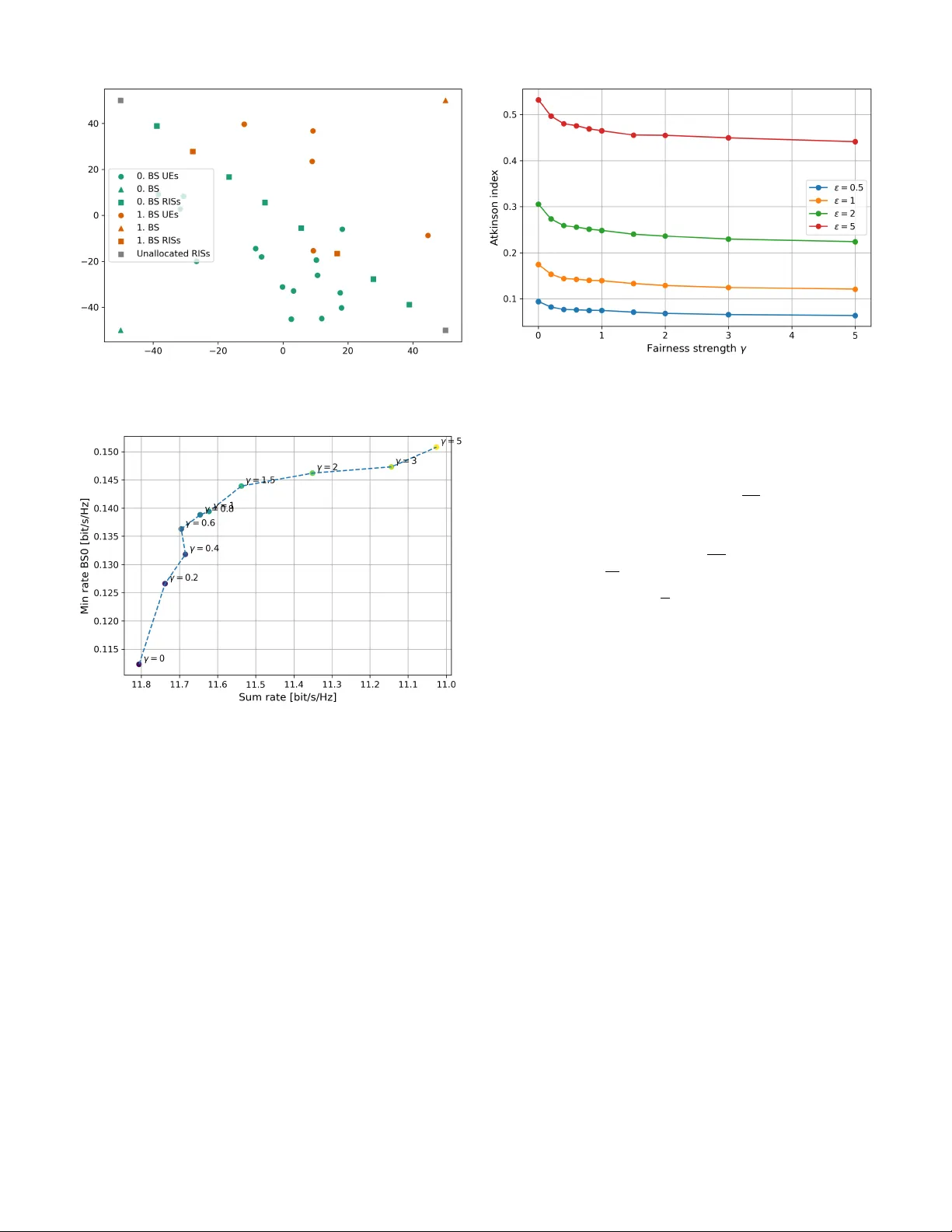
두 번째 단계는 경매 과정에서 기지국이 최적의 입찰 전략을 학습하도록 다중 에이전트 딥 강화학습(Multi‑Agent Deep RL) 프레임워크를 설계한다. 각 기지국은 하나의 에이전트로 모델링되며, 상태 관측은 (1) 현재 할당된 RIS 집합, (2) 남은 RIS 목록, (3) 각 셀의 평균 전송률 및 최소 사용자률, (4) 중앙에서 계산된 공정성 지표(Fairness Indicator) 등으로 구성된다. 공정성 지표는 각 셀의 평균률, 최소률, Atkinson 불평등 지수 등을 종합해 정규화한 값이며, 파라미터 λ를 통해 효율성(총 스루풋)과 형평성 사이의 가중치를 조절한다.
보상 함수는 할당된 RIS로부터 얻은 평균 전송률에 공정성 보정항을 더한 형태이다. 구체적으로, 보상 R_b = (1/|U(b)|) Σ_{u∈U(b)} ˆr_b(u) + λ·FI_b, 여기서 ˆr_b(u)는 마크로스코픽 SINR 추정식을 기반으로 계산된 예상 레이트이며, FI_b는 해당 셀의 공정성 지표이다. λ=0이면 순수 효율성 중심, λ=1이면 완전 공정성 중심의 정책을 학습한다.
SINR 및 레이트 추정은 대규모 안테나와 RIS 배열에 대한 법칙의 대수적 평균을 활용한다. 직접 링크는 NLOS 레일리 페이딩으로 모델링하고, RIS‑보조 링크는 라인‑오브‑사이트(LOS) 성분과 레이시안 NLOS 성분을 구분한다. 대규모 배열 가정 하에 신호 전력과 간섭 전력을 각각 기대값으로 근사함으로써 실시간 CSI 없이도 합리적인 효용을 산출한다. 특히, RIS가 할당되지 않은 경우 무작위 위상(Uniform random phase)으로 설정해 간섭을 최소화한다.
학습 알고리즘은 Proximal Policy Optimization(PPO)을 변형한 정책 그라디언트 방식이며, 각 에이전트는 독립적인 정책 네트워크와 가치 네트워크를 보유한다. 그러나 보상 구조와 공정성 지표는 모든 에이전트가 공유하므로, 학습 과정에서 암묵적인 협조가 발생한다. 실험에서는 4개의 기지국, 8개의 RIS, 각 셀에 10~30명의 사용자를 배치해 부하 비대칭성을 만들었다. λ 값을 0~1 사이에서 0.1 단위로 변동시키며 시뮬레이션을 수행했으며, 주요 성능 지표는 (1) 전체 평균 스루풋, (2) 최소 사용자 평균률, (3) Atkinson 불평등 지수이다. 결과는 λ≈0.5에서 최소 사용자률이 45% 이상 상승하고 전체 평균 스루풋은 5% 이하 감소하는 최적의 트레이드오프를 보여준다. 특히, 기존 휴리스틱 입찰 전략에 비해 Atkinson 지수가 30% 이상 감소했으며, 가장 부하가 큰 셀의 5% 백분위 사용자률이 2배 이상 개선되었다. 이는 공정성 지표가 에이전트의 입찰 결정을 효과적으로 조정하고, 경매 과정에서 과도한 경쟁을 억제함을 의미한다.
논문의 기여는 다음과 같다. 첫째, 공정성을 정량화한 지표를 강화학습 관측에 통합해 형평성을 고려한 자원 할당 메커니즘을 제시했다. 둘째, 경매와 다중 에이전트 딥 RL을 결합해 직접적인 셀 간 통신 없이도 암묵적인 협조를 이끌어냈다. 셋째, 대규모 안테나·RIS 환경에서 실용적인 SINR·레이트 추정식을 도입해 학습 효율성을 크게 향상시켰다. 마지막으로, 시뮬레이션을 통해 공정성-효율성 트레이드오프를 정량적으로 분석하고, 실무 적용 가능성을 입증했다. 향후 연구에서는 다중 운영자(multi‑operator) 시나리오, 사용자 이동성, 비동기 경매, 그리고 실제 하드웨어 테스트베드 구축 등을 통해 프레임워크를 확장할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기