온‑정책 증류의 함정과 간단한 해결책: 토큰‑레벨 편향·분산·토크나이저 불일치 극복
본 논문은 대형 언어 모델 사후 학습에서 온‑정책 증류(OPD)의 토큰‑샘플링 방식이 장기 시퀀스에서 편향·고분산·토크나이저·특수 토큰 불일치라는 세 가지 주요 실패 모드를 보임을 밝힌다. 이를 해결하기 위해 교사의 상위 K 토큰 집합을 이용한 로컬 지원 매칭(Truncated Reverse‑KL with top‑p rollout 및 특수 토큰 마스킹)을 제안하고, 수학 추론 단일 과제와 다중 과제(agentic‑plus‑math) 실험에서 학…
저자: Yuqian Fu, Haohuan Huang, Kaiwen Jiang
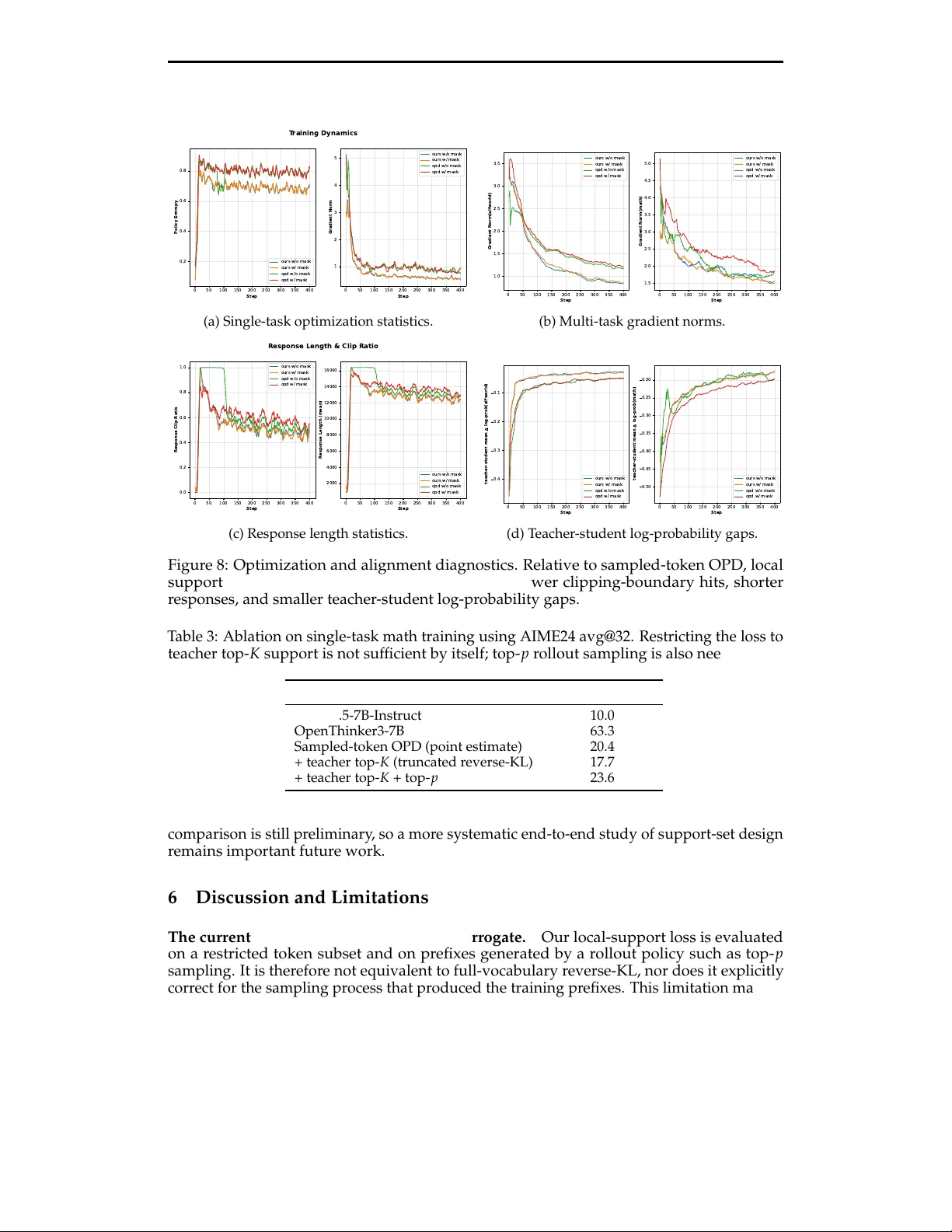
본 연구는 대형 언어 모델(LLM) 사후 학습에서 온‑정책 증류(On‑Policy Distillation, OPD)가 제공하는 장점과 한계를 체계적으로 분석한다. OPD는 학생 모델이 자체 생성한 롤아웃에 대해 교사 모델의 피드백을 직접 적용함으로써, 고정된 교사 트레이스에 의존하는 오프라인 증류와 달리 장기 추론이나 에이전트‑형태 학습에 유리하다는 점이 강조된다. 그러나 현재 LLM 파이프라인에서 널리 사용되는 “샘플된 토큰” 방식은 실제로는 토큰‑레벨 로그 비율 rₜ=log πθ(yₜ|cₜ)−log q(yₜ|cₜ)만을 이용해 업데이트를 수행한다. 이 근사는 시퀀스‑레벨 역 KL 목표와 비교했을 때 두 가지 근본적인 차이를 만든다.
첫 번째 차이는 편향이다. 시퀀스‑레벨 역 KL은 각 토큰 업데이트가 미래 보상(교사‑학생 로그 비율)의 누적에 의존하도록 설계돼, 전체 시퀀스 분포를 교사와 일치시키려는 목표를 갖는다. 반면 토큰‑레벨 OPD는 즉시 보상만을 사용해 미래 정보를 무시하므로, 교사와 학생 사이의 전체 분포 차이를 완전히 반영하지 못한다. 두 번째 차이는 분산이다. 논문은 유한한 보상·스코어 함수 경사에 대해 토큰‑레벨 OPD의 최악 경우 분산 상한이 O(T²)인 반면, 시퀀스‑레벨 추정기의 상한은 O(T⁴)임을 수학적으로 증명한다. 여기서 T는 시퀀스 길이이다. 따라서 장기 롤아웃에서는 토큰‑레벨 접근이 분산 면에서 현저히 유리하다.
이론적 분석을 보강하기 위해 저자는 γ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기