LLM 기반 검색 엔진의 블랙햇 SEO 내성 및 새로운 LLMSEO 위협 분석
본 논문은 대규모 언어 모델(Large Language Model)과 검색 기능이 결합된 LLM‑Enhanced Search Engine(LLMSE)의 보안성을 최초로 체계적으로 조사한다. 1,000개의 실제 블랙햇 SEO 사이트를 모은 SEO‑Bench 벤치마크를 활용해 10개의 대표 LLMSE(폐쇄형·오픈소스 포함)를 평가한 결과, 전통적인 SEO 공격의 99.78% 이상을 검색·재랭크 단계에서 차단함을 확인하였다. 그러나 “rewritte…
저자: Pei Chen, Geng Hong, Xinyi Wu
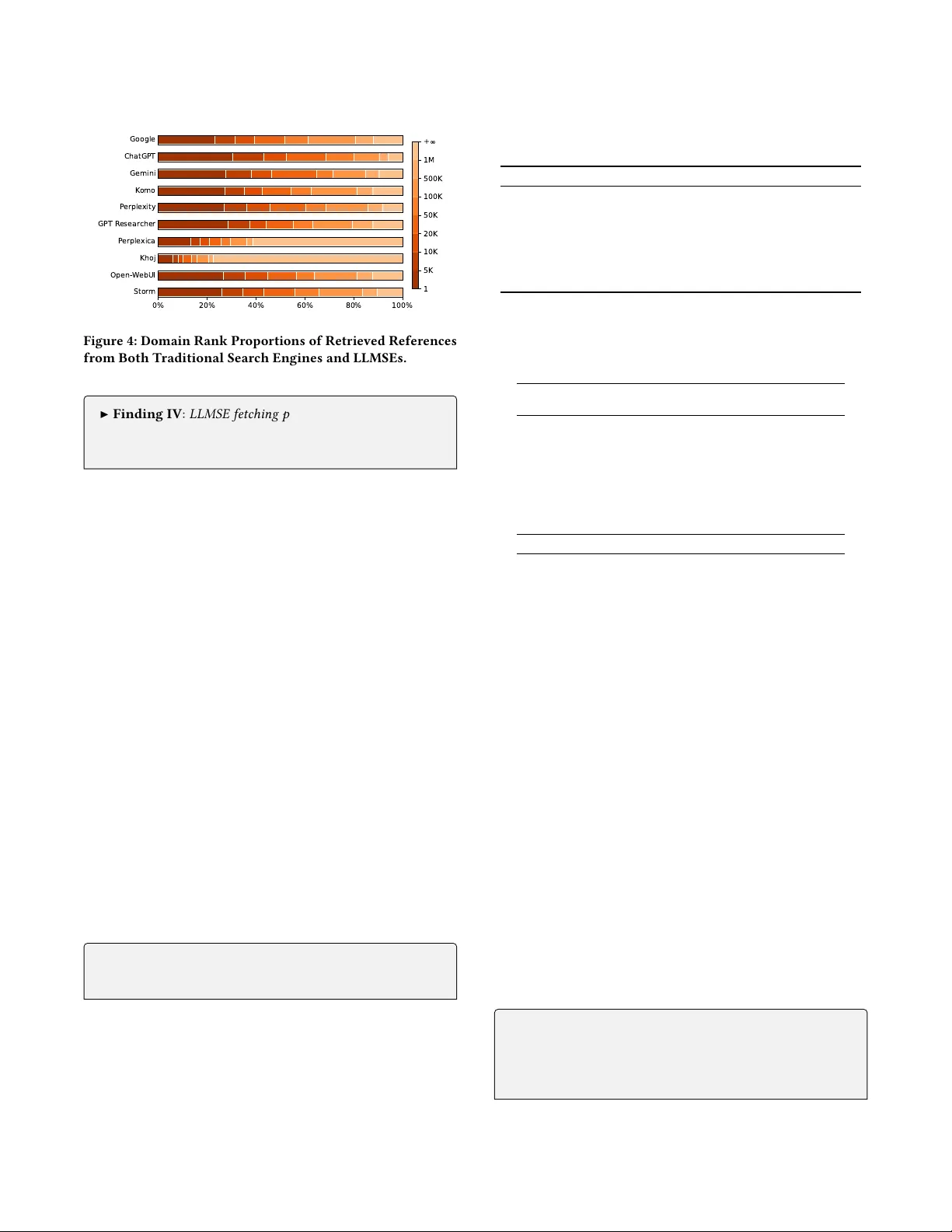
본 논문은 최근 급속히 확산되고 있는 대규모 언어 모델(Large Language Model, LLM) 기반 검색 엔진, 즉 LLM‑Enhanced Search Engine(LLMSE)의 보안성을 최초로 체계적으로 조사한다. 기존 연구는 LLMSE의 효율성, 정확성, 사실성 검증 등에 집중했으나, 블랙햇 SEO와 같은 전통적인 검색 엔진 조작 기법이 LLMSE에 미치는 영향을 거의 다루지 않았다. 이를 메우기 위해 저자들은 다음과 같은 연구 질문(RQ)을 설정하였다. (RQ1) LLMSE의 작업 흐름은 전통적인 SEO 공격에 대해 내재적인 방어 메커니즘을 가지고 있는가? (RQ2) 기존 블랙햇 SEO 기법이 LLMSE에 적용될 경우 어느 단계에서 가장 큰 영향을 미치는가? (RQ3) LLMSE를 대상으로 하는 새로운 LLMSEO 공격 기법이 존재하는가?
연구는 먼저 10개의 대표적인 LLMSE 제품(폐쇄형: ChatGPT, Gemini, Google AI Overview 등; 오픈소스: Open WebUI, Khoj, Storm 등)을 선정하고, 각 시스템의 파이프라인을 ‘이해‑재작성’, ‘검색‑재랭크’, ‘요약‑출력’의 세 단계로 구분하였다. 각 단계별로 공격 표면을 도출하고, 실제 서비스 환경에서의 동작을 관찰하기 위해 로그 분석 및 인터랙션 테스트를 수행하였다.
다음으로, 1,000개의 실제 블랙햇 SEO 웹사이트를 포함하는 SEO‑Bench 벤치마크를 구축하였다. 이 데이터셋은 ‘Semantic Confusion’, ‘Redirection’, ‘Cloaking’, ‘Keyword Stuffing’, ‘Link Farm’ 등 다섯 가지 주요 공격 유형을 각각 200개씩 균등하게 선정한 것으로, 각 웹사이트는 Google 검색에서 상위 50개 결과에 포함된 뒤 검증된 악성 페이지이다. 저자들은 이 데이터셋을 이용해 9개의 LLMSE(Google AI Overview 제외)에게 동일한 질의 집합을 전달하고, 반환된 응답에 공격자 제어 URL이 포함되는지를 측정하였다.
실험 결과, 전통적인 블랙햇 SEO 공격의 99.78% 이상이 LLMSE의 Retrieval 단계에서 차단되었다. 이는 LLMSE가 외부 검색 엔진 API와 자체 인덱스를 활용해 다중 소스에서 정보를 수집하고, 재랭크 알고리즘을 통해 스팸·링크 팜 등을 효과적으로 필터링하기 때문이다. 특히, Query Rewriting 단계에서 LLM이 질의를 표준화하고 불필요하거나 위험한 키워드를 제거함으로써 ‘Keyword Stuffing’과 ‘Semantic Confusion’ 공격이 크게 약화되었다.
그러나 저자들은 LLMSE가 완전히 안전한 것은 아니라는 점을 발견하였다. 기존 SEO 방어 메커니즘을 우회하는 새로운 공격 기법, 즉 ‘LLMSEO’를 7가지 제안하고 실험했다. 주요 기법은 (1) Rewritten‑Query Stuffing: LLM이 재작성한 질의를 미리 예측하고, 해당 질의에 맞춰 키워드 스터핑을 수행하는 방법, (2) Segmented Text: 악성 페이지를 인위적으로 여러 작은 조각으로 나누어 키워드 밀도를 낮추고, 재랭크 단계에서 정상 문서로 오인하게 하는 방법 등이다. 이 두 기법을 결합한 경우, 베이스라인(단순 키워드 스터핑) 대비 조작 성공률이 약 2배 상승했으며, 일부 폐쇄형 LLMSE에서도 동일한 현상이 관찰되었다.
또한, 남은 0.22%의 성공 사례는 주로 (가) 재작성 질의가 원본 키워드와 거의 동일해 필터링을 통과한 경우, (나) 클로킹된 콘텐츠가 LLM의 필터링 규칙을 회피한 경우, (다) 재랭크 알고리즘이 특정 패턴을 과대 평가한 경우 등으로 분석되었다. 이러한 결과는 LLMSE가 기존 SEO 방어 메커니즘을 상당 부분 물려받지만, LLM 특유의 질의 재작성·텍스트 생성 과정이 새로운 공격 표면을 제공한다는 점을 시사한다.
저자들은 실무적 시사점을 제시한다. 첫째, Query Rewriting 단계에서 재작성 질의에 대한 정형 검증(예: 의도 일관성 검사, 키워드 빈도 제한)을 도입해 ‘rewritten‑query stuffing’을 사전 차단한다. 둘째, Retrieval 및 재랭크 단계에서 다중 신호(링크 구조, 도메인 신뢰도, 사용자 행동 로그 등)를 결합한 종합 점수 체계를 구축해 세그먼트화된 텍스트가 정상 문서로 오인되는 위험을 감소시킨다. 셋째, Summarization 단계에서 LLM이 인용하는 URL에 대해 출처 검증(예: 도메인 평판, SSL 인증서 확인)을 자동화하고, 의심스러운 링크는 별도 경고를 제공한다. 마지막으로, 지속적인 벤치마크(SEO‑Bench)와 협업적 보고 체계를 통해 새로운 LLMSEO 기법이 등장할 때마다 빠르게 대응할 수 있는 생태계를 구축할 것을 권고한다.
본 연구는 LLMSE가 전통적인 SEO 공격에 대해 높은 내성을 보이지만, LLM 특유의 질의 재작성·텍스트 생성 메커니즘을 악용한 새로운 위협이 존재함을 최초로 입증한다. 향후 연구는 보다 정교한 재작성 질의 탐지, 재랭크 알고리즘의 투명성 강화, 그리고 LLM 자체의 안전성(프롬프트 인젝션 방어) 등을 포함한 다층 방어 체계 구축을 목표로 해야 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기