비례 할당 경매 게임에서의 학습 수렴 분석
본 논문은 무한히 나눌 수 있는 자원을 비례 할당 메커니즘(Kelly 메커니즘)으로 배분하는 반복 게임을 연구한다. 특히 로그 형태의 효용을 갖는 무선 네트워크 슬라이싱 상황을 모델링하고, 단계 게임이 유일한 내시 균형(Nash equilibrium)을 가짐을 증명한다. 반복 플레이에서 모든 에이전트가 (i) 온라인 그래디언트 하강(OGD), (ii) 이차 정규화자를 갖는 듀얼 어버징(DAQ), 혹은 (iii) 즉시 최적 반응(BR) 전략을 사…
저자: Younes Ben Mazziane, Cleque-Marlain Mboulou Moutoubi, Eitan Altman
본 연구는 무한히 나눌 수 있는 자원을 비례 할당 메커니즘, 즉 Kelly 메커니즘을 통해 배분하는 게임을 반복적으로 수행하는 상황을 다룬다. 먼저, 무선 네트워크 슬라이싱에서 발생하는 공정성‑스루풋 트레이드오프를 기반으로, 각 에이전트가 할당받은 자원 비율에 로그 형태의 효용을 부여하는 모델을 제시한다. 이 모델은 α‑공정성 계열 중 α=1에 해당하는 비례 공정성을 구현하며, 실제 통신 시스템에서의 대역폭 할당 문제와 직접 연결된다.
논문은 먼저 단계 게임(G)을 정의한다. 각 에이전트 i는 입찰 변수 z_i를 선택하고, 전체 입찰 합 s_i(z)=δ+∑_{j≠i}z_j에 따라 할당 비율 x_i(z)=z_i/(∑_j z_j+δ)를 얻는다. 효용 함수는 ϕ_i(z)=V_i(x_i(z))−p_i(z_i) 형태이며, 여기서 V_i는 로그 형태의 가치 함수, p_i는 입찰에 대한 비용 함수(역함수)이다. 가정 1에 따라 V_i는 증가·볼록·두 번 미분 가능하고, p_i는 증가·볼록·두 번 미분 가능하므로 ϕ_i는 i번째 변수에 대해 볼록성을 갖는다. 이러한 구조는 게임이 집합적(aggregative)임을 의미한다.
다음으로, 저자들은 Rosen의 ‘Diagonal Strict Concavity (DSC)’ 개념을 확장한 r‑DSC 조건을 도입한다. r‑DSC는 특정 양의 벡터 r에 대해, 모든 i에 대해 r_i·∂²ϕ_i/∂z_i² + ∑_{j≠i} r_j·∂²ϕ_i/∂z_i∂z_j < 0이 성립함을 의미한다. 이 조건을 만족하면 게임은 유일한 내시 균형을 가진다. 논문은 로그 효용에 대해 r‑DSC가 만족함을 증명하고, 검증 절차를 O(n) 시간·O(1) 메모리로 단순화한다. 이는 기존에 O(n³) 복잡도를 요구하던 방법에 비해 실용성이 크게 향상된 점이다.
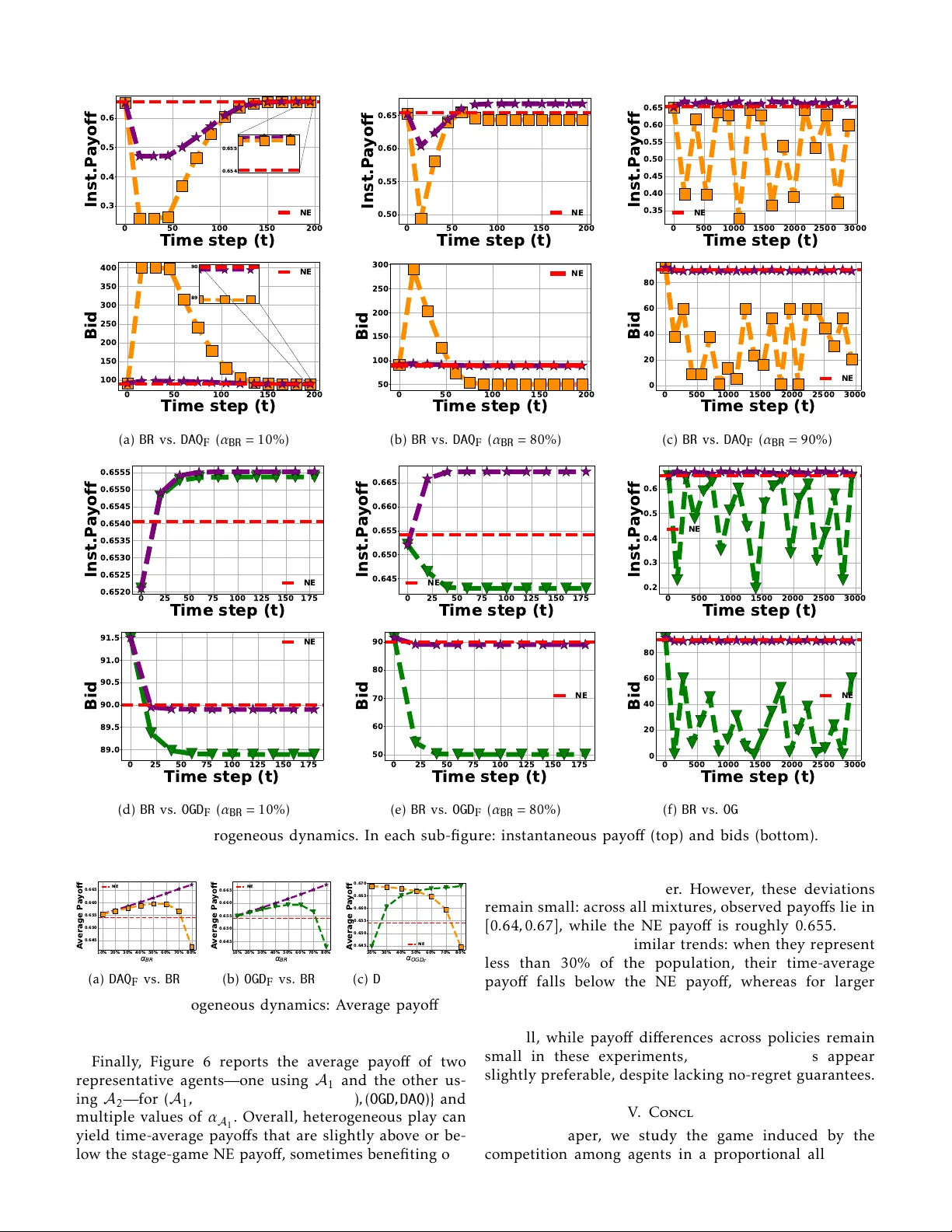
반복 게임의 학습 메커니즘으로 세 가지 알고리즘을 고려한다.
1. **Online Gradient Descent (OGD)**
각 에이전트 i는 자신의 결정 집합 R_i 내에서 학습률 η_i,t를 자유롭게 선택한다. OGD 업데이트는 z_i^{t+1}=Π_{R_i}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기