양의 감마오차와 상관오차를 고려한 웨이브렛 기반 집합 함수 추정
본 논문은 Beer‑Lambert 법칙에 따라 합성된 흡광도 곡선으로부터 개별 성분 곡선을 추정하는 문제를 다룬다. 양의 감마분포를 따르는 독립 오차와 AR(1), ARFIMA(0,d,0) 형태의 상관 오차 두 경우에 대해 베이지안 웨이브렛 수축 기법을 제안하고, MCMC 기반 RAM 알고리즘으로 사후 평균을 계산한다. 시뮬레이션과 실제 데이터 분석을 통해 제안 방법의 유효성을 검증한다.
저자: Alex Rodrigo dos Santos Sousa, João Victor Siqueira Rodrigues, Vitor Ribas Perrone
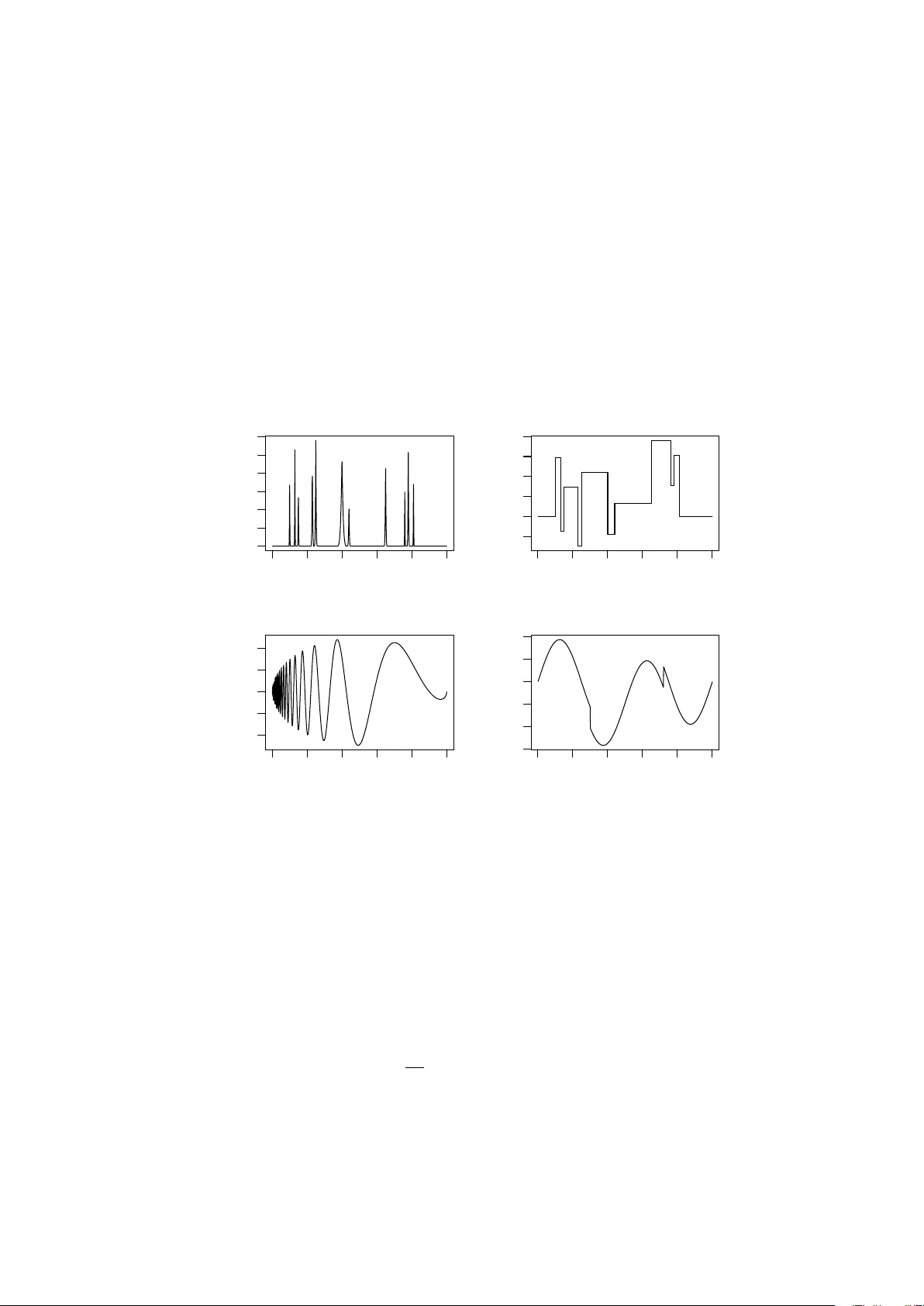
본 논문은 화학분석, 전력 소비 등 다양한 분야에서 관측되는 집합 함수(aggregated functional data) 문제를 다루며, 특히 개별 성분 함수 α_l(t)를 추정하는 캘리브레이션(calibration) 문제에 초점을 맞춘다. 기존 연구들은 주로 다변량 회귀(PCR, PLS)나 스플라인 기반 함수형 접근법을 사용했으나, 이러한 방법들은 가우시안 오차 가정에 의존하고, 급격한 변동이나 국소적인 피크와 같은 특징을 포착하는 데 한계가 있다.
이에 저자들은 웨이브렛 변환의 지역화 특성을 활용한 베이지안 웨이브렛 수축(bayesian wavelet shrinkage) 방법을 제안한다. 모델 (1)에서는 A(t)=∑_{l=1}^{L} y_l α_l(t)+ε(t) 로 정의된 합성 곡선을 사용한다. 여기서 y_l은 알려진 비중, α_l(t)는 추정 대상이며, ε(t) 는 두 종류의 오차 구조를 가진다. 첫 번째는 독립적인 감마분포(Gamma(a,b))를 따르는 양의 오차이며, 두 번째는 AR(1) 혹은 ARFIMA(0,d,0) 형태의 상관 오차이다.
데이터는 M=2^J 개의 등간격 시점에서 관측되며, 이를 행렬 형태 A=αy+ε 로 표현한다. DWT를 적용해 W 행렬을 양쪽에 곱하면 웨이브렛 도메인에서 D=Θy+ε̂ 로 변환된다. 여기서 D는 관측된 웨이브렛 계수, Θ는 성분 함수의 웨이브렛 계수, ε̂ 은 변환된 오차이다.
오차가 가우시안이 아닌 경우, 변환 후 ε̂ 은 독립성을 잃고 비정규성을 띤다. 따라서 각 계수를 독립적으로 수축할 수 없으며, 베이지안 프레임워크에서 전체 계수 벡터 θ에 대한 사후 분포를 추정해야 한다. 이를 위해 저자들은 점 질량 δ₀와 로지스틱 분포 g(·;τ)를 혼합한 사전 π(θ)=∏
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기