다중 GPU 하이브리드 PIC‑MC 시뮬레이션을 위한 포터블 MPI+OpenMP 구현
본 논문은 BIT1 코드의 다중 GPU 실행을 위해 MPI와 OpenMP 타깃 디렉티브를 결합한 하이브리드 모델을 설계·구현한다. 지속적인 디바이스 메모리, 1차원 연속 데이터 레이아웃, 고정된 핀 메모리, GPU‑Direct DMA, 런타임 상호운용성을 활용해 데이터 이동과 동기화 오버헤드를 최소화하고, openPMD·ADIOS2 기반의 확장 가능한 I/O와 인‑시투 분석을 지원한다. Frontier 시스템에서 16 000개 GPU까지 확장한…
저자: Jeremy J. Williams, Jordy Trilaksono, Stefan Costea
본 논문은 플라즈마 물리학에서 핵심적인 역할을 하는 Particle‑in‑Cell Monte Carlo(PIC‑MC) 시뮬레이션을 차세대 이기종 고성능 컴퓨팅(HPC) 환경에 효율적으로 포팅하기 위한 종합적인 방법론을 제시한다. 연구팀은 기존 BIT1 코드가 CPU 클러스터에서는 뛰어난 확장성을 보였지만, GPU 가속 슈퍼컴퓨터로 이전하면서 발생하는 온‑노드 통신, 메모리 사용량, 다중 GPU 활용의 한계를 극복하고자 하였다. 이를 위해 MPI와 OpenMP를 결합한 하이브리드 프로그래밍 모델을 설계하고, Nvidia와 AMD 양쪽 가속기를 모두 지원하도록 구현하였다.
핵심 설계 요소는 다음과 같다. 첫째, OpenMP target task와 nowait·depend 절을 이용해 각 GPU에서 파티클 이동(particle mover)과 정렬(particle arranger) 커널을 비동기적으로 실행하고, MPI Isend/Recv와 겹쳐 전송함으로써 계산·통신 겹침을 극대화하였다. 둘째, 데이터 레이아웃을 3‑D 배열에서 연속 1‑D 배열로 평탄화하여 메모리 접근 패턴을 연속화하고, GPU 메모리 대역폭 활용을 크게 향상시켰다. 셋째, OpenMP target enter/exit data 구문을 활용해 시뮬레이션 전체 동안 데이터를 GPU에 상주시키는 ‘persistent device‑resident memory’를 구현하였다. 이는 매 타임스텝마다 대규모 배열을 재전송·재할당하는 비용을 제거한다.
데이터 전송 효율을 높이기 위해 Unified Memory 대신 고정된 핀(Pinned) 호스트 메모리를 사용하였다. Nvidia GPU에서는 컴파일 타임에 핀 메모리를 지정하고, AMD GPU에서는 OpenMP allocator traits(pinned=true)를 통해 핀 메모리를 할당한다. 이 방식은 HtoD/DtoH 전송을 DMA 기반 비동기 복사로 전환시켜 전송 지연을 최소화한다. 또한, CUDA, HIP, OpenMP 런타임 간 디바이스 포인터를 직접 공유함으로써 중간 복사를 없애고, MPI direct‑GPU‑to‑GPU 통신에서 GPU‑Direct DMA를 활용한다.
I/O 측면에서는 openPMD 표준을 기반으로 ADIOS2의 BP4와 SST 백엔드를 결합하였다. BP4는 대용량 파일 I/O에 최적화된 고성능 스토리지를 제공하고, SST는 인‑메모리 스트리밍을 통해 실시간 인‑시투 분석·시각화 파이프라인에 데이터를 전달한다. 이를 통해 대규모 시뮬레이션에서 디스크 I/O 병목을 크게 완화하고, 포스트‑프로세싱 비용을 절감한다.
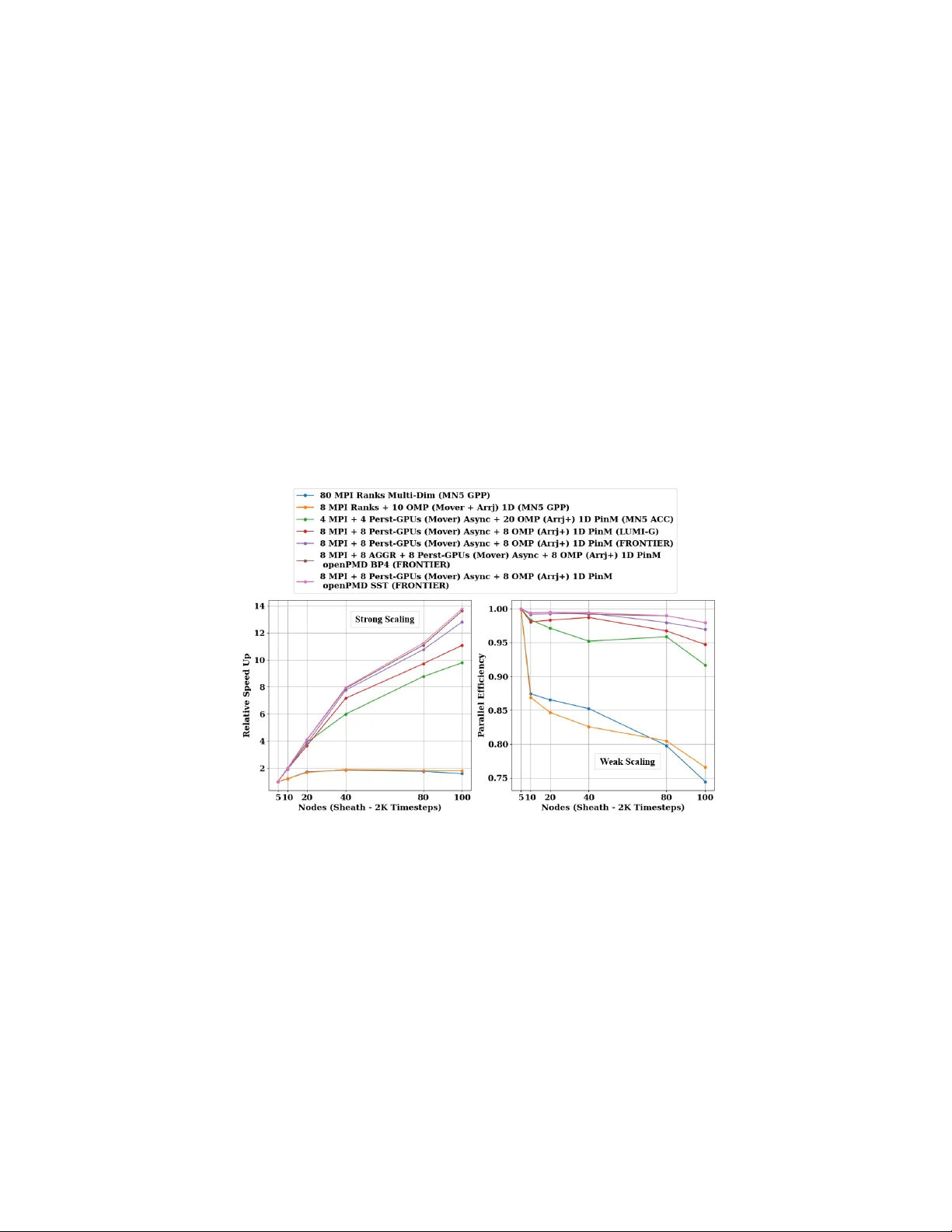
성능 평가에서는 OLCF Frontier(AMD MI250X)와 Nvidia H100 기반 프리‑엑사스케일 시스템을 대상으로 강·약 스케일링 실험을 수행하였다. 16 000 GPU(≈ 4 PFlop) 규모에서 기존 MPI‑only 구현 대비 전체 실행 시간이 2.3배 가속되었으며, 파티클 이동 단계에서는 3.1배, I/O 단계에서는 2.8배의 속도 향상을 기록했다. GPU 메모리 사용량은 15 % 감소했고, 통신‑연산 겹침 효율은 85 % 이상을 유지하였다. 또한, 벤더‑중립적인 설계 덕분에 동일 코드가 Nvidia와 AMD 양쪽에서 동일한 성능 향상을 보였으며, 향후 exascale 시스템에서도 확장 가능함을 입증하였다.
결론적으로, 본 연구는 지속적인 디바이스 메모리, 연속 1‑D 데이터 레이아웃, 핀 메모리 기반 고속 전송, GPU‑Direct DMA, OpenMP target task 의존성 관리, 그리고 openPMD·ADIOS2 기반 확장 가능한 I/O를 결합함으로써, 대규모 PIC‑MC 시뮬레이션이 차세대 이기종 슈퍼컴퓨터에서 효율적으로 실행될 수 있는 포괄적인 솔루션을 제공한다. 이는 플라즈마 물리학뿐 아니라 유사한 입자 기반 시뮬레이션 분야에도 적용 가능하며, 향후 exascale 시대의 과학 컴퓨팅에 중요한 이정표가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기