최소 전술 구성을 이용한 분포 균형 샘플링 설계
본 논문은 기존의 원형 순서 기반 방법이 갖는 위상적 제약을 없애고, 최소 전술 구성(minimum tactical configuration)을 활용한 새로운 분포 균형 샘플링 설계(DBD‑TC)를 제안한다. 고정된 표본 크기와 동일 포함 확률을 유지하면서 기대 에너지 거리(expected energy distance)를 최소화하도록 설계했으며, 간단한 초기화와 공간적 초기화, 그리고 시뮬레이티드 어닐링 최적화 알고리즘을 제공한다. 시뮬레이션과…
저자: Anton Grafström, Wilmer Prentius
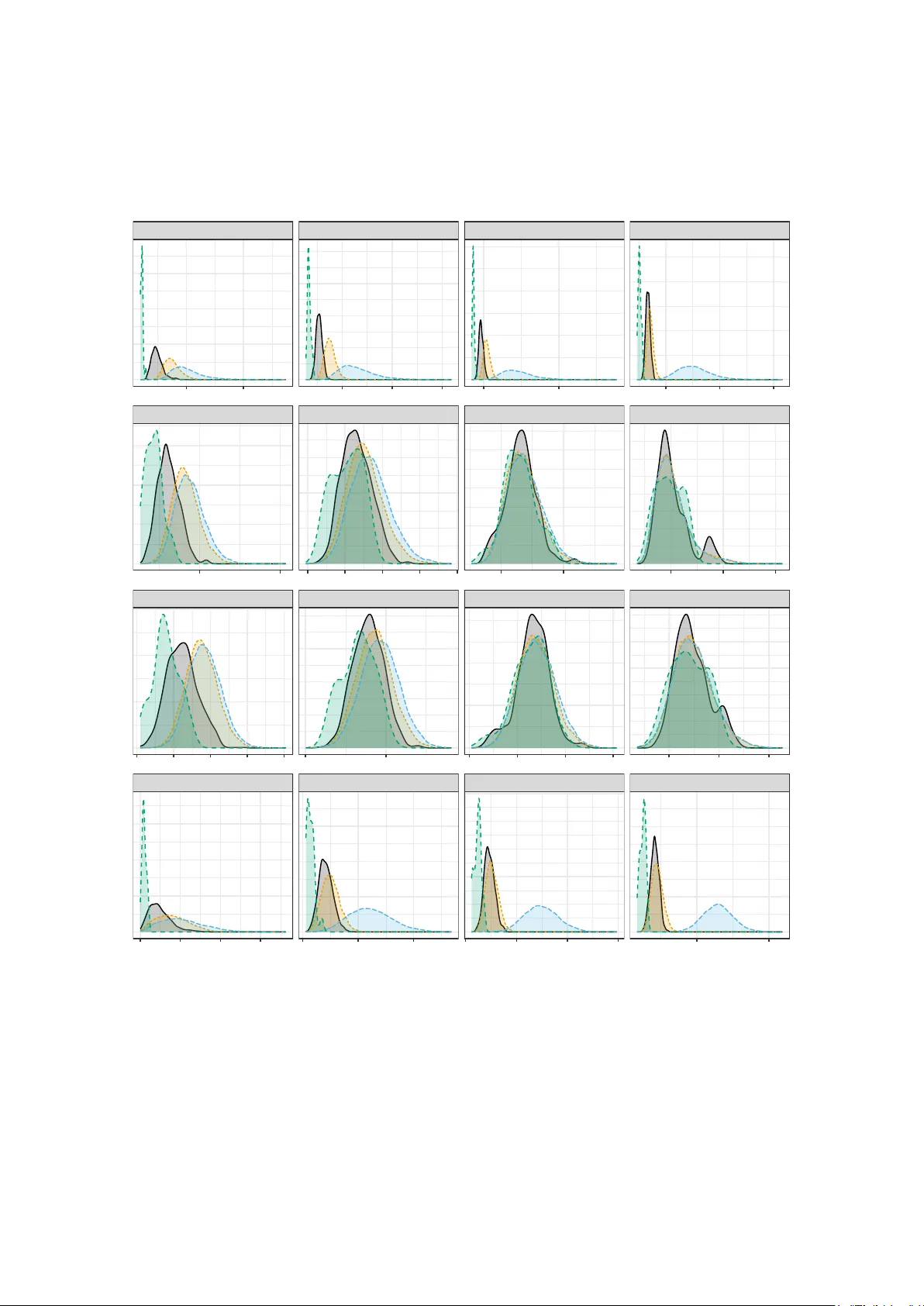
본 논문은 분포 균형 샘플링 설계(Distributionally Balanced Sampling Designs, DBD)의 기존 접근법이 갖는 구조적 한계를 극복하고, 보다 넓은 설계 공간에서 최적의 표본을 찾기 위한 새로운 프레임워크를 제시한다. 기존 DBD는 모집단을 원형 순서(circular sequence)로 배열하고, 연속적인 블록을 표본으로 선택하는 방식에 의존한다. 이러한 방식은 표본이 반드시 인접한 단위들로 구성되어야 한다는 위상적 제약을 강제하며, 결과적으로 가능한 표본 집합이 크게 제한된다. 특히, 모집단 크기 N과 표본 크기 n이 서로소가 아닌 경우(즉, gcd(N,n)>1)에도 여전히 N개의 가능한 표본을 유지해야 하므로 효율성이 떨어진다.
이를 해결하기 위해 저자들은 전술 구성(tactical configuration)이라는 조합론적 구조를 도입한다. 전술 구성은 N×M 크기의 이진 행렬 D로, 각 열이 하나의 표본(sample)이며 각 행이 모집단 단위(unit)를 나타낸다. 전술 구성은 두 가지 기본 제약을 만족한다. 첫째, 모든 열의 합이 표본 크기 n과 동일하도록 하여 각 표본이 정확히 n개의 단위를 포함한다. 둘째, 모든 행의 합이 일정한 정수 c와 같아, 각 모집단 단위가 정확히 c번씩 표본에 등장한다. 이러한 제약은 표본의 고정 크기와 동일 포함 확률(π_i = n/N)을 보장한다.
전술 구성의 최소 크기를 이론적으로 도출한다. N과 n의 최대공약수(g = gcd(N,n))를 이용해 최소 전술 구성 파라미터를 M = N/g, c = n/g 로 정의한다. 이는 전술 구성의 지원 크기(|S| ≤ M)를 가능한 최소로 만든다. 예를 들어, N=1000, n=50인 경우 g=50이므로 M=20, c=1이 된다. 이는 원형 DBD가 N=1000개의 표본을 필요로 하는 것에 비해 50배 작은 지원 집합을 제공한다.
설계 목표는 기대 에너지 거리(expected energy distance)를 최소화하는 것이다. 에너지 거리는 두 확률분포 사이의 거리 척도로, 두 표본 분포와 모집단 분포 사이의 차이를 정량화한다. 수식 (1)과 (2)에서 정의된 바와 같이, 각 표본 d_k에 대해 에너지 거리 E(F_{d_k},F_U)를 계산하고, 전술 구성 전체에 대한 평균 \(\bar{E}(D) = \frac{1}{M}\sum_{k=1}^{M}E(F_{d_k},F_U)\)를 최소화한다. 에너지 거리 최소화는 Horvitz–Thompson 추정량의 분산 감소와 직접 연결되므로, 통계적 효율성을 크게 향상시킨다.
초기화 단계에서는 두 가지 방법을 제시한다. 첫 번째는 “단순 사이클 할당”으로, 0‑1 벡터 v를 M번 순환시켜 행을 구성한다. 이 방법은 모든 (N,n) 조합에 대해 유효한 최소 전술 구성을 보장한다(Lemma 1). 두 번째는 “샘플링 기반 초기화”로, 고정‑크기 표본 생성기 f와 단계별 예산 b_k를 이용해 각 열을 순차적으로 채운다. 여기서는 지역 피벗(local pivotal) 방법을 사용해 각 표본이 공간적으로 잘 퍼지도록 설계한다. 이 “warm start”는 시뮬레이티드 어닐링 최적화 과정에서 필요한 반복 횟수를 감소시킨다.
시뮬레이티드 어닐링 최적화(Algorithm 2)는 전술 구성의 두 열 사이에서 2×2 교환(인터체인지)을 수행한다. 교환 전후에 행·열 합이 보존되므로 제약을 위배하지 않는다. Ryser(1957)의 결과에 따라 이러한 인터체인지로 전술 구성 전체가 연결(graph‑connected)되어 있음을 보장한다. 따라서 메타휴리스틱 탐색이 전체 설계 공간을 충분히 탐색할 수 있다. 비용 계산은 각 교환마다 O(n) 시간에 가능하도록 최적화되었으며, 병렬화와 대규모 인구에 대한 추가 전략이 부록에 제시된다.
실험에서는 N=1000, n=50을 기본으로 p=2,5,10,20 차원의 보조 변수를 사용해 10,000번의 Monte‑Carlo 시뮬레이션을 수행하였다. 비교 대상은 단순 무작위 표본(SRS), 지역 피벗(LPM), 지역 큐브(LCube), 그리고 기존 원형 DBD이다. 평가 지표는 평균 에너지 거리(mean E), 평균 공간 균형(mean SB), 평균 지역 균형(mean LB), 그리고 보조 변수들의 균형 편차(mean BD)이다. 결과는 DBD‑TC가 모든 지표에서 가장 낮은 값을 기록했으며, 특히 에너지 거리 측면에서 원형 DBD가 도달할 수 없는 수준까지 감소하였다. 표본 크기를 n=100,200으로 확대했을 때도 동일하게 우수한 성능을 유지하였다.
논문의 주요 기여는 다음과 같다. (1) 전술 구성을 통한 설계 공간 확장 및 위상적 제약 제거, (2) 최소 전술 구성 파라미터(M, c)의 이론적 도출, (3) 실용적인 초기화와 효율적인 시뮬레이티드 어닐링 최적화 절차, (4) 다양한 시뮬레이션과 실제 사례에서 입증된 성능 향상. 향후 연구 과제로는 비정형 공간(예: 네트워크)에서의 전술 구성 적용, 다중 목표 최적화(예: 비용‑정밀도 트레이드오프), 고차원 보조 변수에 대한 스케일링 이론 탐구 등이 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기