대규모 언어 모델 기반 인센티브 인식 보상 설계 협동 다중에이전트 강화학습
본 논문은 협동 MARL 환경에서 보조 보상의 설계 부담을 줄이고, 잘못된 인센티브로 인한 비효율을 방지하기 위해 대규모 언어 모델(LLM)을 활용해 실행 가능한 보상 프로그램을 자동 생성한다. 후보 보상은 형식적 유효성 검사를 통과한 뒤 고정된 학습 예산 내에서 정책을 처음부터 학습시켜 실제 과제의 희소 보상만으로 평가한다. Overcooked‑AI 4가지 레이아웃에서 반복적인 세대 탐색을 수행했으며, 특히 병목 현상이 심한 환경에서 기존 보…
저자: Dogan Urgun, Gokhan Gungor
**1. 연구 배경 및 동기**
협동 다중에이전트 강화학습(MARL)에서는 환경이 제공하는 희소 보상이 학습을 크게 제한한다. 보조 보상(보상 shaping)은 학습을 가속화하지만, 잘못 설계될 경우 에이전트가 실제 목표와 무관한 행동을 최적화하게 된다. 기존 이론적 접근(잠재 기반 보상 변환, 차이 보상 등)은 정책 불변성을 보장하지만, 실제 복잡한 MARL 환경에서는 구현상의 어려움과 휴리스틱 보상의 필요성이 남아 있다. 데이터 기반 자동 보상 설계(IRL, preference learning)는 대규모 시뮬레이션 환경에서 라벨링 비용이 높아 실용성이 떨어진다.
**2. 제안 방법 개요**
본 논문은 대규모 언어 모델(LLM)을 활용해 “보상 프로그램”을 자동 생성하고, 이를 MARL 학습 루프에 삽입해 목표‑그라운드 방식으로 후보를 평가한다. 전체 파이프라인은 다음과 같다.
- **환경 Instrumentation**: 상태·행동·전이 정보와 추가 메타데이터(info) 를 feature map φ 로 변환해 xₜ 를 만든다.
- **LLM 후보 생성**: 작업 설명, instrumentation 스키마, 이전 세대 요약을 컨텍스트 c₍g₎ 로 제공하고, 조건부 분포 qψ(p|c₍g₎) 에서 K개의 파이썬 형태 보상 프로그램 p 를 샘플링한다.
- **유효성 검증**: 입력·출력 타입, 결정론성, 출력 클리핑, 누락 키 처리 등을 검사하는 형식적 엔벨롭을 적용한다. 오류 발생 시 LLM에 오류 로그를 전달해 자동 수정을 시도한다.
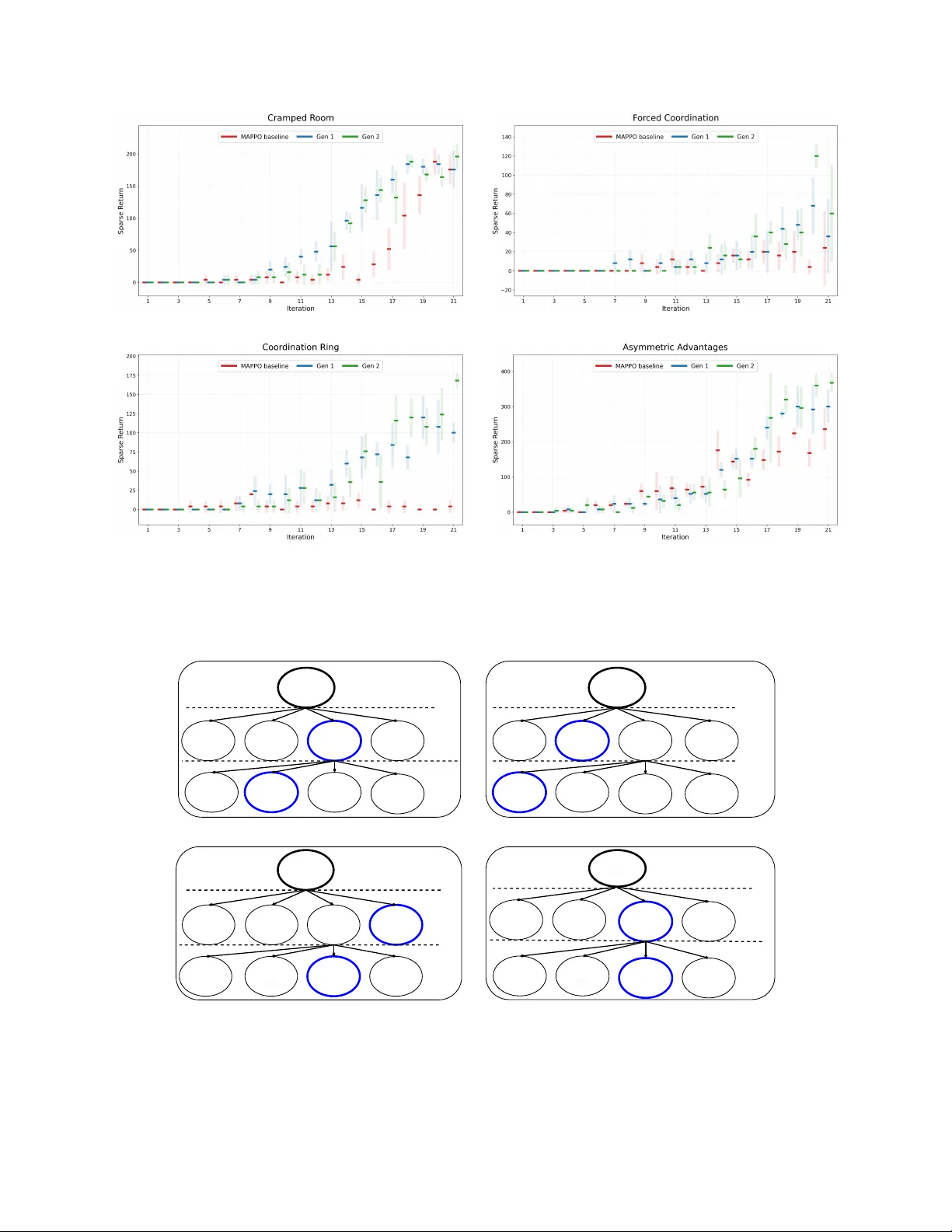
- **정책 학습 및 평가**: 검증된 후보는 고정된 MAPPO 학습기와 동일한 하이퍼파라미터 θ 로, 정해진 예산 B 안에서 정책을 처음부터 학습한다. 에이전트는 r̃ₜ,i = r_sparseₜ + λ·r(p)ₜ,i 로 보강된 보상을 받지만, 최종 성능은 희소 보상만을 사용해 J(p) = Σγᵗ r_sparseₜ 로 측정한다.
- **인센티브 진단 및 피드백**: 각 후보에 대해 Payoff Imbalance Δ(p)와 Incentive Alignment ρ(p)를 계산하고, 이를 다음 세대 컨텍스트에 포함시켜 LLM이 보다 협력 친화적인 보상을 생성하도록 유도한다.
**3. 형식적 정의**
- **협동 마르코프 게임** G = ⟨S, {Aᵢ}ₙ, P, r_sparse, γ⟩, 공동 정책 π 로 기대 반환 J(π) 를 최적화한다.
- **보상 프로그램** p : (xₜ, r_sparseₜ) → ℝⁿ, 에이전트 i 에게 r(p)ₜ,i 를 제공한다.
- **유효성 엔벨롭**은 (i) 입력·출력 서명 일치, (ii) 실행 시 예외 발생 방지, (iii) 출력값을
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기