가이드와 함께하는 시계열 예측 표현 수준 감독
ReGuider는 사전 학습된 시계열 기반 모델을 교사로 활용해, 목표 예측 모델의 인코더 임베딩을 교사의 중간 표현과 정렬함으로써 표현 수준의 감독을 제공한다. 이 플러그인 방식은 기존 아키텍처를 변경하지 않고도 임베딩의 의미론적 풍부함을 높여 MSE·MAE 등 전통적인 손실만을 최소화하는 경우보다 더 정확한 장기 예측을 달성한다. 다양한 데이터셋과 여러 베이스 모델에 적용한 실험 결과, ReGuider가 일관되게 성능 향상을 가져옴을 확인하…
저자: Jiacheng Wang, Liang Fan, Baihua Li
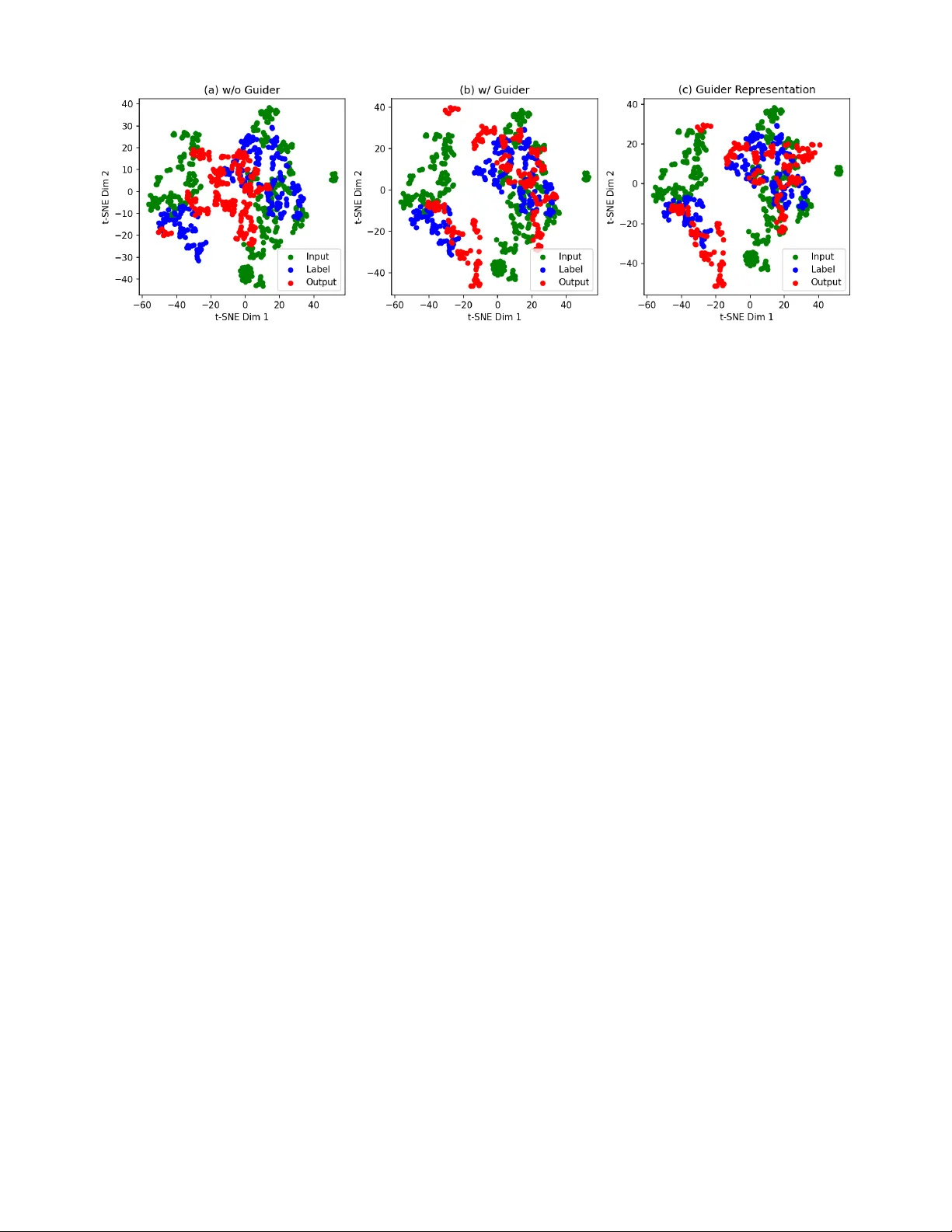
본 논문은 현대 시계열 예측이 평균 손실 최소화에만 초점을 맞추는 경향이 강해, 인코더가 중요한 극단 패턴이나 급격한 전이와 같은 정보를 버리고 부드러운 예측을 만들어낸다는 문제점을 제기한다. 이러한 현상은 인코더가 학습 과정에서 “표현 붕괴”를 겪으며, 입력 시계열의 복합적인 시간적·구조적 특성을 충분히 보존하지 못하기 때문에 발생한다. 이를 해결하기 위해 저자들은 두 가지 핵심 전략을 제안한다.
첫 번째 전략은 대규모 시계열 데이터에 사전 학습된 파운데이션 모델(TSFMs)을 “시멘틱 교사”로 활용하는 것이다. 이러한 모델은 계절성, 장기 트렌드, 변수 간 상관관계 등 다양한 시간적 패턴을 포괄적으로 학습했으며, 특히 중간 레이어의 임베딩이 풍부한 의미론적 정보를 담고 있다. 두 번째 전략은 목표 예측 모델의 인코더 출력(H_f)과 교사의 중간 임베딩(H_g)을 정렬하는 표현 수준 감독(loss L_TSRA)을 도입하는 것이다. 정렬 방식은 유클리드 거리, 코사인 유사도, KL 발산 등 여러 거리 함수를 선택 가능하며, 실험에서는 코사인 유사도가 가장 안정적인 성능 향상을 보였다.
구조적으로 ReGuider는 입력 시계열 X를 두 경로로 동시에 처리한다. 베이스 예측 모델 F_θ는 기존과 동일하게 인코더 → 디코더 → 예측 헤드 구조를 유지한다. 파운데이션 모델 G_ϕ는 사전 학습된 상태를 유지하면서(ϕ는 고정) 인코더 단계에서 H_g를 추출한다. 이후 L_total = L_Pred(Y, Ŷ) + λ·L_TSRA(H_f, H_g) 형태로 손실을 결합해 학습한다. 여기서 λ는 두 손실 간의 트레이드오프를 조절하는 하이퍼파라미터이며, 실험에서는 0.1~0.5 사이가 적절했다.
핵심 설계 중 하나는 “비대칭 그래디언트 흐름”이다. 교사의 파라미터 ϕ는 고정하고, stop‑gradient 연산을 통해 H_g가 학습에 영향을 주지 않도록 함으로써 교사의 보편적 시간 어휘가 퇴화되는 것을 방지한다. 이는 전통적인 지식 증류(KD)와 차별화되는 점으로, KD가 출력(logits) 정렬에 초점을 맞추는 반면, ReGuider는 내부 표현 정렬에 집중한다.
실험에서는 iTransformer, PatchTST, DLinear, TimeMixer 등 네 가지 최신 시계열 예측 백본에 ReGuider를 적용하였다. 평가 데이터셋은 전력 부하(ETTh1/2, ETTm1/2), 기상(Weather), 전력 소비(Electricity), 교통량(Traffic) 등 7개를 사용했으며, 예측 길이 T=96,192,336,720에 대해 MSE와 MAE를 측정했다. 전반적으로 ReGuider를 적용한 모델은 모든 백본과 데이터셋에서 평균 3~7% 정도의 MSE 감소를 보였으며, 특히 급격한 변동이 많은 ETTh2와 Traffic 데이터에서 눈에 띄는 개선을 기록했다. 또한, 거리 함수별 비교에서는 코사인 유사도가 가장 일관된 성능 향상을 제공했으며, KL 발산은 일부 데이터에서 불안정한 학습을 야기했다.
한계점으로는 파운데이션 모델의 선택에 따라 성능 차이가 존재한다는 점이다. 논문에서는 “Base”, “Large”, “Ultra” 세 규모의 Time‑MoE 파운데이션 모델을 실험했으며, 규모가 클수록 교사의 표현력이 풍부해 성능 향상이 크지만, 메모리와 연산 비용이 크게 증가한다. 또한, λ 값에 대한 민감도가 존재해, 과도한 λ는 예측 손실을 희생하면서 표현 정렬에만 치우치는 현상이 관찰되었다.
향후 연구 방향으로는 (1) 다중 교사 모델을 병합해 다양한 시계열 도메인의 특성을 동시에 반영하는 멀티‑티처 프레임워크, (2) 동적 λ 스케줄링을 통해 학습 초반에는 예측 손실에, 후반에는 표현 정렬에 비중을 조절하는 방법, (3) 비정형 시계열(예: 이벤트 시퀀스)에도 적용 가능한 교사 임베딩 추출 기법 개발 등을 제시한다.
결론적으로, ReGuider는 기존 예측 모델에 최소한의 구조적 변경만으로도 풍부한 시간 의미론을 학습하게 하여, 전통적인 손실 기반 학습의 한계를 보완하고, 다양한 실세계 시계열 예측 과제에서 실질적인 성능 향상을 입증한 혁신적인 방법론이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기