실시간 대화 중단 감지를 위한 의미 인식 벤치마크와 APT 지표
본 논문은 실제 인간 대화를 기반으로 만든 최초의 의미‑인식 중단 감지 벤치마크 SID‑Bench을 제안하고, 오탐과 지연을 시간 비용으로 통합한 평균 패널티 시간(APT) 지표를 정의한다. 또한 음성 인코더와 대형 언어 모델(LLM) 디코더를 결합한 새로운 중단 감지 모델을 두 단계 학습(paradigm)으로 최적화하여, 기존 VAD 기반·엔드‑투‑엔드 방식보다 세 배 가량 APT를 감소시키는 성능을 입증한다.
저자: Kangxiang Xia, Bingshen Mu, Xian Shi
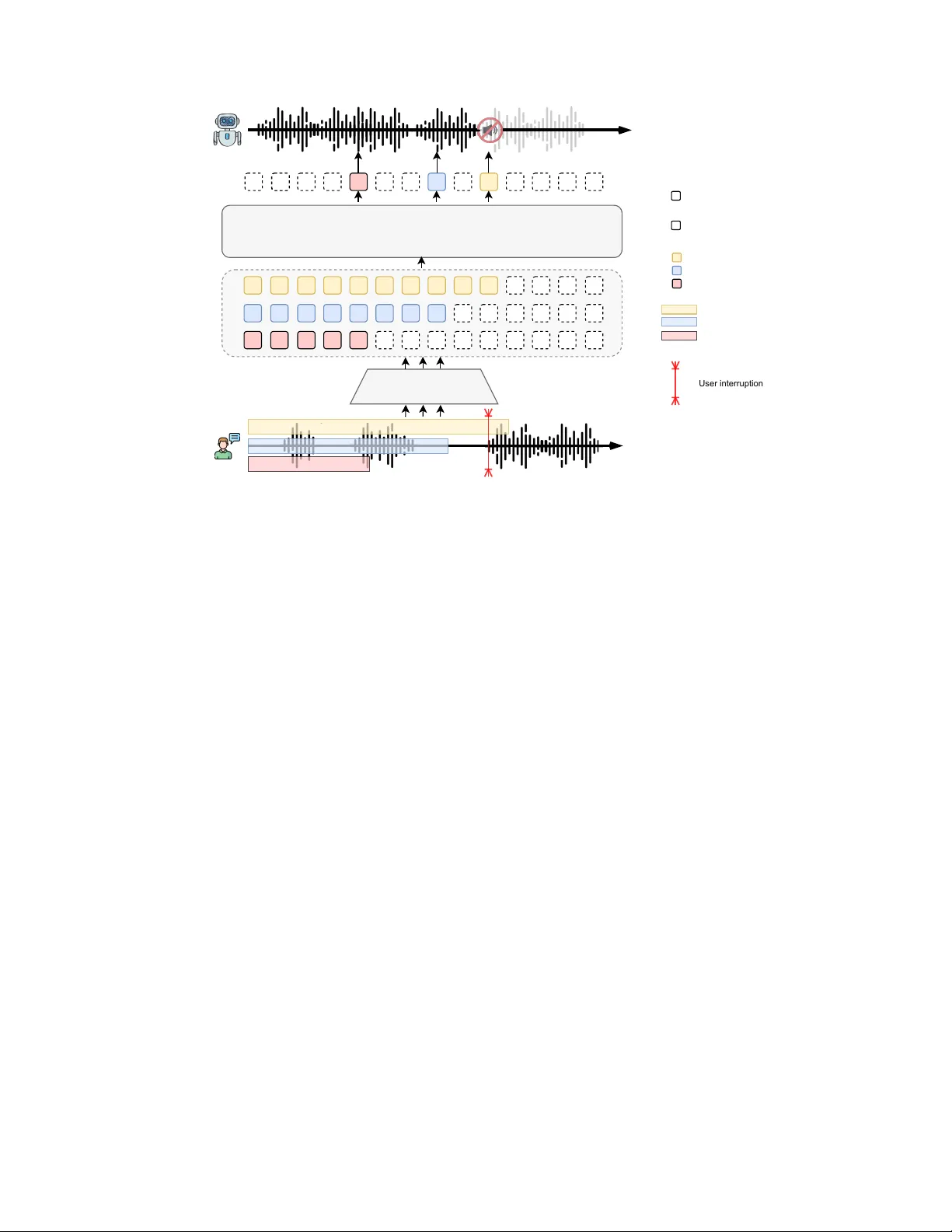
본 논문은 인간‑인간 대화에서 발생하는 중단(interruption) 현상을 정확히 감지하기 위한 새로운 연구 프레임워크를 제시한다. 먼저, 기존 연구가 주로 합성 음성·텍스트에 의존해 실제 대화의 복잡한 타이밍·프로소디·감정을 반영하지 못한다는 문제점을 지적하고, 이를 해결하기 위해 실세계 대화를 10시간 이상 수집한 SID‑Bench이라는 벤치마크를 구축한다. 데이터는 중국어와 영어를 각각 1,800개 인스턴스로 구성하며, 중단 시작 시점이 대화 초반에 나타나는 경우, 중간에 나타나는 경우, 백채널·무음·노이즈 등 비중단 상황을 균형 있게 포함한다.
어노테이션은 두 단계 파이프라인으로 진행된다. 텍스트 단계에서는 강력한 LLM(Qwen‑max, Qwen‑plus)을 활용해 사용자의 발화에 의미적 전환이 일어나는 정확한 단어에 태그를 삽입한다. 이어서 Kaldi 기반 강제 정렬을 통해 해당 단어의 시작 음소 시점을 추출하고, 텍스트 태그와 시간 정보를 결합해 의미‑시간적 ground‑truth를 만든다. 이 방식은 순수 음성 기반 VAD가 놓치기 쉬운 미묘한 의미 변화를 포착하면서도, 타임스탬프의 정확성을 보장한다.
평가 지표로는 기존 연구에서 사용되던 FIR(False Interruption Rate)과 IRL(Interruption Response Latency)를 그대로 채택하되, 두 지표를 하나의 종합 점수인 평균 패널티 시간(APT)으로 통합한다. APT는 True Positive에 대해 IRL만큼, False Positive에 대해 전체 발화 길이만큼, False Negative에 대해 불필요 청취 구간 길이만큼, True Negative에 대해 0 패널티를 부여한다. 이렇게 정의된 APT는 시스템이 “빠르게 멈추면서도 실수를 최소화”하는 정도를 직관적으로 나타내며, 속도와 안정성 사이의 트레이드오프를 정량화한다.
제안 모델은 멀티모달 구조를 채택한다. Audio Transformer(AuT)를 이용해 원시 음성을 고차원 임베딩으로 변환하고, 이를 Qwen‑0.6b LLM 디코더에 전달한다. LLM은 언어적 컨텍스트와 음성 임베딩을 동시에 처리해, 현재 누적된 프레임이 중단 의도를 포함하는지 이진 분류한다. 학습은 두 단계로 진행된다. 1) 대규모 ASR 데이터에 대해 사전 학습하여 음성‑텍스트 정렬 능력을 확보하고, 2) SID‑Bench과 유사한 양식의 중단 라벨이 포함된 데이터셋으로 미세 조정한다. 미세 조정 시에는 인터럽션 시점을 기준으로 다양한 길이의 오디오 세그먼트를 랜덤하게 추출하고, 세그먼트 끝이 T_break 이전이면 ‘비중단’, 이후이면 ‘중단’으로 라벨링한다. 이 과정에서 시간적 연속성을 유지하기 위해 슬라이딩 윈도우와 가중치 샘플링을 적용, 실시간 추론 시 누적 프레임을 지속적으로 평가한다.
실험에서는 제안 모델을 기존 VAD 기반 “trigger‑happy” 시스템, 최신 엔드‑투‑엔드 중단 감지 모델, 그리고 여러 베이스라인 LLM 변형과 비교하였다. 결과는 다음과 같다. FIR 측면에서 제안 모델은 VAD 기반 시스템 대비 70% 이상 감소했으며, 엔드‑투‑엔드 모델 대비 45% 감소했다. IRL 측면에서도 평균 지연 시간이 기존 모델보다 45% 짧았다. 종합 지표인 APT에서는 베이스라인 대비 약 3배 낮은 값을 기록, 속도와 정확성 모두에서 현저히 우수함을 입증했다. 추가 분석에서는 언어별 성능 차이(중국어와 영어 모두에서 일관된 개선), 백채널·노이즈에 대한 강인성(오탐률이 거의 0에 수렴), 그리고 어노테이션 품질이 모델 성능에 미치는 영향(LLM 기반 태깅 정확도가 높을수록 APT 감소) 등을 상세히 제시한다.
논문의 기여는 크게 네 가지이다. 첫째, 실제 인간 대화를 기반으로 한 의미‑인식 중단 감지 벤치마크 SID‑Bench을 공개함으로써 연구 커뮤니티에 표준 평가 데이터를 제공한다. 둘째, 오탐과 지연을 시간 비용으로 통합한 APT 지표를 제안해, 시스템 설계 시 속도·안정성 트레이드오프를 명확히 측정한다. 셋째, Audio Transformer와 경량 LLM을 결합한 멀티모달 중단 감지 모델과 두 단계 학습 파라다임을 설계해, 의미적 이해와 실시간성을 동시에 달성한다. 넷째, 광범위한 실험을 통해 현존 최고 수준의 성능을 입증하고, 향후 연구 방향으로 다언어·다도메인 확장, 실시간 서비스 통합, 사용자 주관적 만족도 평가 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기