지식 정제형 이중 컨텍스트 인식 네트워크로 부분 관련 비디오 검색 혁신
KDC‑Net은 텍스트와 영상 양쪽에서 계층적 의미와 동적 시간 정보를 명시적으로 모델링하고, CLIP 기반 교사 모델의 출력을 시간 연속성을 고려해 정제한 뒤 학생 모델에 전달한다. 계층적 의미 집계(HSA), 동적 시간 주의(DTA), 지식 정제(distillation) 세 모듈을 결합해 TVR·ActivityNet Captions 벤치마크에서 R@1~R@100 및 SumR 모두 기존 최첨단을 크게 앞선다.
저자: Junkai Yang, Qirui Wang, Yaoqing Jin
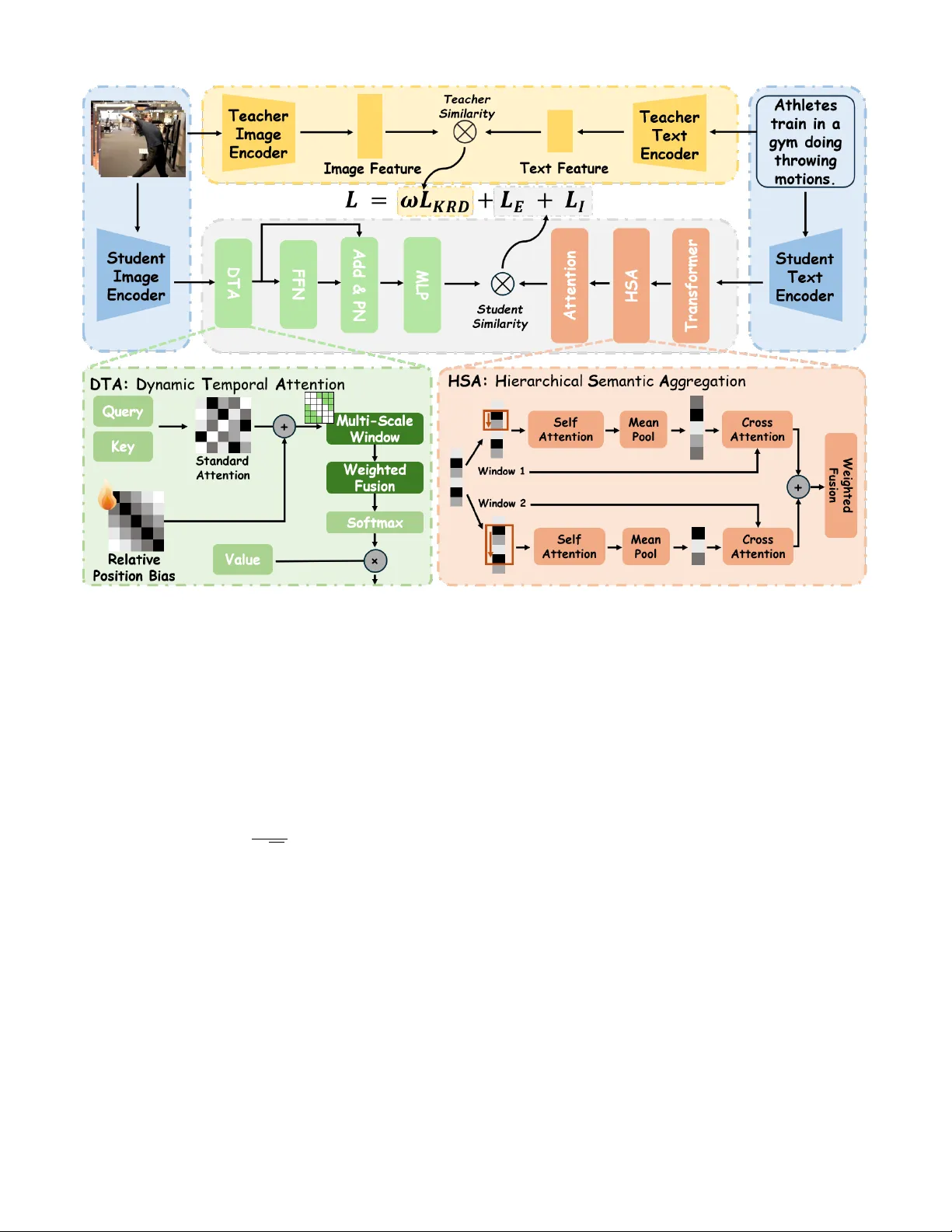
본 연구는 부분 관련 비디오 검색(PRVR)이라는 새로운 과제에 초점을 맞추었다. PRVR은 사용자가 제시한 자연어 질의와 일치하는 비디오의 특정 구간을 찾아내는 작업으로, 기존 텍스트‑투‑비디오 검색이 전체 클립을 전제로 하는 것과 달리 비디오 전체에서 부분적인 일치를 찾아야 하는 어려움을 안고 있다. 이러한 문제는 (1) 텍스트와 비디오 구간 사이의 정보 밀도 차이, (2) 기존 자기주의 기반 모델이 시간적 연속성과 지역적 의미에 충분히 주목하지 못한다는 두 가지 근본적인 한계에서 비롯된다. 이를 해결하기 위해 저자들은 KDC‑Net(Knowledge‑Refined Dual Context‑Aware Network)이라는 세 가지 핵심 모듈을 설계하였다.
첫 번째 모듈인 Hierarchical Semantic Aggregation(HSA)은 텍스트 인코더에 삽입되어, 단어 수준 토큰을 그대로 평탄화하는 대신 다중 스케일 슬라이딩 윈도우를 통해 구문(phrase) 수준의 의미를 추출한다. 각 구문에 대해 다중 헤드 어텐션과 평균 풀링을 적용해 로컬 컨텍스트를 캡처하고, 구문‑별 컨텍스트 벡터 a⁽ᵐ⁾ᵢ를 계산한다. 이후 학습 가능한 스케일 가중치 β⁽ᵐ⁾를 이용해 여러 스케일의 컨텍스트를 가중합함으로써, 원래 단어 표현 qᵢ에 풍부한 계층적 의미를 주입한다. 이 과정은 단순히 토큰을 나열하는 기존 Transformer와 달리, 구문 구조를 명시적으로 모델링함으로써 복합 질의에서 핵심 어구가 희석되는 문제를 완화한다.
두 번째 모듈인 Dynamic Temporal Attention(DTA)은 영상 인코더에 적용된다. 표준 Transformer 어텐션은 순열 불변성 때문에 시간 순서를 명시적으로 인코딩하지 못한다. DTA는 (i) 상대 위치 편향 bᵢⱼ을 학습해 프레임 간 거리 정보를 직접 반영하고, (ii) 반경 U를 갖는 다중 스케일 윈도우 마스크 mᵢⱼ을 도입해 어텐션 범위를 지역적으로 제한한다. 이를 통해 짧은 동작과 장기적 흐름을 동시에 포착하면서 연산 효율성을 확보한다. 또한 Purification Normalization(PN)이라는 경량 정규화 기법을 추가해 프레임 간 자기유사도 행렬을 이용해 중복 정보를 제거, 표현의 차별성을 높인다.
세 번째 모듈은 Knowledge Refinement Distillation(KRD)이다. 기존 CLIP 기반 지식 증류는 이미지‑텍스트 정합에 최적화된 교사 모델을 그대로 사용해 비디오에 적용하면 노이즈가 많이 포함된다. KRD는 교사 모델이 생성한 프레임‑쿼리 유사도 시퀀스 Sₜ에 대해 평균 µₛ와 표준편차 σₛ를 기반으로 동적 임계값 τ_high = µₛ+σₛ, τ_low = µₛ−σₛ를 정의한다. 연속적인 프레임 구간이 모두 τ_high를 초과하면 고신뢰 구간으로 간주해 점수를 α만큼 상승시키고, 모두 τ_low 이하이면 저신뢰 구간으로 간주해 점수를 감소시킨다. 여기서 α는 µₛ와 σₛ를 조합해 조정 강도를 자동으로 결정한다. 정제된 시퀀스 ˜sᵢ를 목표 분포로 삼아 학생 모델은 KL‑divergence 손실 L_KRD를 최소화한다. 이 과정은 교사 신호의 잡음을 억제하고, 시간 연속성을 활용해 보다 신뢰성 있는 지도 정보를 제공한다.
학습 단계에서는 학생 모델을 탐색(Exploration)과 상속(Inheritance) 두 개의 독립 브랜치로 구성하고, 각각 InfoNCE와 Triplet Ranking 손실을 적용한다. 전체 손실은 L = L_E + L_I + w·L_KRD 형태이며, w는 에폭이 진행될수록 지수적으로 감소한다. 추론 시에는 두 브랜치의 유사도 점수를 가중합해 최종 검색 점수 Sim(Q,V)를 산출한다.
실험은 TVR과 ActivityNet Captions 두 공개 데이터셋에서 수행되었다. 평가 지표는 Recall@K (K=1,5,10,100)와 SumR을 사용한다. KDC‑Net은 TVR에서 SumR 184.9, R@1 15.4%를 기록해 기존 최고 성능인 DL‑DKD(147.6)와 GMMFormer(146.0)를 크게 앞섰으며, ActivityNet Captions에서도 SumR 148.5, R@1 8.1% 등 전반적인 성능 향상을 보였다. Ablation 실험에서는 HSA, DTA, KRD 각각을 제거했을 때 SumR이 평균 3~5% 포인트 감소하는 등 각 모듈의 기여도가 입증되었다.
종합적으로 KDC‑Net은 (1) 텍스트의 구문 구조를 계층적으로 강화, (2) 영상의 시간적 연속성을 고려한 지역적 어텐션, (3) 교사‑학생 학습에서 시간 연속성을 활용한 신호 정제라는 세 축을 통해 PRVR 과제에서 기존 한계를 뛰어넘는 성능을 달성하였다. 향후 연구에서는 HSA의 스케일 선택 자동화, DTA의 가변 윈도우 설계, 그리고 비디오 전용 대형 교사 모델을 활용한 KRD 확장이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기