AI가 만든 허위 판례, 변호사의 책임과 기술적 위험
본 논문은 변호사가 생성형 AI를 활용할 때 발생하는 ‘허위 판례·법조문 생성’ 현상을 물리학적 분석을 통해 결정론적 메커니즘으로 규명한다. AI가 특정 입력(특히 법리적 난점)과 자체 상태가 임계점을 초과하면 신뢰성 있는 답변에서 권위 있는 허위 정보로 전이되는 ‘티핑 포인트’를 제시하고, 이를 바탕으로 변호사의 전문성·주의·성실·감독 의무에 대한 법적·윤리적 함의를 제시한다.
저자: Dylan J. Restrepo, Nicholas J. Restrepo, Frank Y. Huo
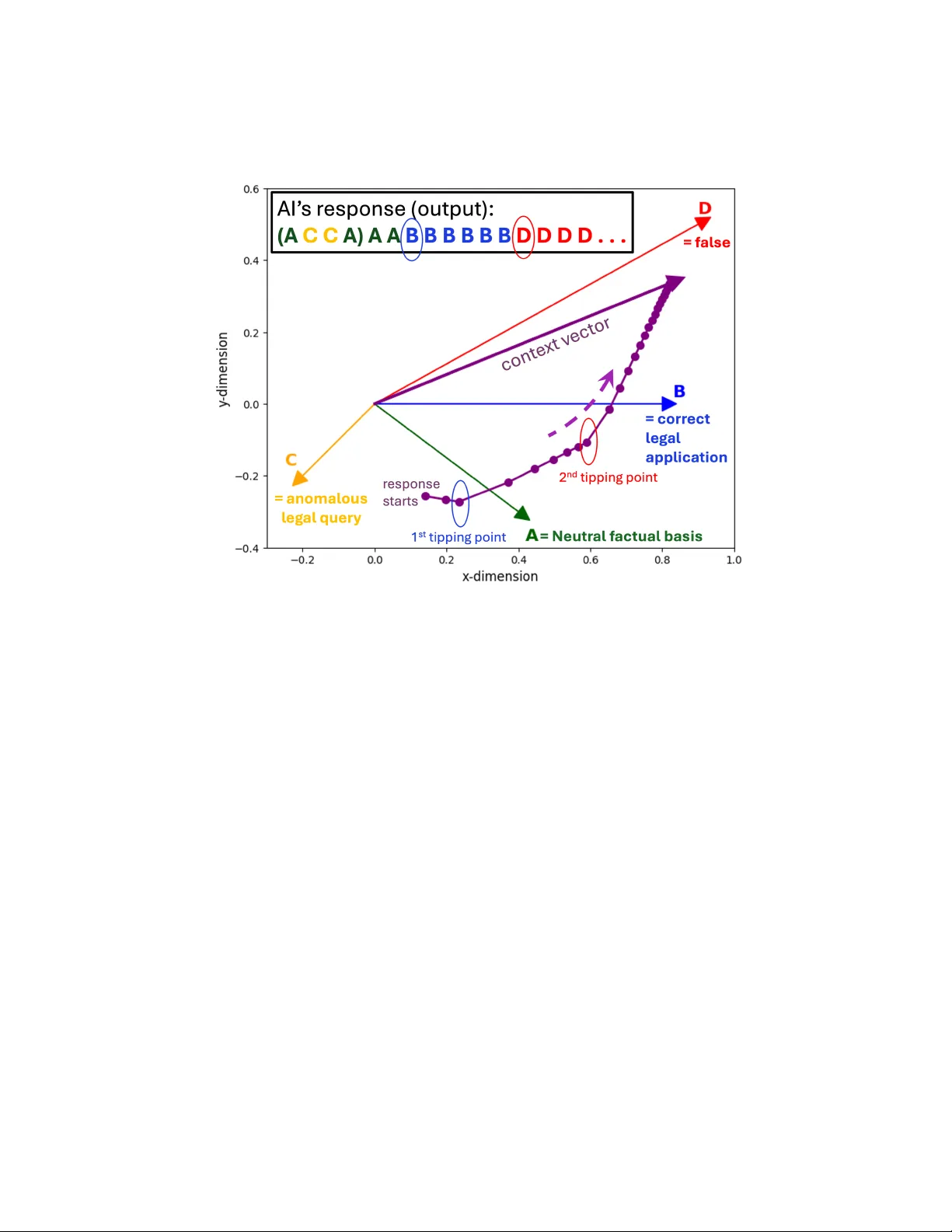
이 논문은 변호사가 생성형 인공지능(Generative AI)을 활용하면서 겪는 ‘허위 판례·법조문 생성’이라는 위험을 과학적·법학적 두 축에서 분석한다. 서론에서는 최근 미국·호주·캐나다 등 여러 관할구역에서 변호사가 AI가 만든 가짜 판례를 인용해 제소·제출한 사례(Mata v. Avianca 등)를 소개하고, 이러한 사건이 단순히 ‘AI가 헛소리를 내는’ 수준을 넘어 변호사의 윤리·전문성 위반으로 이어진다는 점을 강조한다. 특히, 초기 오류가 AI에 의해 발생하고, 이후 변호사가 이를 은폐·고집함으로써 ‘악의적 허위 진술’까지 확대되는 이중‑실패 메커니즘을 지적한다.
핵심 기술 분석에서는 트랜스포머 모델의 self‑attention을 물리학의 다중 스핀 열역학 시스템에 매핑한다. 토큰은 스핀 벡터 Ŝ 로, 토큰 간 점곱은 스핀‑스핀 상호작용 에너지, softmax은 볼츠만 분포와 유사하게 해석된다. 모델은 하나의 효과적인 attention head와 greedy decoding만을 고려한 ‘유효 스핀 헤드 모델’로 단순화한다. 네 종류의 콘텐츠 스핀을 정의한다: Ŝ_A(중립 사실), Ŝ_B(정확한 법리), Ŝ_C(희소·불확실한 법리 질문), Ŝ_D(허위 법조문).
논문은 ‘티핑 포인트’라는 개념을 도입한다. 변호사가 AI에 불확실하거나 새롭고 판례가 적은 법리 질문(C‑type)을 입력하면, 컨텍스트 벡터 N(t) 가 점차 Ŝ_C 방향으로 이동한다. 이때 Ŝ_D·N(t) 가 Ŝ_B·N(t) 를 초과하면, 에너지 최소화 원칙에 따라 모델은 정확한 법리(B‑type) 대신 허위 법조문(D‑type)을 출력한다. 이 전이는 계산적으로 예측 가능하며, 임계값을 넘는 시점은 수학적으로 도출될 수 있다.
시뮬레이션에서는 실제 Mata 사건을 모방한 ACCA 프롬프트를 사용한다. 초기에는 A‑type 토큰이 반복되어 사실을 나열하고, 이후 B‑type 토큰으로 전이해 정확한 법리 분석을 제공한다. 변호사는 이 단계에서 AI의 신뢰성을 확신하게 된다. 그러나 C‑type 토큰이 지속적으로 컨텍스트를 끌어당겨 결국 D‑type 토큰, 즉 가짜 판례(‘Varghese v. China Southern Airlines’)를 생성한다. 이 과정은 ‘오랜 정확한 출력이 위험을 감소시키는 것이 아니라 오히려 위험을 증가시킨다’는 역설을 보여준다.
법적·윤리적 논의에서는 이 결정론적 티핑 메커니즘을 ‘예측 가능한 엔지니어링 위험’으로 재분류한다. 변호사는 AI가 단순히 ‘우연히’ 오류를 내는 것이 아니라 구조적으로 허위 생성 가능성을 내포하고 있음을 인식해야 한다. ABA 모델 규칙 1.1(전문성)에서는 변호사가 최신 기술의 위험을 이해하고, 특히 티핑 포인트와 같은 특정 실패 메커니즘을 숙지해야 함을 강조한다. 1.3(성실)에서는 모든 AI‑생성 출력에 대해 독립적인 검증(특히 인용·판례 검증)이 필수이며, 시뮬레이션이 보여준 바와 같이 초기 정확한 출력이 뒤따라 허위가 나타날 위험이 있기에 표면적 검토만으로는 충분하지 않다. 3.3(법정에 대한 성실)에서는 허위 사실을 알게 된 순간 즉시 시정·고지해야 하며, 이를 무시하고 제출을 지속하면 윤리 위반이 된다. 5.1·5.3(감독)에서는 사무소 차원의 정책·교육이 필요하고, 감독 변호사는 부하 직원이 AI를 사용할 때 티핑 포인트에 대한 인식과 검증 절차를 갖추지 못하면 감독 의무 위반이 된다.
결론에서는 현재 제품 책임법리(설계 결함·경고 의무)가 AI 도구에도 적용될 가능성을 탐색한다. 미국 뉴욕 사례(Nazario v. ByteDance)처럼 알고리즘 설계 결함에 대한 손해배상 청구가 인정될 조짐이 보이지만, 아직 AI‑법조문 오류에 대한 직접적인 판례는 부족하다. 따라서 변호사와 법률 사무소가 스스로 위험을 관리하는 것이 현실적인 방안이며, 논문은 구체적인 검증 프로토콜(예: 자동 인용 검증 API와 인간 검토 병행)과 교육 커리큘럼을 제안한다. 전반적으로 이 논문은 AI가 법률 실무에 미치는 위험을 물리학적 모델을 통해 결정론적으로 규명하고, 이를 바탕으로 변호사의 전문성·성실·감독 의무를 재정의함으로써 향후 규제·윤리 가이드라인 수립에 중요한 학술적·실무적 기초를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기