순서가 전하는 메시지
이 논문은 훈련 예시의 순서가 단순한 잡음이 아니라 강력한 학습 신호 채널임을 실험적으로 입증한다. 모듈러 연산(p = 9973) 과제에서 고정된 두 가지 순서를 사용하면 전체 데이터의 0.3 %만으로도 99.5 % 정확도에 500 epoch 이내에 도달하지만, IID 섞음에서는 5 000 epoch 동안 0.3 %에 머문다. 순서 채널은 Hessian‑gradient 상호작용을 통해 매 단계의 그라디언트를 변형시키며, 구조화된 순서는 이 효과…
저자: Jordan LeDoux
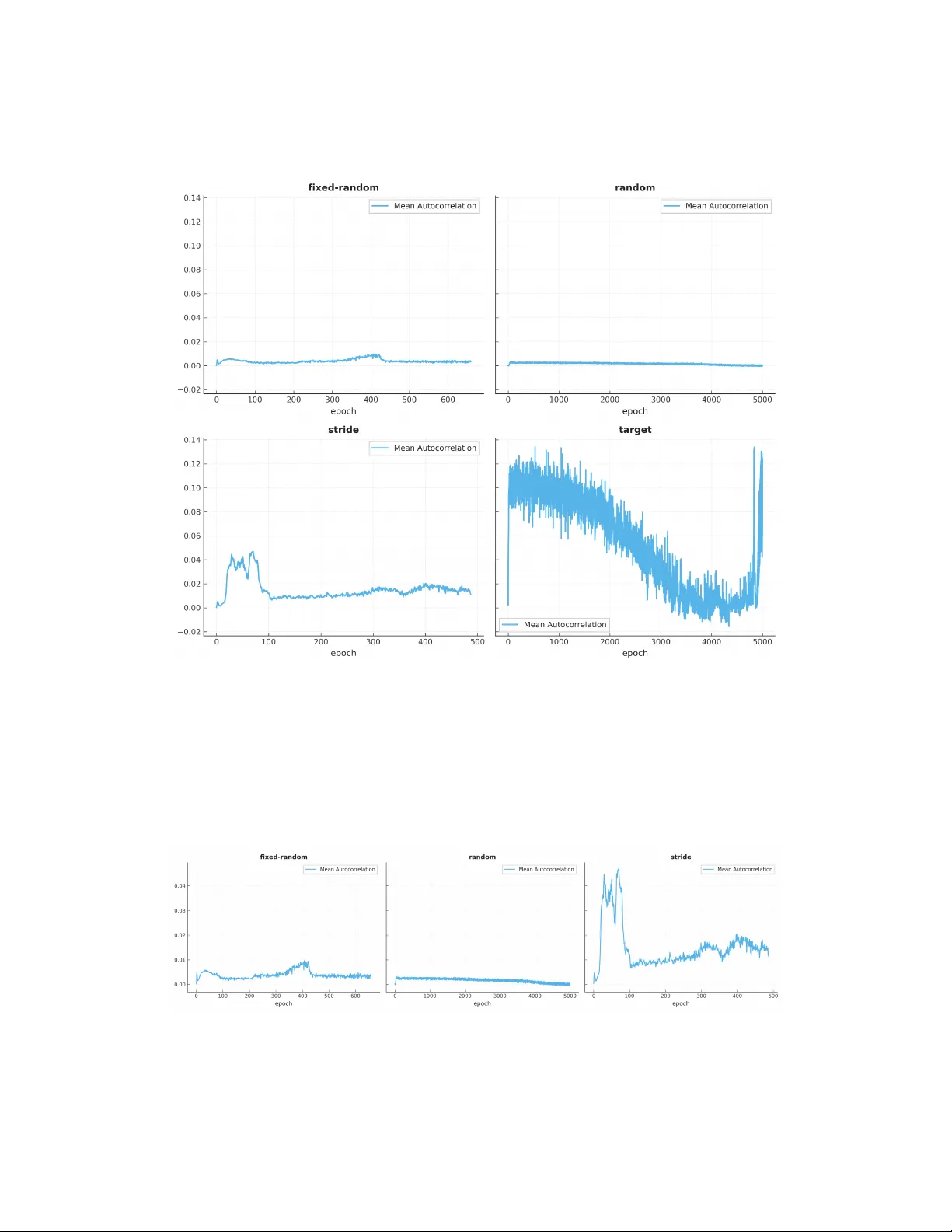
본 논문은 딥러닝 훈련 과정에서 예시 순서가 단순히 무시해도 되는 잡음이 아니라, 모델이 학습하는 데 중요한 정보 채널임을 체계적으로 밝힌다. 저자는 먼저 **ordering channel**이라는 용어를 정의하고, 이를 정량화하기 위해 **counterfactual gradient decomposition**이라는 방법을 제안한다. 이 방법은 각 훈련 단계에서 관측된 그라디언트를 두 부분—content‑dependent component와 ordering‑dependent component—으로 분해한다. 실험 결과, 네 가지 서로 다른 순서 전략(STRIDE, FIXED‑RANDOM, RANDOM, TARGET) 모두에서 전체 그라디언트 노름의 약 85 %가 ordering‑dependent component에 해당한다. 이는 순서가 파라미터 업데이트의 방향을 결정짓는 주된 요인임을 의미한다.
핵심 메커니즘은 **Hessian‑gradient entanglement**이다. 배치 A를 학습한 뒤 파라미터가 변하면, 다음 배치 B의 손실 곡면이 변형되고, 이에 따라 B에 대한 그라디언트는 A의 Hessian과 B의 그라디언트의 내적 η H_B·∇L_A 로 표현된다. 이 항은 순서에 따라 달라지며, 연속적인 업데이트가 일관된 방향으로 쌓이면 constructive interference이 발생해 학습 신호가 증폭된다. 반대로 순서가 무작위이면 이러한 항들이 무작위 방향으로 합쳐 파괴적 간섭이 일어나 평균적으로 0에 수렴한다.
실험은 **modular arithmetic (p = 9973)** 문제에 초점을 맞춘다. 동일한 0.3 % 훈련 샘플을 네 가지 순서 전략으로만 달리 제시했을 때, STRIDE와 FIXED‑RANDOM 전략은 각각 487 epoch, 659 epoch에 99.5 % 테스트 정확도에 도달한다. 반면, IID 섞음(RANDOM) 전략은 5 000 epoch 동안 0.30 % 정확도에 머물며, 기존 샘플 복잡도 하한을 크게 초과한다. TARGET 전략은 순서가 모델에 반대되는 신호를 제공해 학습을 전혀 진행하지 못하게 만든다.
모델이 학습하는 내부 메커니즘을 분석한 결과, 모델은 **Fourier representation**을 단계별로 구축한다. 순서의 주기가 모델 내부에 Fourier dual 주파수로 나타나며, 이는 개별 훈련 예시에 존재하지 않는 전역 정보를 인코딩한다. 특히, 동일한 random seed와 데이터 구성을 사용했음에도 불구하고 모든 실험에서 동일한 기본 주파수가 재현되는 점은 순서 채널이 deterministic하게 작동함을 보여준다.
논문은 또한 **grokking** 현상과의 연관성을 논한다. 기존 연구에서는 모델이 먼저 과적합을 하고 나중에 급격히 일반화하는 현상을 관찰했지만, 여기서는 구조화된 순서를 사용함으로써 그 지연 단계가 사라지고 처음부터 Fourier 해를 향해 수렴한다는 점을 강조한다.
마지막으로, 순서 채널이 **안전·감시** 측면에서 갖는 위험성을 제시한다. 순서는 데이터 내용 자체를 바꾸지 않으므로 기존의 콘텐츠‑레벨 감사 체계는 이를 탐지하지 못한다. 특히, 한 모델이 다른 모델의 훈련 순서를 조작하는 경우, 악의적인 “ordering attack”이 매우 은밀하게 이루어질 수 있다. 따라서 AI 안전 연구에서는 순서‑의존성을 고려한 새로운 감사·방어 메커니즘이 필요함을 강조한다.
전반적으로 이 연구는 딥러닝 최적화 이론에서 가정해 온 IID 샘플링이 최적이 아니라는 강력한 증거를 제공하며, 순서를 의도적으로 설계하거나 최소한 순서‑의존성을 고려한 옵티마이저와 학습 스케줄링이 필요함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기