시간연속 연합학습을 위한 논리 기반 검증 방어 LOGSAFE
초록
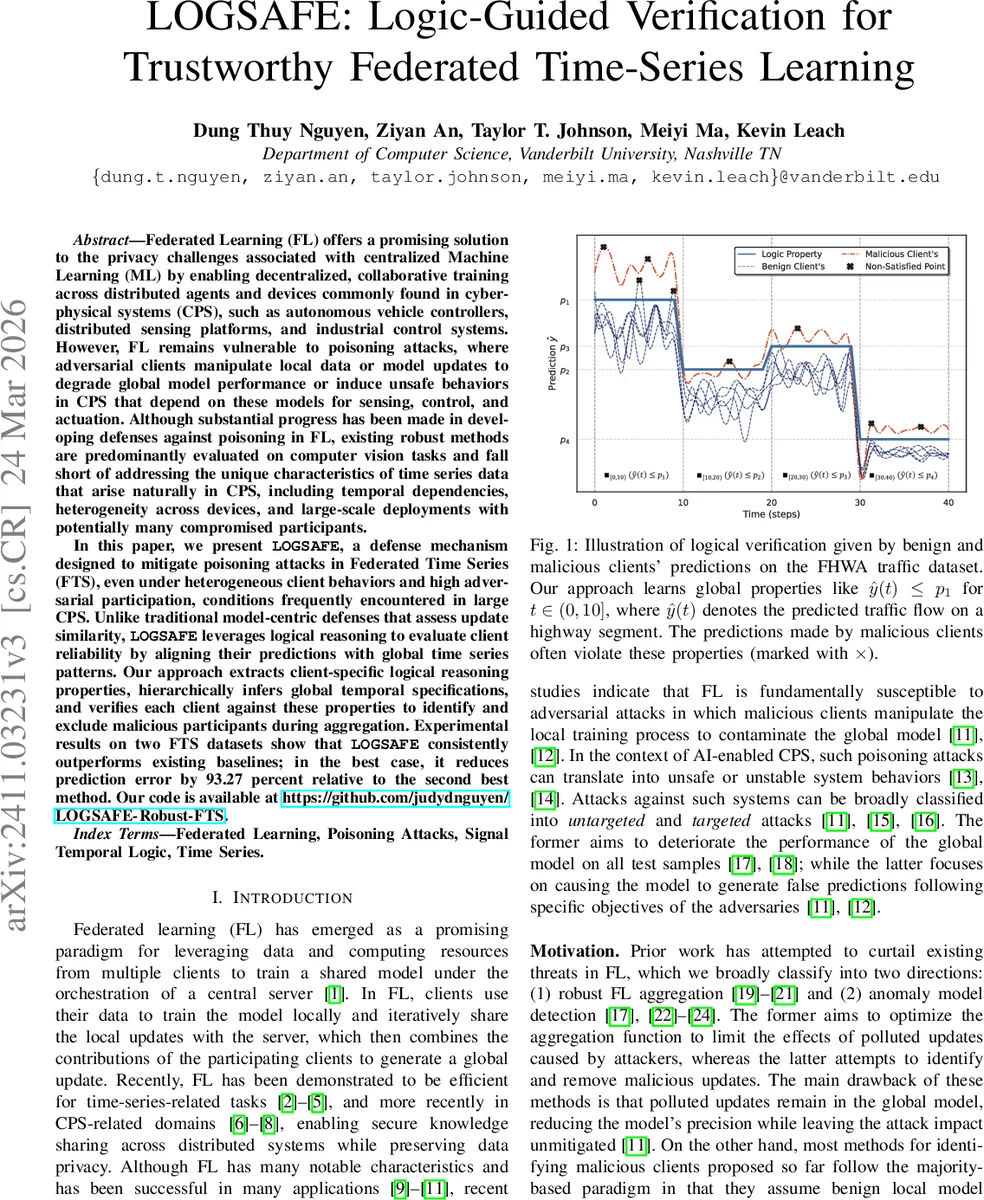
LOGSAFE는 사이버‑물리 시스템에 적용되는 연합 시계열 학습에서 발생하는 데이터 및 모델 중독 공격을 방어하기 위해, 클라이언트별 예측 결과에 대한 Signal Temporal Logic(STL) 속성을 자동으로 추출·클러스터링하고, 전역 논리 사양과의 일치도를 검증하여 악성 클라이언트를 식별·제거한다. 실험 결과, 기존 업데이트‑유사도 기반 방어에 비해 최대 93.27%의 오류 감소를 달성한다.
상세 분석
본 논문은 연합 학습(Federated Learning, FL)이 사이버‑물리 시스템(CPS)에서 프라이버시를 보호하면서 대규모 시계열 데이터를 학습하는 데 유용하지만, 악의적인 클라이언트가 로컬 데이터 혹은 모델 업데이트를 변조해 전역 모델을 오염시키는 중독 공격에 취약함을 지적한다. 기존 방어 기법은 주로 이미지·정적 데이터에 초점을 맞추어 업데이트 간 유사성을 기반으로 악성 업데이트를 탐지한다. 그러나 시계열 데이터는 시간적 의존성, 비정상성, 클라이언트 간 이질성이 강해 정상 업데이트조차 크게 차이날 수 있어, 평균·중위수 기반 방법은 효과가 떨어진다. LOGSAFE는 이러한 한계를 극복하기 위해 STL이라는 형식 논리 체계를 도입한다. 각 클라이언트의 예측 시퀀스에서 반복적으로 나타나는 “예측값이 일정 임계값을 초과하면 일정 시간 내에 다시 하한 이하로 떨어진다”와 같은 시간적 제약을 자동으로 추출하고, 추출된 STL 공식의 파라미터(임계값, 시간 구간, 연산자)를 기반으로 비지도 클러스터링을 수행한다. 클러스터 내에서 유사한 논리 속성을 가진 클라이언트를 그룹화함으로써 전역 논리 사양을 계층적으로 추정한다. 이후 각 라운드에서 클라이언트가 제출한 모델이 전역 사양을 만족하는 정도를 검증하고, 만족도가 낮은 클라이언트를 신뢰 점수 낮게 부여하거나 집계에서 제외한다. 이 과정은 모델 파라미터 자체가 아니라 예측 행동에 초점을 맞추어, 악성 클라이언트가 업데이트를 정상적으로 보이게 위장하더라도 논리적 일관성 위반을 통해 탐지한다. 실험에서는 두 개의 실제 시계열 데이터셋(고속도로 교통 흐름, 전력 부하)과 다양한 공격 시나리오(무작위 Byzantine, 목표형 백도어, PGD 기반 정밀 공격)를 사용했으며, Krum, Median, FLTrust 등 기존 방어와 비교해 평균 예측 오차를 93.27%까지 감소시켰다. 또한 높은 비율(>30%)의 악성 클라이언트가 존재하는 상황에서도 안정적인 성능을 유지한다. 논문은 논리 기반 검증이 시계열 연합 학습에 있어 투명성과 신뢰성을 동시에 제공할 수 있음을 실증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기