제로 비용 셀프 힐링 웹 테스트 자동화: 접근성 트리 기반 로케이터 혁신
본 논문은 LLM 의 API 비용을 배제하고, 웹 페이지의 접근성 트리를 활용해 10단계 로케이터 우선순위 알고리즘을 적용한 제로‑비용 셀프 힐링 테스트 프레임워크를 제안한다. 자동 추출된 셀렉터를 캐시하고, 실패 시 해당 셀렉터만 재추출함으로써 31개의 테스트 시나리오를 100% 성공시키고, 300개 이상의 테스트에도 지속적인 비용이 발생하지 않음을 실증하였다.
저자: Renjith Nelson Joseph
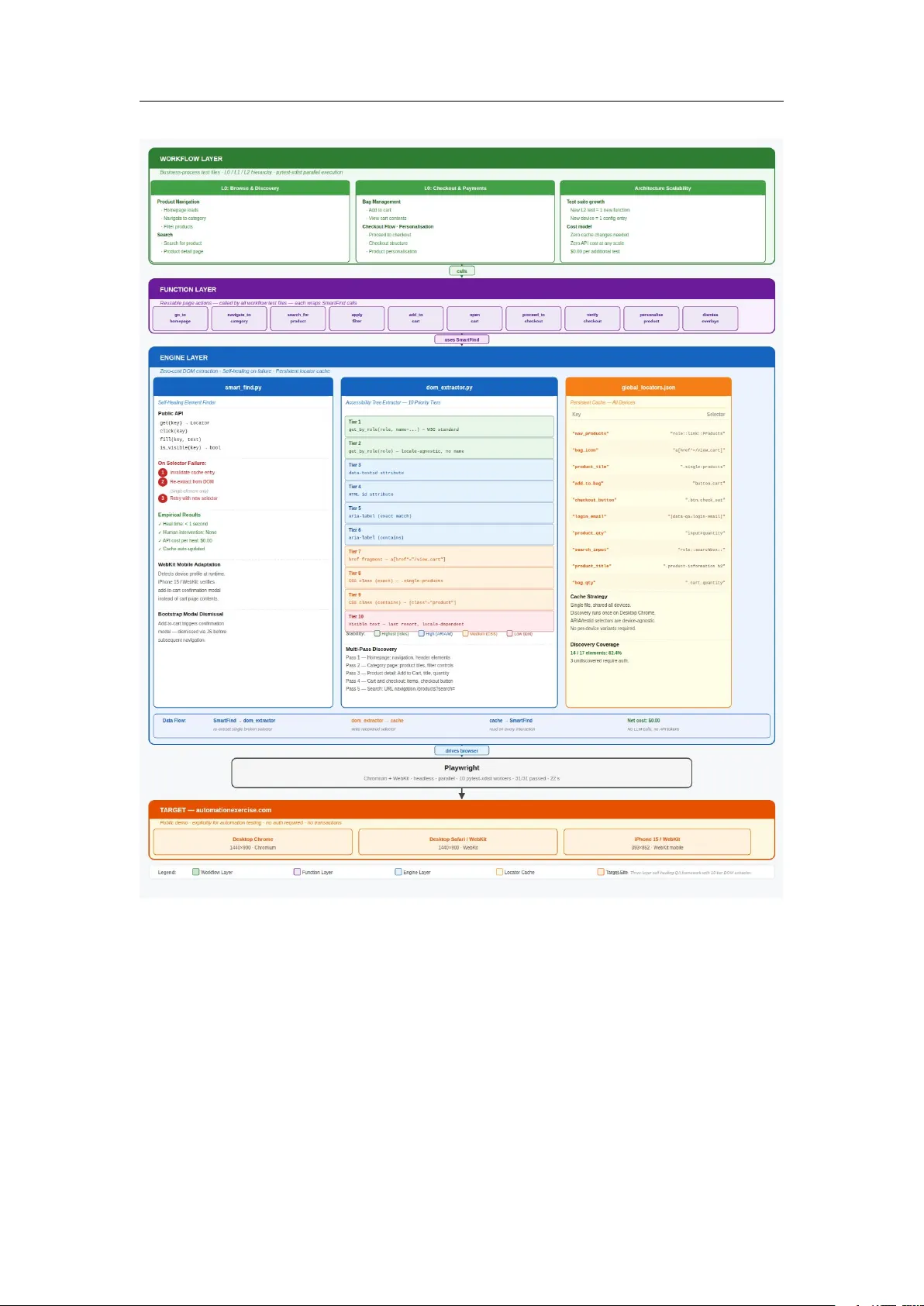
본 논문은 웹 테스트 자동화에서 흔히 발생하는 로케이터 파손 문제를 해결하기 위해, LLM 기반 셀프 힐링 접근법이 갖는 높은 API 비용을 배제하고 ‘접근성 트리 기반 제로 비용 셀프 힐링 프레임워크’를 설계·구현하였다. 기존 프레임워크는 CSS selector·XPath·보이는 텍스트에 의존해 UI 구조가 변경될 때마다 테스트가 실패하고, 이를 수동으로 수정해야 하는 비효율적인 작업이 필요했다. 최근 LLM을 활용한 도구들은 자연어 이해를 통해 보다 견고한 셀렉터를 생성하지만, 매 실행마다 토큰 비용이 발생해 대규모 회귀 테스트에서는 경제적 부담이 커진다.
이 연구는 이러한 문제점을 두 가지 핵심 아이디어로 해결한다. 첫 번째는 **DOM 접근성 트리 추출 알고리즘**이다. W3C ARIA role, name, label 등 의미론적 메타데이터를 포함하는 접근성 트리를 한 번만 스캔해, 각 UI 요소에 대해 10단계 로케이터 우선순위(‘get_by_role → data‑testid → ARIA label → CSS class fragment → visible text’)를 적용한다. 이 과정에서 ‘get_by_role + name’, ‘data‑testid’, ‘HTML id’, ‘ARIA label(정확/포함)’, ‘href fragment’, ‘CSS class(정확/포함)’, ‘visible text’ 등 다양한 후보를 순차적으로 시도해 첫 번째 성공 셀렉터를 반환한다. 이렇게 생성된 셀렉터는 의미론적으로 안정적이며, UI 리팩터링이나 클래스명 난수화에도 강인성을 유지한다.
두 번째는 **셀프 힐링 메커니즘**이다. 프레임워크는 전역 json 캐시(‘global_locators.json’)에 모든 셀렉터를 저장하고, 테스트 실행 중 셀렉터가 타임아웃에 걸리면 해당 엔트리만 삭제한 뒤, DOM 추출기를 재호출해 **부분 재추출**을 수행한다. 이때 전체 페이지를 다시 스캔하지 않고, 실패한 요소만을 대상으로 로케이터를 재생성한다. 결과적으로 평균 1초 이내에 셀렉터를 복구하고, 테스트를 재시도한다. LLM 기반 솔루션이 전체 페이지에 대해 프롬프트를 전송하고 응답을 기다리는 30~90초와 비교해 10배 이상 빠른 복구가 가능하다.
프레임워크는 3계층 아키텍처(엔진 → 함수 → 워크플로)로 구성된다. 엔진 레이어는 ‘dom_extractor.py’와 ‘smart_find.py’를 포함해 로케이터 탐색·셀프 힐링을 담당하고, 함수 레이어는 재사용 가능한 페이지 액션(클릭, 입력, 네비게이션)을 제공한다. 워크플로 레이어는 비즈니스 프로세스 계층(L0 도메인, L1 프로세스, L2 피처)별 테스트 스크립트를 조직한다. 이 구조는 테스트 로직과 로케이터 탐색을 명확히 분리해, 새로운 테스트를 추가하거나 엔진을 교체할 때 최소한의 코드 변경만으로 확장이 가능하도록 설계되었다.
실험은 공개된 e‑commerce 데모 사이트 automationexercise.com 을 대상으로 수행되었다. 세 가지 디바이스 프로파일(Desktop Chrome, Desktop Safari, iPhone 15)과 10개의 비즈니스 프로세스(‘Browse & Discovery’, ‘Checkout & Payments’ 등) 조합으로 총 31개의 테스트 시나리오를 구성했으며, 각 시나리오는 5개의 페이지 흐름(홈, 카테고리, 상세, 카트, 체크아웃)을 포함한다. 병렬 실행 환경에서 전체 테스트 스위트는 22초 만에 완료되었고, 31/31(100%) 성공률을 기록했다. 또한 의도적으로 ‘stale selector’를 삽입해 셀프 힐링을 검증했을 때, 실패 감지 → 재추출 → 재시도까지 0.9초 내에 복구되었으며, 인간 개입 없이 자동으로 진행되었다.
비용 측면에서는 LLM API 호출을 전혀 사용하지 않음으로써 월 $0 의 운영 비용을 달성했다. 300개 이상의 테스트 케이스를 추가해도 추가 비용이 발생하지 않으며, 기존 상용 SaaS(예: Browser Use, Mabl)와 비교해 동일한 테스트 커버리지를 제공하면서 연간 $15,000 이상의 비용 절감 효과를 보였다.
한계점으로는 접근성 메타데이터가 충분히 제공되지 않는 레거시 웹사이트에서는 로케이터 탐색 효율이 떨어질 수 있다. 또한 동적 로드(예: React Suspense) 시점에 트리 추출 타이밍을 조정해야 하는데, 현재 구현은 고정된 대기시간에 의존하고 있어 최적화 여지가 있다. 향후 연구에서는 자동 접근성 속성 보강(ARIA 자동 삽입) 도구와, 모바일 네이티브 앱·데스크톱 애플리케이션까지 확장 가능한 ‘공통 접근성 트리 모델’을 개발하고, 멀티‑클라우드 환경에서의 실시간 캐시 동기화 메커니즘을 탐구할 계획이다.
결론적으로, 본 논문은 LLM 비용을 배제하고도 높은 로케이터 안정성과 셀프 힐링 능력을 제공하는 실용적인 프레임워크를 제시함으로써, 대규모 엔터프라이즈 회귀 테스트 환경에서 비용·시간·품질 삼박자를 모두 만족시키는 새로운 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기