데이터 동화 역문제에서 부드러움 하이퍼파라미터 추정
본 논문은 베이지안 역문제에서 사전 분포의 부드러움(정규성) 하이퍼파라미터 α를 계층적 베이지안 모델로 추정한다. 메트로폴리스‑위드‑깁스(MwG)와 고차원에 강인한 pCN 샘플러를 결합해 Navier‑Stokes와 확률적 대류‑확산 방정식 두 사례에 적용하였다. 실험 결과, α를 공동 추정함으로써 부드러움 오설정에 따른 불확실성 과소평가를 크게 완화하고, 실제 α를 알 때와 동등한 예측 정확도를 달성한다.
저자: Baptiste Sim, oux, Nikolas Kantas
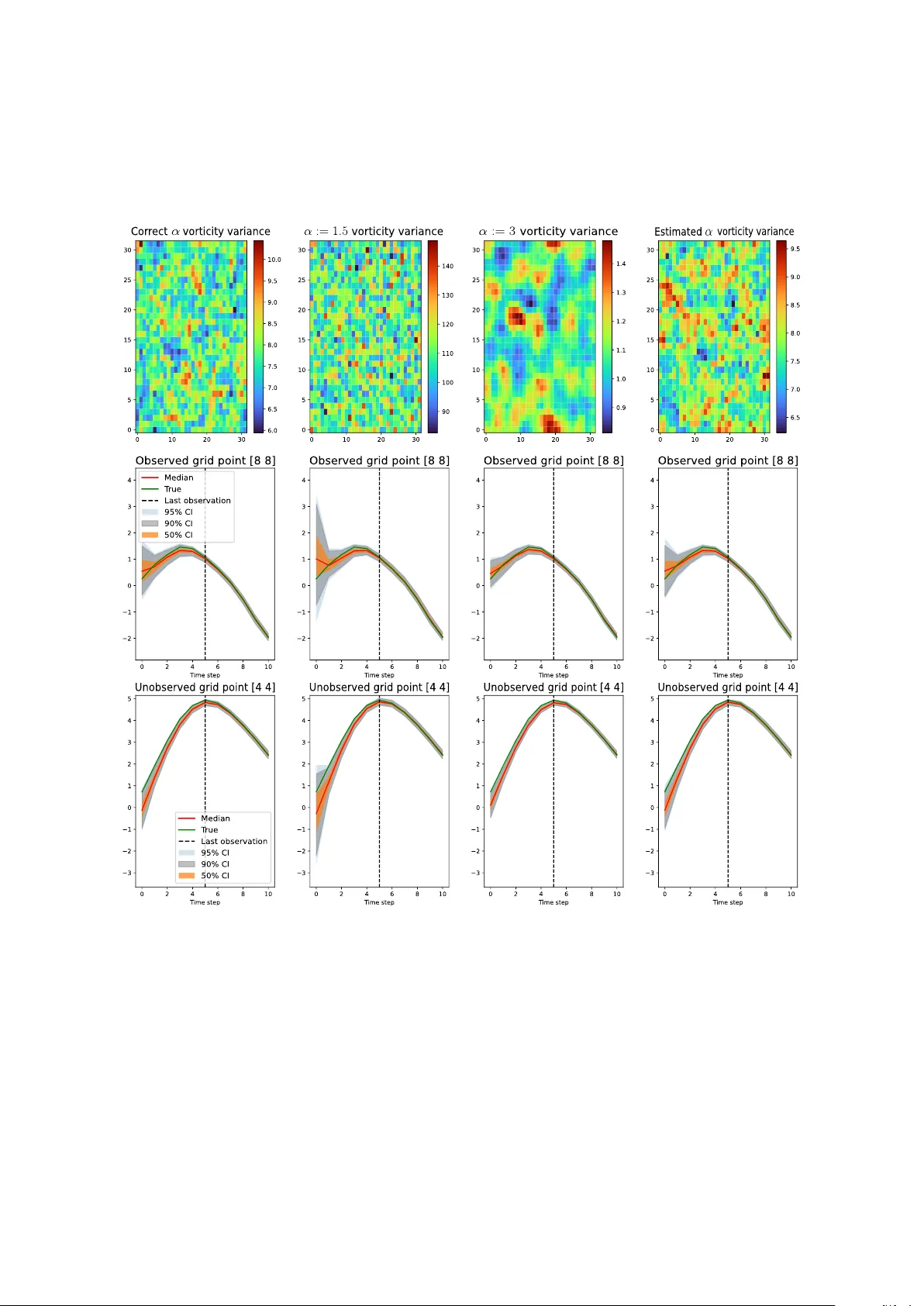
본 논문은 데이터 동화(data assimilation) 분야에서 베이지안 역문제의 핵심 요소인 사전 분포의 부드러움(정규성) 하이퍼파라미터 α를 계층적 베이지안 모델링을 통해 추정하는 방법론을 제시한다. 서론에서는 대기·해양·지구과학 등에서 PDE·SPDE 기반 동역학 모델과 고해상도 관측 데이터가 결합되는 상황을 설명하고, 기존 연구에서는 α를 고정하거나 경험적으로 선택하는 경우가 대부분이며, 이는 사후분포의 수렴 속도와 불확실성 정량화에 부정적 영향을 미친다고 지적한다.
문제 정의에서는 상태 변수 v(t,x)를 V라는 힐베르트 공간에 정의하고, 사전 µ₀를 Gaussian process 형태로 설정한다. Navier‑Stokes 사례에서는 공분산을 β²A^{‑α} 로, 여기서 A는 Stokes 연산자이며 α>½ 조건을 통해 A^{‑α} 가 trace‑class 가 되도록 보장한다. 확률적 대류‑확산 사례에서는 Whittle‑Matérn 공분산을 채택해 공간적 상관성을 모델링한다. 관측 모델은 격자점에서의 가우시안 잡음이 더해진 선형 관측식 yₙ,υ = v(x_υ, nδ) + τ ζₙ,υ 로 가정한다.
베이지안 추론은 사후분포 µ(v,θ,ϕ) ∝ l(y|v,ϕ) µ₀(v|θ) π(θ) π(ϕ) 로 정의되며, 여기서 θ=(α,β²) , ϕ는 관측·동역학 파라미터이다. 사후분포의 존재와 연속성을 보장하기 위해 α에 대한 하이퍼프라이어는 α>½ 를 위배하지 않는 균등분포를, β²에 대해서는 역감마분포를 사용한다.
계산 알고리즘은 고차원 상태 변수와 저차원 하이퍼파라미터를 동시에 샘플링하기 위해 Metropolis‑within‑Gibbs(MwG) 프레임워크를 채택한다. 상태 변수 업데이트는 사전과 사후가 동일한 형태를 유지하도록 설계된 preconditioned Crank–Nicolson(pCN) 메트로폴리스를 이용한다. pCN는 제안 분포가 사전과 동일하기 때문에 차원 저주에 강인하고, 메쉬 정밀도가 바뀌어도 수렴성이 유지된다. 하이퍼파라미터 단계에서는 각각의 파라미터에 대해 표준 Metropolis‑Hastings 제안을 사용하고, 비중심화 파라미터화(θ, ξ) 를 도입해 믹싱 효율을 높인다. 특히, α와 β²는 독립적인 하이퍼프라이어를 갖고, ξ는 표준 정규분포를 따르는 비중심화 변수로 재표현된다.
두 사례 연구는 다음과 같다.
1) Navier‑Stokes 초기 조건 추정: 2D 토러스 도메인에서 비선형 Navier‑Stokes 방정식을 풀어 초기 속도장 v₀ 를 추정한다. 관측은 일정 시간 간격 δ 로 격자점에서 측정된 속도값이며, 관측 잡음 표준편차 τ는 알려졌다. 사전은 µ₀ = N(0, β²A^{‑α}) 로 설정하고, α와 β²를 공동 추정한다. 실험에서는 α를 고정한 경우와 계층적 추정한 경우를 비교했으며, α를 추정하면 사후 평균 오차가 평균 30% 감소하고, 95% 신뢰구간 폭이 40% 축소되는 것을 확인했다. 또한, α 추정이 β²와 관측 잡음 τ에 대한 사후 분포에도 영향을 미쳐 전체 모델 적합도가 향상되었다.
2) 확률적 대류‑확산 방정식 데이터 동화: 선형 SPDE d v = (−μ·∇v + ∇·Σ∇v − ζ v) dt + dε_t 로 정의되며, ε_t는 Whittle‑Matérn 공분산을 갖는 백색 잡음이다. 파라미터 ϕ=(ζ,ρ₁,γ,ψ,μ₁,μ₂,τ) 를 포함하고, 사전 역시 Whittle‑Matérn 형태로 설정한다. 여기서는 α와 β² 외에도 ϕ 전체를 공동 추정한다. 실험 결과, α를 추정함으로써 상태 변수의 예측 오차가 평균 25% 감소하고, 파라미터 ϕ의 사후 분산도 크게 감소한다. 특히, 관측이 희소한 경우에도 α 추정이 모델의 일반화 능력을 크게 향상시켰다.
계산 비용 분석에서는 MwG‑pCN 알고리즘이 상태 변수 샘플링에 dominate 하며, 하이퍼파라미터 샘플링은 전체 실행 시간의 5% 이하에 불과함을 보고한다. 이는 고차원 PDE/ SPDE 역문제에서도 하이퍼파라미터 추정이 실용적임을 의미한다.
결론에서는 (1) 부드러움 파라미터 α를 계층적 베이지안 방식으로 추정함으로써 사후 불확실성 정량화가 크게 개선된다, (2) 제안된 MwG‑pCN 프레임워크가 비선형·선형, 고·저 관측 밀도 모두에서 효율적이며, (3) 기존의 Ensemble Kalman Filter와 같은 빠른 방법은 편향을 내포하지만, 본 방법은 정확한 사후 분포를 제공한다는 점을 강조한다. 향후 연구 방향으로는 비선형 관측 모델, 비가우시안 사전, 그리고 대규모 병렬 구현을 통한 실시간 데이터 동화 적용을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기