마스크‑투‑포인트: 영상 객체 분할 마스크로 비전 파운데이션 모델을 강화한 밀집 포인트 트래킹
초록
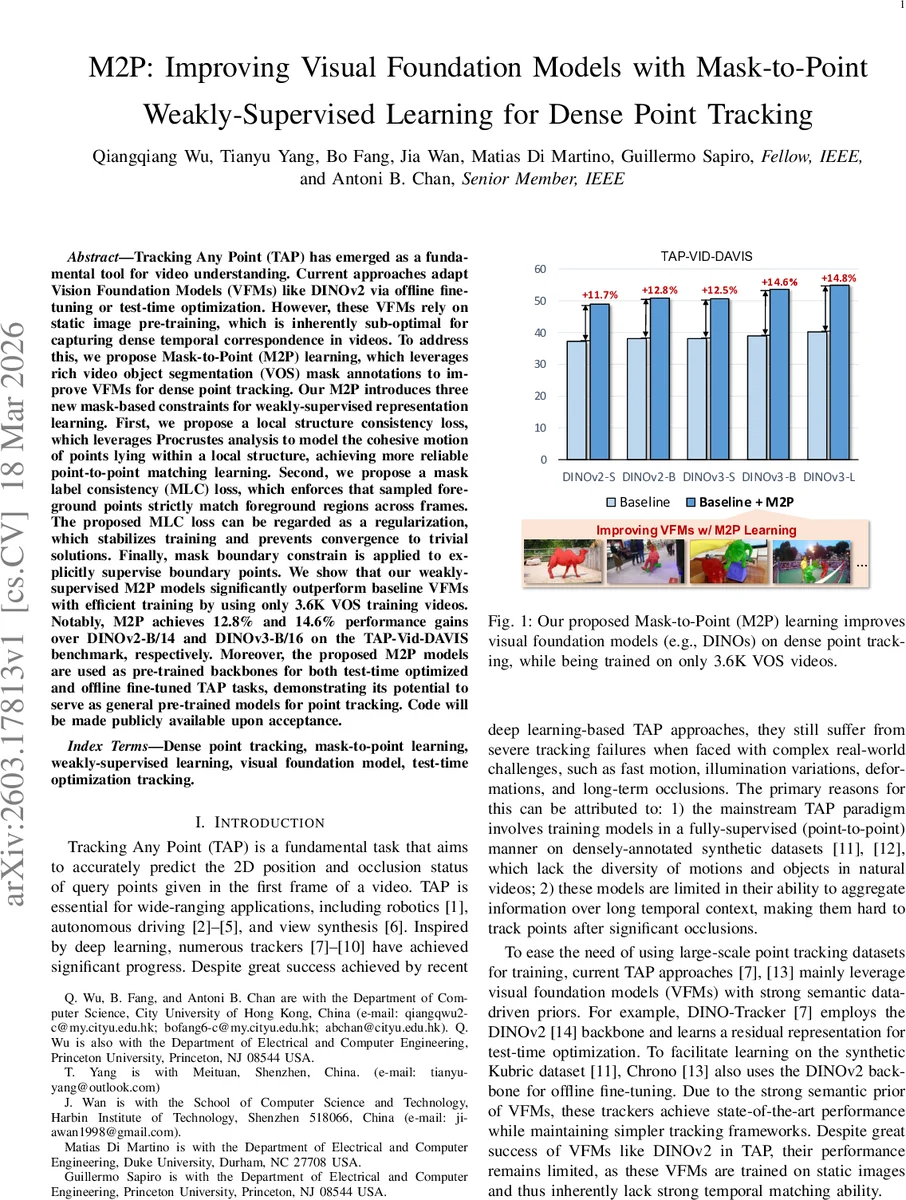
본 논문은 비디오 객체 분할(VOS) 마스크를 활용해 정적 이미지로 사전학습된 비전 파운데이션 모델(VFM)을 약한 지도 학습으로 개선한다. 로컬 구조 일관성 손실(프로크루스 분석 기반), 마스크 레이블 일관성 손실, 마스크 경계 제약을 도입해 3.6K VOS 영상만으로도 DINOv2·DINOv3 대비 TAP‑Vid‑DAVIS 벤치마크에서 각각 12.8%·14.6% 성능 향상을 달성한다. 학습된 M2P 모델은 테스트‑타임 최적화와 오프라인 파인튜닝 모두에 백본으로 사용 가능하다.
상세 분석
M2P는 기존 VFMs가 정적 이미지에만 최적화돼 시간적 일관성을 충분히 학습하지 못한다는 점을 지적한다. 이를 보완하기 위해 저자는 풍부한 마스크 주석을 가진 VOS 데이터셋을 활용한다. 핵심은 세 가지 마스크 기반 제약이다. 첫 번째인 로컬 구조 일관성(LSC) 손실은 동일 그룹에 속한 포인트들이 근접한 공간적 구조를 공유한다는 가정 하에, 그룹 내 상위 Kₑ개의 높은 신뢰도 매칭을 추출하고 프로크루스 분석을 통해 유사 변환(회전·스케일·이동)을 추정한다. 이 변환을 나머지 포인트에 적용해 가짜 라벨을 생성하고, 모델이 예측한 매칭과 비교해 손실을 계산한다. 이렇게 하면 전체 포인트에 대한 직접적인 라벨 없이도 지역적인 움직임 일관성을 학습할 수 있다. 두 번째인 마스크 레이블 일관성(MLC) 손실은 샘플링된 포인트가 전경·배경 레이블을 프레임 간에 유지하도록 강제한다. 이는 트레이닝 중 모델이 전역적인 트리비얼 솔루션(예: 모든 포인트를 같은 위치에 매핑)으로 수렴하는 것을 방지하는 정규화 역할을 한다. 세 번째인 마스크 경계 제약은 경계 근처 포인트에 대해 명시적인 지도 신호를 제공한다. 경계는 물체 변형과 얽힘이 가장 심한 영역이므로, 경계 포인트를 정확히 추적하도록 유도함으로써 전체 트래킹 정확도를 끌어올린다.
데이터 측면에서 저자는 YouTube‑VOS, SA‑V 등 3.6K개의 실제 비디오 마스크를 사용했으며, 이는 기존에 포인트 트래킹을 위해 합성 데이터(Kubric)만을 사용하던 방식과 대비된다. 포인트 샘플링은 마스크 내부를 K‑means 클러스터링해 G개의 그룹으로 나눈 뒤, 각 그룹에서 farthest point sampling을 적용해 K개의 포인트를 골라 다양성과 대표성을 확보한다. 이렇게 얻은 Q = ⋃₍g₌1₎ᴳ Q_g는 LSC 손실 계산에 사용된다.
실험 결과, M2P‑강화된 DINOv2‑B/14와 DINOv3‑B/16은 TAP‑Vid‑DAVIS에서 각각 12.8%와 14.6%의 절대 성능 향상을 보였으며, 이는 동일 데이터셋에서 기존 오프라인 파인튜닝(Chrono) 및 테스트‑타임 최적화(DINO‑Tracker) 방식보다 일관되게 우수했다. 또한, M2P 모델을 백본으로 사용했을 때 두 downstream 방식 모두 추가적인 성능 상승을 기록, M2P가 범용적인 사전학습 모델로 활용 가능함을 입증한다.
한계점으로는 현재 마스크 기반 제약이 전경·배경 구분이 명확한 경우에 최적이며, 복잡한 다중 객체·다중 레이어 상황에서는 그룹화 전략과 경계 제약이 추가적인 설계가 필요할 수 있다. 또한, 프로크루스 기반 변환 추정은 2D 유사 변환에 국한되므로 비선형 변형(예: 비강체 변형)에는 충분히 대응하지 못한다는 점도 언급된다. 향후 연구에서는 3D 변형 모델링, 다중 객체 동시 학습, 그리고 마스크 품질이 낮은 경우를 위한 강인한 샘플링 기법을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기