데이터 없이 층별 혼합 정밀도 양자화를 위한 수치·구조 이중 민감도 프레임워크
초록
본 논문은 LLM의 사후 양자화에서 층별 혼합 정밀도를 결정하기 위해, 각 층을 “Detector”(패턴 탐지)와 “Writer”(정보 기록) 역할로 mechanistic하게 분해하고, 두 가지 관점인 수치적 취약성(NV)과 구조적 표현력(SE)을 정량화한다. NV는 가중치 분포의 초과 첨도(kurtosis)로, SE는 특이값 분해를 통한 스펙트럼 크기와 엔트로피, 그리고 역할별 가중치(Detection Specificity, Writing Density)로 측정한다. 정규화는 MAD‑Sigmoid, 통합은 Soft‑OR을 사용해 최종 민감도 점수(NSDS)를 얻고, 목표 비트 예산에 맞춰 가장 민감한 층에 4‑bit, 나머지에 2‑bit을 할당한다. 실험 결과, 별도의 캘리브레이션 데이터 없이도 다양한 LLM과 다운스트림 태스크에서 기존 방법들을 일관되게 능가한다.
상세 분석
NSDS 프레임워크는 기존 LMPQ 연구가 가지고 있던 두 가지 근본적인 한계를 동시에 해결한다. 첫 번째는 “층 내부 가중치 모듈을 동일하게 취급한다”는 가정이다. 저자는 Transformer 층을 Multi‑Head Attention과 Feed‑Forward Network로 나눈 뒤, 각 연산을 다시 두 개의 기능적 역할인 Detector와 Writer로 세분화한다. 예를 들어, QK 행렬과 FFN의 입력 행렬은 입력 토큰이나 뉴런 특징을 탐지하는 Detector 역할을, OV 행렬과 FFN의 출력 행렬은 탐지된 정보를 잔차 스트림에 기록하는 Writer 역할을 수행한다. 이러한 mechanistic decomposition은 각 모듈이 모델 전체 출력에 미치는 영향을 역할 기반으로 명확히 구분함으로써, 양자화 민감도 추정에 필요한 정보를 보다 정밀하게 제공한다.
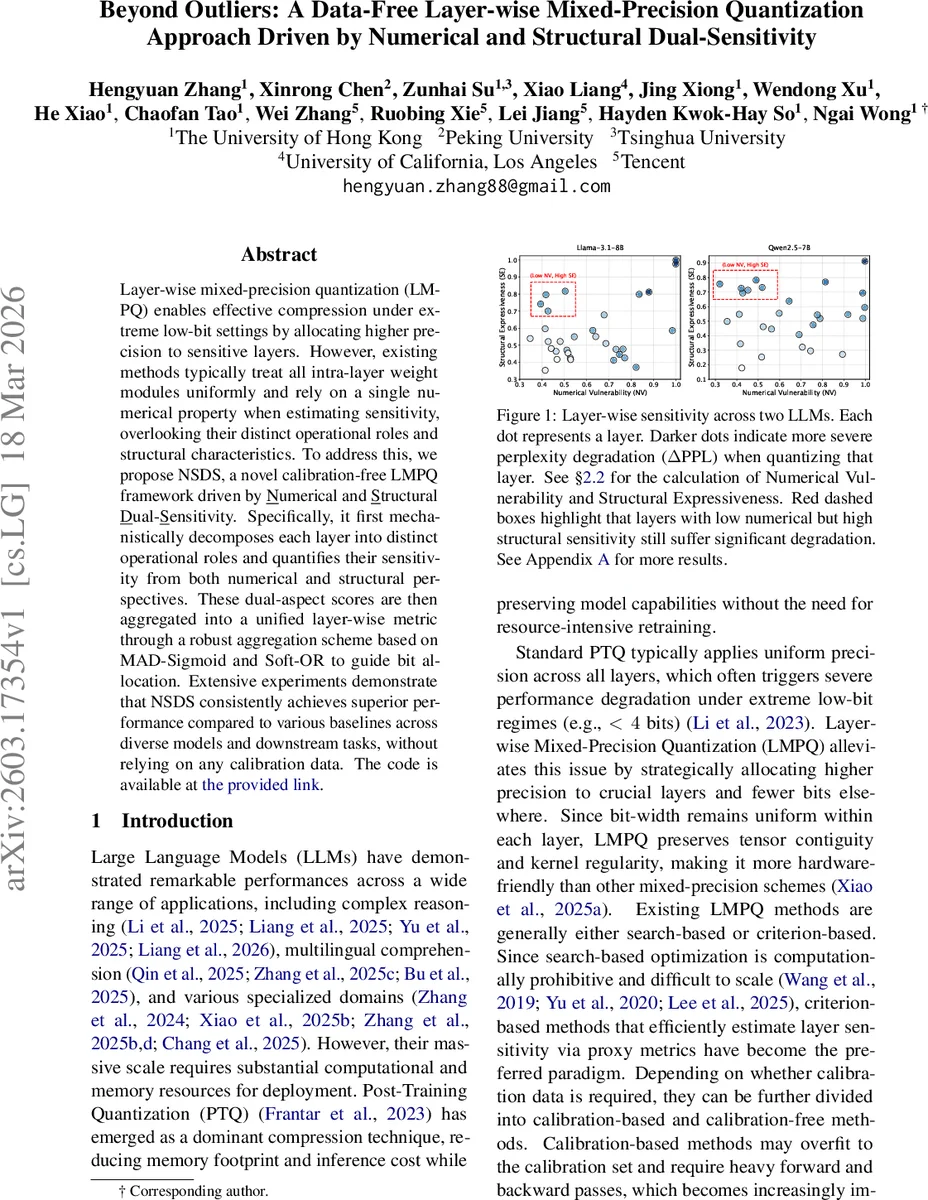
두 번째 한계는 “단일 수치적 지표에 의존한다”는 점이다. NSDS는 수치적 취약성(NV)과 구조적 표현력(SE)이라는 두 축을 도입한다. NV는 가중치 텐서의 초과 첨도(κ)를 이용해 극단값(outlier)의 밀도를 측정한다. 첨도가 높을수록 양자화 구간이 넓어져 정밀도 손실이 커지므로, NV가 큰 모듈은 낮은 비트폭에 더 취약하다고 판단한다. SE는 특이값 분해(SVD)를 통해 얻은 특이값 σ의 합(스펙트럼 크기)과 정규화된 엔트로피(H)를 결합해 정의한다. 여기서 단순히 σ만을 사용하면 역할에 따른 중요도를 반영하지 못하므로, Detector와 Writer 각각에 맞는 재가중치 팩터를 도입한다. Detector는 입력 특이벡터(V)의 첨도로 Detection Specificity(β_DS)를 계산하고, Writer는 출력 특이벡터(U)를 어휘 임베딩 행렬(W_U)에 투사한 L1 노름을 Writing Density(β_WD)로 정의한다. 이렇게 재가중된 σ_i에 대해 Σ_i σ_i·β_i를 사용해 역할‑특화 구조적 표현력(E_role)을 얻는다.
다음 단계에서는 NV와 SE 점수의 스케일 차이를 보정하기 위해 Median Absolute Deviation(MAD) 기반 Z‑score를 계산하고, Sigmoid 함수를 적용해 0~1 구간으로 정규화한다(MAD‑Sigmoid). 정규화된 확률값들을 Soft‑OR 연산으로 결합한다. Soft‑OR은 “하나라도 크게 나오면 전체가 크게” 만드는 논리 연산으로, 민감도가 높은 모듈이 전체 층 점수에 지배적인 영향을 미치게 한다. 층별 NV와 SE를 각각 Soft‑OR로 합친 뒤, 다시 Soft‑OR를 적용해 최종 NSDS 점수(S_NSDS) 를 산출한다.
비트 할당은 목표 평균 비트(예: 2.5~3.5)와 전체 층 수 L을 이용해 4‑bit을 할당할 층 수 L_4 = round(ρ·L) (ρ = (b̄−2)/(4−2)) 를 계산하고, NSDS 점수가 높은 L_4개의 층에 4‑bit, 나머지에 2‑bit을 부여한다. 이 방식은 복잡한 검색 기반 최적화 없이도 간단한 정렬과 임계값 설정만으로 효율적인 혼합 정밀도 배정을 가능하게 한다.
실험에서는 Llama‑3.1‑8B, Qwen2.5‑7B 등 다양한 LLM을 대상으로 WikiText‑2, C4 등 언어 모델링 베이스라인과 ARC‑Challenge, HellaSwag 같은 추론 베이스라인을 평가했다. 캘리브레이션 데이터를 전혀 사용하지 않았음에도 불구하고, 기존의 outlier‑기반, Hessian‑기반, 혹은 레이어‑별 스케일링 기반 방법들을 전반적으로 앞섰다. 특히, 수치적 취약성은 낮지만 구조적 표현력이 높은 층(예: 특정 attention head)의 경우, 기존 방법이 과소평가하는 반면 NSDS는 Writer 역할의 β_WD를 통해 정확히 감지해 높은 비트를 할당함으로써 성능 저하를 방지한다.
요약하면, NSDS는 (1) 층 내부 모듈을 역할 기반으로 세분화, (2) 수치와 구조 두 관점을 동시에 정량화, (3) 역할‑특화 재가중치와 강건한 정규화·통합 기법을 도입해 캘리브레이션‑프리 LMPQ를 구현한다. 이론적 근거와 실험적 검증이 충분히 제시되어, 향후 대규모 모델의 효율적 배포에 실용적인 솔루션으로 활용될 가능성이 높다.
댓글 및 학술 토론
Loading comments...
의견 남기기