정렬이 언어 모델을 서술적이 아닌 규범적으로 만든다
본 논문은 사전 학습된 언어 모델에 사후 정렬(RLHF·DPO 등)을 적용했을 때, 인간 행동을 서술적으로 예측하는 능력은 크게 감소하고, 대신 규범적(게임 이론적) 행동을 예측하는 데는 오히려 향상된다는 사실을 120개의 모델 쌍과 10,000여 개의 실제 인간 선택 데이터를 통해 입증한다.
저자: Eilam Shapira, Moshe Tennenholtz, Roi Reichart
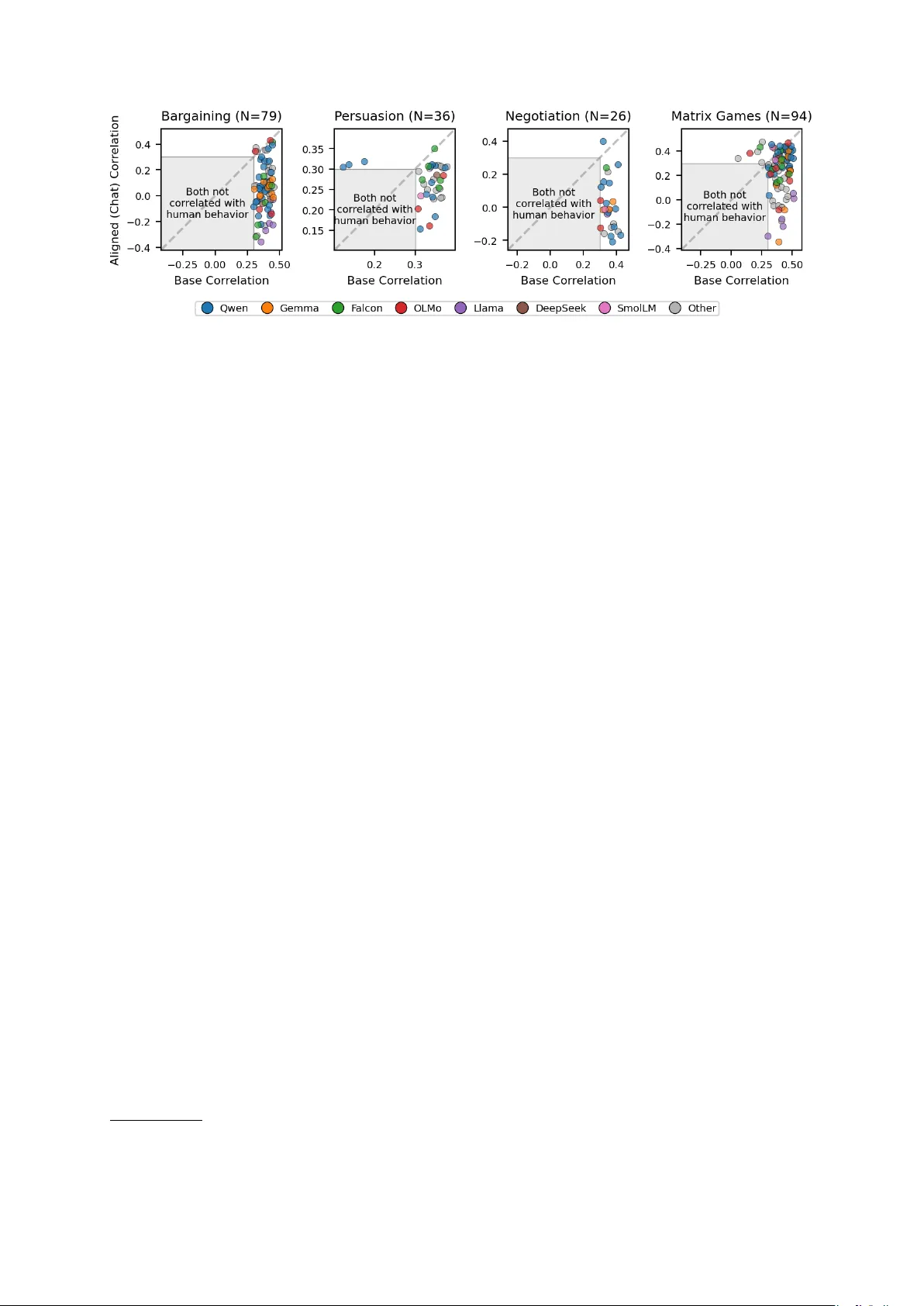
본 논문은 사후 정렬(post‑training alignment)이 대형 언어 모델(LLM)의 행동 예측 특성을 어떻게 변화시키는지를 실증적으로 조사한다. 정렬은 일반적으로 인간 선호(협력, 공정성, 사회적 적합성 등)를 반영하도록 모델을 미세조정하는 과정이며, RLHF(Reinforcement Learning from Human Feedback)와 DPO(Direct Preference Optimization) 등이 대표적인 방법이다. 저자들은 정렬이 “규범적” 행동을 강화하고, 실제 인간이 보이는 “서술적” 행동을 왜곡할 가능성을 제기한다.
이를 검증하기 위해 23개의 모델 패밀리(예: GPT‑3.5, Llama, Falcon 등)에서 각각 베이스와 정렬 버전을 선택해 120개의 모델 쌍을 구성하였다. 각 쌍은 동일한 프롬프트와 입력 형식(베이스는 텍스트 완성, 정렬은 챗 템플릿)으로 평가되었다. 실험 데이터는 네 가지 멀티라운드 전략 게임—협상(bargaining), 설득(persuasion), 교섭(negotiation), 반복 매트릭스 게임(Prisoner’s Dilemma, Battle of the Sexes)—에서 10,050건의 인간 선택을 포함한다. 각 게임은 인간이 LLM과 대화형으로 상호작용하도록 설계되었으며, 인간은 자신의 역할(예: 제안 수용/거부, 구매 여부 등)만을 수행했다.
예측 방법은 각 의사결정 시점에 해당하는 프롬프트를 모델에 입력하고, 다음 토큰 확률을 추출해 “accept/yes” 등 결정 토큰에 대한 확률을 정규화하는 방식이다. 이 확률을 인간 선택의 실제 비율과 Pearson 상관관계로 비교한다. 또한, 모델이 결정 토큰에 충분히 확률을 할당하지 않는 경우(80% 미만)와 인간과의 상관이 0.3 이하인 경우를 필터링해 신뢰성을 확보하였다.
멀티라운드 게임 결과는 일관되게 베이스 모델이 정렬 모델을 압도했다. 구체적으로, 베이스 모델은 협상에서 75:4, 설득에서 32:4, 교섭에서 25:1, 매트릭스 게임에서 81:13의 승률을 기록했으며, 전체 승률 비율은 약 9.7:1(p < 10⁻⁴⁰)이다. 이 우위는 모델 규모가 클수록, 프롬프트 변형이 다양할수록, 그리고 게임 파라미터가 바뀔수록 유지되었다. 라운드가 진행될수록 인간 행동은 과거 상호작용에 기반한 보복·보복·평판 메커니즘을 보이며, 정렬 모델은 이러한 동적 패턴을 포착하지 못하고 규범적(예: 협력적) 선택에만 편향된 것으로 보인다.
반면, 경계조건 실험에서는 정렬 모델이 우위를 보였다. 단일 라운드 2×2 매트릭스 게임(12가지 게임 유형, 93,000명 인간 선택)에서는 정렬 모델이 4.1:1의 승률을 기록했고, 인간 행동과의 상관은 Nash 균형과 높은 일치(r = 0.62)를 보였다. 비전략적 복권 선택(1,001문제, 28–31명 참가)에서도 정렬 모델이 2.2:1로 베이스 모델을 앞섰다. 이러한 결과는 정렬이 모델을 “규범적” 예측(게임 이론적 최적해)으로 끌어올리지만, 복잡한 상호작용이 포함된 상황에서는 인간의 실제 행동을 왜곡한다는 것을 시사한다.
추가 실험으로 프롬프트 형식을 교차 적용했을 때, 베이스 모델에 챗 템플릿을 사용하거나 정렬 모델에 일반 텍스트 형식을 사용해도 성능 차이는 크게 변하지 않았다. 이는 정렬 자체가 출력 분포를 좁히고 다양성을 감소시키는 “정렬 세금” 현상을 확인시켜준다.
결론적으로, 정렬은 LLM을 인간 친화적이고 사회적으로 바람직한 응답을 생성하도록 만드는 데는 효과적이지만, 인간 행동을 서술적으로 모델링하려는 연구·시뮬레이션 목적에는 부정적 영향을 미친다. 저자들은 모델 선택 시 목적에 따라 정렬 여부를 신중히 판단해야 하며, 특히 전략적 상호작용을 연구하고자 할 때는 베이스 모델을 활용하거나 정렬 과정에서 서술적 다양성을 보존하는 방법을 모색해야 한다고 제언한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기