OPERA 온라인 데이터 프루닝으로 효율적인 검색 모델 적응
OPERA는 도메인 특화 파인튜닝 시 학습 쌍의 품질이 고르게 기여하지 않는다는 점을 활용해, 정적 프루닝(SP)과 동적 프루닝(DP) 두 가지 전략을 제안한다. SP는 고유사도 쿼리‑문서 쌍만 남겨 NDCG를 향상시키지만 조회 다양성이 감소해 Recall이 떨어지는 품질‑커버리지 트레이드오프를 보인다. 이를 해결하기 위해 DP는 학습 진행에 따라 쿼리와 문서 수준에서 샘플링 확률을 동적으로 조정해 고품질 예시는 더 자주, 저품질 예시는 감소된…
저자: Haoyang Fang, Shuai Zhang, Yifei Ma
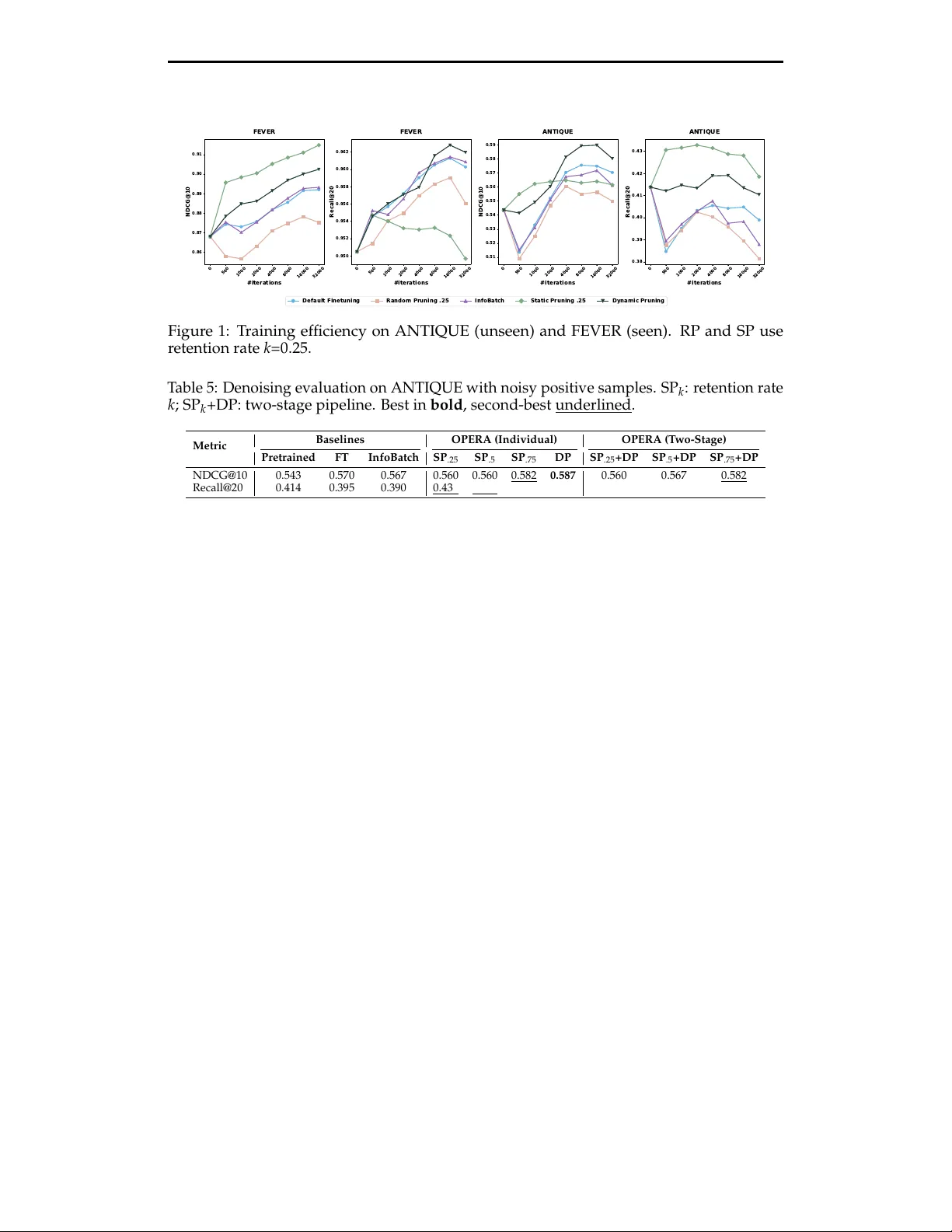
본 논문은 밀집 검색(dense retriever) 모델의 도메인 특화 파인튜닝 과정에서 학습 데이터의 이질성이 성능에 미치는 영향을 체계적으로 조사하고, 이를 활용한 두 가지 프루닝 전략을 제안한다. 먼저, 기존 파인튜닝(FT) 방식은 쿼리를 균등하게 샘플링하고, 각 쿼리마다 하나의 긍정 문서와 하드 네거티브 문서를 선택해 대조 학습을 수행한다. 이때 모든 쿼리‑문서 쌍을 동일하게 취급하지만, 실제로는 일부 쌍이 모델 업데이트에 더 큰 기여를 한다는 점을 저자는 지적한다.
**정적 프루닝(Static Pruning, SP)**
- 사전 학습된 모델을 이용해 모든 쿼리‑문서 쌍의 코사인 유사도를 계산한다.
- 상위 k% (데이터 유지 비율)만을 남기고 나머지는 완전히 배제한다.
- 이 과정은 샘플링 확률을 크게 바꾸어, 고유사도 쌍에 집중하게 만든다.
- 실험 결과, SP는 NDCG@10에서 일관된 향상을 보였으며, 특히 NFCorpus, TriviaQA, FEVER와 같은 데이터셋에서 최고 점수를 기록했다.
- 그러나 쿼리 다양성이 감소해 Recall@20이 악화되는 “품질‑커버리지 트레이드오프”가 발생한다. 이는 일부 쿼리가 긍정 문서가 적어 프루닝 과정에서 완전히 사라지기 때문이다.
**동적 프루닝(Dynamic Pruning, DP)**
- SP의 한계를 보완하기 위해 두 단계(쿼리, 문서)에서 샘플링 확률을 시간에 따라 조정한다.
- 쿼리 수준: 고품질 쿼리를 우선 선택하되, 일정 비율의 저품질 쿼리를 무작위로 섞어 전체 쿼리 공간을 유지한다.
- 문서 수준: 품질 점수에 따라 가중치를 부여하고, 모든 문서가 최소 확률로 선택되도록 소프트 프루닝을 적용한다.
- 샘플링 강도 α(쿼리)와 β(문서)는 코사인 스케줄링을 사용해 초기에는 완화되고, 학습이 진행될수록 점점 강화된다.
- 업데이트 간격 Iu를 도입해 품질 점수 재계산을 일정 주기로만 수행, 추가 연산 비용을 4.5%→1.64%로 감소시켰다.
**이론적 분석**
- Lemma와 Theorem을 통해, 긍정 라벨 중 실제 정답 비율 γ가 전체 정답 비율(m⁺/m)보다 클 경우, 프루닝된 샘플링이 기대 코사인 유사도를 증가시킨다.
- 정적 프루닝은 잡음 샘플을 완전히 배제하므로 γ가 충분히 높을 때 최적이다.
- 동적 프루닝은 γ가 낮아도 β와 ρ(품질 샘플 비율)를 점진적으로 높여 잡음 영향을 완화함으로써 장기적으로 SP를 능가한다.
**실험**
- 8개 데이터셋(영양, 의료, 금융, 비사실 QA, 사실 QA, 사실 검증)과 2가지 모델(BGE-large, Qwen3‑Embedding)에서 평가.
- SP는 데이터 75%를 제거하면서도 NDCG@10을 평균 0.5% 상승시켰다.
- DP는 NDCG@10을 평균 1.9%·Recall@20을 0.7% 향상시키고, 전체 평균 순위 1.38을 기록했다.
- 특히 DP는 학습 시간도 50% 이하로 단축, 동일 성능에 더 빠르게 수렴했다.
- 업데이트 간격 Iu를 늘려도 성능 저하가 거의 없으며, InfoBatch과 비교해 더 높은 NDCG와 Recall을 달성했다.
**결론 및 의의**
OPERA는 검색 파인튜닝에 특화된 데이터 프루닝 프레임워크로, 품질‑커버리지 트레이드오프를 정량화하고 동적 샘플링을 통해 두 지표를 동시에 최적화한다. 정적 프루닝은 빠른 성능 향상과 데이터 효율성을 제공하지만 커버리지가 감소하고, 동적 프루닝은 이를 보완해 전반적인 성능과 효율성을 모두 달성한다. 또한, LLM 기반 임베딩 모델(Qwen3‑Embedding)에도 적용 가능함을 실험적으로 입증했다. 향후 연구에서는 프루닝 기준을 다중 모달 데이터에 확장하거나, 프루닝과 모델 구조 설계의 공동 최적화를 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기