문맥 기반 선호 분포 학습으로 위험 회피 의사결정 최적화
본 논문은 인간 선택을 정수선형계획(ILP) 형태로 모델링하고, 컨텍스트 특징에 따라 선호 비용의 확률분포를 학습한다. 점수 함수 기반의 제한된 분산 그라디언트 추정기를 이용해 파라미터화된 분포 qθ(c|X)를 최대우도(MLE)로 학습하고, 학습된 분포로부터 시나리오를 생성해 위험 회피형 최적화(예: CVaR) 단계에 적용한다. 합성 라이드셰어링 실험에서 기존 방법 대비 사후 결정 놀라움을 최대 114배, 위험 회피 기준에서는 25배까지 감소시…
저자: Benjamin Hudson, Laurent Charlin, Emma Frejinger
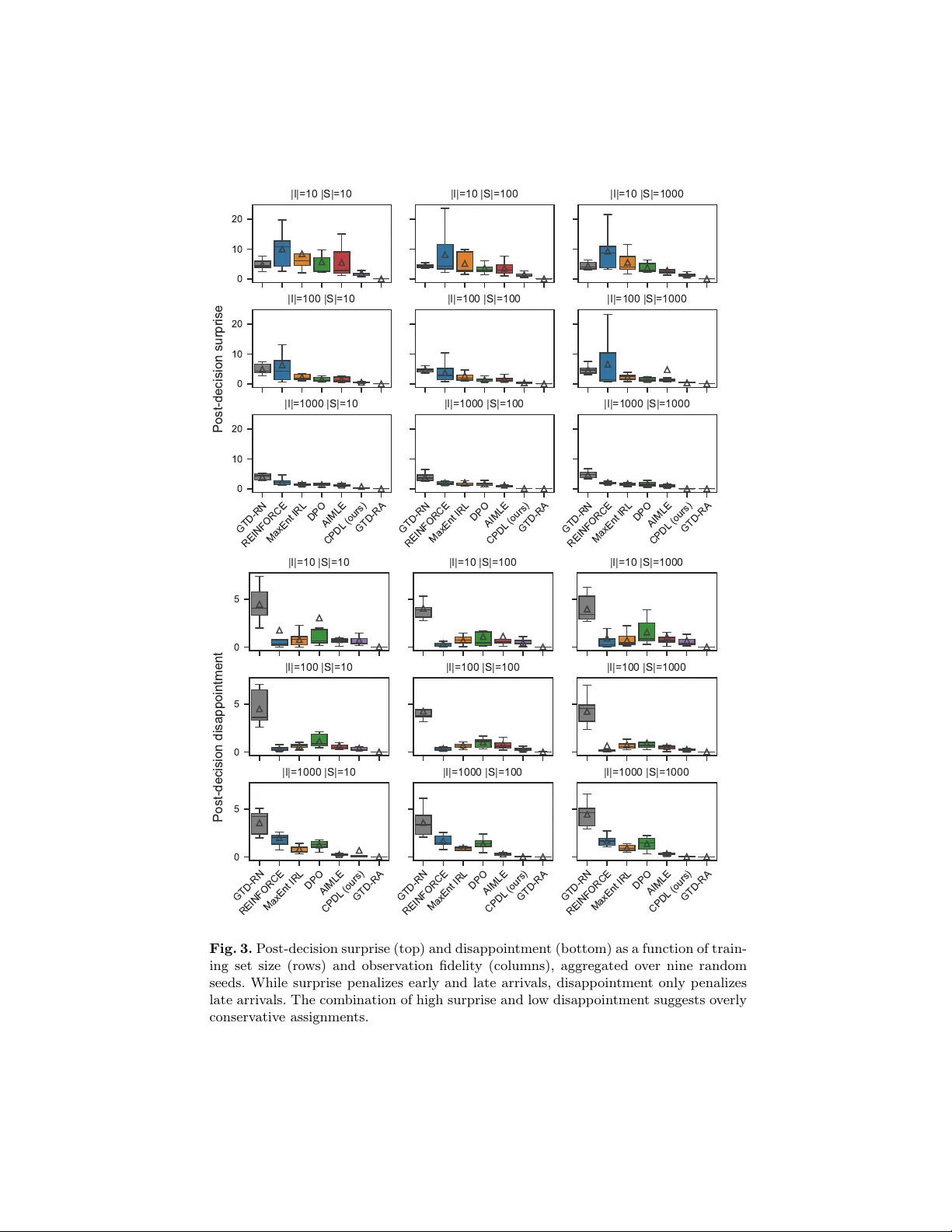
본 논문은 인간의 선택 행동이 상황에 따라 크게 달라지는 문제를 다루며, 특히 이러한 선택이 정수선형계획(ILP) 형태로 표현될 수 있는 경우에 초점을 맞춘다. 기존의 역최적화(Inverse Optimization)와 선택 모델링 기법은 관측된 선택을 통해 비용 파라미터를 점 추정하거나, 컨텍스트에 따른 변화를 충분히 반영하지 못한다는 한계가 있다. 이러한 한계는 위험 회피형 의사결정에서 필수적인 확률분포 정보를 제공하지 못해, 실제 시스템에서 사후 결정 놀라움(post‑decision surprise)을 크게 만든다.
저자들은 이를 해결하기 위해 “Contextual Preference Distribution Learning”(CPDL)이라는 두 단계 학습‑최적화 파이프라인을 제안한다. 첫 번째 단계인 학습 단계에서는 컨텍스트 행렬 X (각 선택 항목에 대한 특성 벡터)와 관측된 선택 통계 \(\bar\phi\) (예: 선택된 경로의 평균 선택 확률)를 입력으로, 비용 벡터 c 의 조건부 확률분포 \(q_\theta(c|X)\) 를 파라미터화된 형태(예: 정규화 흐름, 가우시안 믹스처 등)로 학습한다. 이때 선택 문제는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기