예측형 계획으로 멀티모달 AI 에이전트의 장기 행동을 강화한다
TraceR1은 두 단계 강화학습 프레임워크를 통해 멀티모달 에이전트가 단기 궤적을 예측하고, 실행 피드백으로 미세조정함으로써 장기 목표를 고려한 계획 안정성과 실행 견고성을 크게 향상시킨다.
저자: Yongyuan Liang, Shijie Zhou, Yu Gu
본 논문은 멀티모달 AI 에이전트가 복잡한 GUI와 도구 사용 환경에서 장기적인 목표를 달성하기 위해 필요한 “예측형 계획(anticipatory planning)”을 구현하는 새로운 프레임워크 TraceR1을 제안한다. 기존 연구들은 주로 모델‑프리 강화학습을 통해 개별 스텝의 보상을 최적화하거나, 모델‑베이스 방식으로 세계 모델을 구축해 미래를 시뮬레이션하는 접근을 사용했다. 그러나 시각‑언어 기반 인터페이스는 고차원 이미지와 동적 상태 변화를 포함해 세계 모델 구축이 어렵고, 보상 설계 역시 다양한 작업에 일반화하기 힘들다. 이러한 한계를 극복하고자 저자들은 두 단계 강화학습 구조를 설계했다.
1. **Stage 1 – Anticipatory Trajectory Optimization**
- 입력: 사용자 명령(u), 현재 스크린샷(s_t), K‑step 이력(압축된 요약 ϕ(s_i)).
- 출력: 미래 T‑step 길이의 행동·지시 시퀀스 ˆτ = {(ˆa_t, ˆg_t)…}.
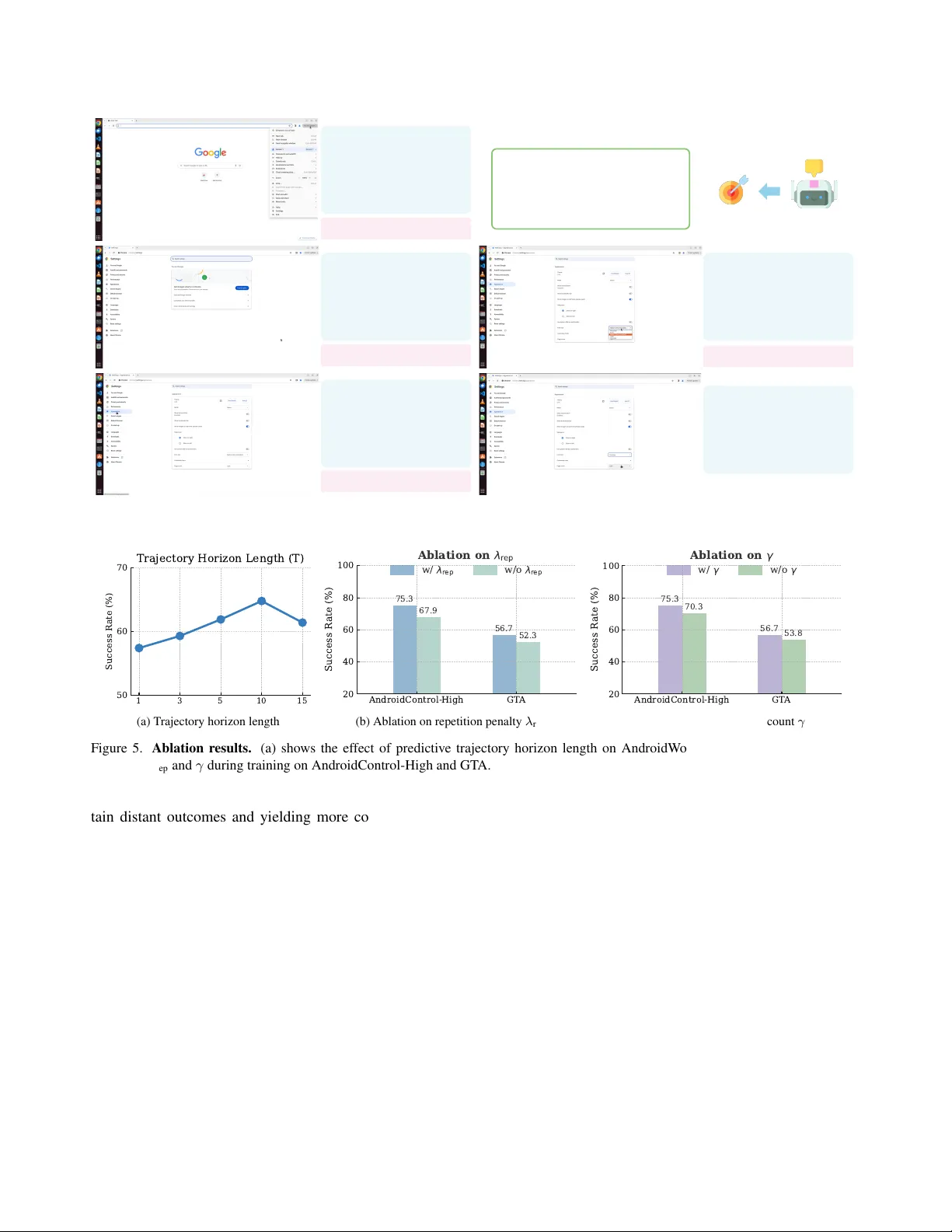
- 보상: 정답 궤적과의 정렬도(sim)와 반복 행동 억제(rep)를 결합한 단계‑별 보상 r_t = λ_align·sim(ˆa_t, a*_t) − λ_rep·rep(ˆa_{1:t}). 전체 궤적 보상은 γ 할인율을 적용한 합계 R(ˆτ,τ*) = ∑γ^{t‑1} r_t.
- 최적화: 그룹‑상대 정책 최적화(GRPO)를 사용해 정책 π_θ를 업데이트, 이는 전체 궤적 수준에서의 상대적 이득을 활용한다.
2. **Stage 2 – Grounded Reinforcement Fine‑tuning**
- 첫 단계에서 학습된 정책을 그대로 사용하되, 예측된 첫 행동만을 실제 툴 에이전트(예: GUI 클릭, API 호출)에게 전달한다.
- 툴 에이전트의 실행 결과를 정답과 비교해 스텝‑레벨 보상 r_Gt를 산출한다. GUI 작업에서는 좌표 매칭, 툴 호출 작업에서는 정답 매칭을 사용한다.
- 동일한 GRPO 업데이트 규칙을 적용해 정책을 미세조정함으로써, 실행 가능성 및 정확성을 강화한다.
**학습 파이프라인**은 대규모 멀티모달 궤적 데이터셋을 활용한다. Stage 1에서는 전체 궤적을 사용해 예측만 수행하고, 실제 실행은 하지 않는다. Stage 2에서는 동일한 데이터셋을 사용하지만, 첫 행동만 실행해 피드백을 얻는다. 이렇게 함으로써 오프라인 데이터만으로도 두 단계 학습이 가능하다.
**추론 과정**은 “계획‑실행‑재계획” 루프이다. 현재 관찰을 입력받아 다중 스텝 궤적을 예측하고, 첫 스텝만 실행한다. 실행 후 새로운 관찰을 받아 다시 궤적을 예측한다. 이 반복은 장기 목표를 지속적으로 재평가하고, 환경 변화에 즉각 대응하도록 만든다.
**실험**에서는 7개의 벤치마크(온라인·오프라인 GUI, 멀티모달 툴 사용)에서 기존 최첨단 모델과 비교했다. 주요 결과는 다음과 같다.
- OSWorld‑Verified, Android‑World 등 장기 GUI 작업에서 계획 붕괴 비율이 크게 감소하고, 성공률이 10‑15%p 상승.
- GAIA·GTA와 같은 툴 사용 벤치마크에서 정답 일치율이 8‑12%p 향상.
- 동일한 모델(Qwen3‑VL‑8B) 기반이지만, TraceR1을 적용한 경우 프로프라이어터리 모델(o3, Claude 4)과 근접한 성능을 보이며, 오픈소스 베이스라인 대비 20‑30%p 우수.
**기여**는 네 가지로 요약된다. (1) 예측형 궤적을 학습하도록 설계된 두 단계 RL 프레임워크 제시, (2) 궤적‑레벨 정렬 보상과 스텝‑레벨 실행 보상을 결합한 새로운 학습 목표, (3) 다양한 GUI·툴 환경에 적용 가능한 통합 파이프라인 구현, (4) 광범위한 벤치마크에서 기존 방법을 크게 앞선 실증적 증거 제공.
결론적으로, TraceR1은 멀티모달 에이전트가 “몇 단계 앞을 내다보는” 능력을 학습하게 함으로써, 복합 인터페이스와 도구 사용 시 발생하는 장기 의존성을 효과적으로 해결한다. 이는 향후 인간‑컴퓨터 협업, 자동화된 업무 수행, 그리고 일반 인공지능 시스템에서 계획·실행·재계획의 순환 구조를 구현하는 핵심 원칙이 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기