코드 흐름을 학습한 차세대 코드 LLM IQuest‑Coder‑V1
IQuest‑Coder‑V1 시리즈는 7B‑40B 규모의 코드 전용 대형 언어 모델로, 정적 코드 학습을 넘어 코드 흐름(코드‑플로우) 다단계 훈련 파이프라인을 도입한다. 사전 학습 → 32k·128k 초장문 중간 학습 → 사고(Thinking)와 지시(Instruct) 두 경로의 후학습으로 구성되며, Loop‑Coder 구조를 통해 반복적 컨텍스트 처리를 가능하게 한다. 벤치마크(SWE‑Bench, LiveCodeBench 등)에서 최신 상용…
저자: Jian Yang, Wei Zhang, Shawn Guo
IQuest‑Coder‑V1 기술 보고서는 코드 전용 대형 언어 모델 시리즈(7B, 14B, 40B)와 이를 경량화한 Loop‑Coder 변형을 소개한다. 핵심 아이디어는 “코드‑플로우(Code‑Flow)”라는 다단계 학습 파이프라인으로, 정적 파일 수준을 넘어 코드 저장소의 시간적 변천과 커밋 흐름을 학습 데이터에 포함시켜 모델이 소프트웨어 개발 과정 전체를 이해하도록 만든다.
**1. 학습 파이프라인**
- **Pre‑training & Annealing**: 일반 텍스트와 코드 데이터를 혼합해 기본 언어·코드 능력을 구축하고, 고품질 코드 코퍼스로 annealing해 노이즈를 최소화한다.
- **Mid‑training**: 두 단계(32k, 128k) 초장문 컨텍스트에서 reasoning, agentic, code 데이터를 동시에 학습한다. 32k 단계에서는 장기 추론과 에이전트 행동을 초기화하고, 128k 단계에서는 실제 대규모 저장소와 멀티‑파일 상황을 시뮬레이션한다.
- **Post‑training**: 두 갈래 경로로 분기한다.
- **Thinking Path**: 사고(trace) 데이터를 포함한 SFT 후, 추론 중심 RL을 적용해 자율 오류 복구·장기 계획 능력을 강화한다.
- **Instruct Path**: 일반적인 명령 수행과 코드 설명에 초점을 맞춘 SFT·RL로, 사용자 친화적인 어시스턴트 역할을 최적화한다.
**2. Loop‑Coder 구조**
Loop‑Coder는 동일 파라미터를 두 번 순환 적용하는 “루프 트랜스포머” 설계다. 첫 번째 순환은 일반적인 인코딩을 수행하고, 두 번째 순환에서는 (a) 전역 어텐션을 통해 첫 번째 순환의 전체 KV를 참조하고, (b) 로컬 어텐션을 통해 현재 토큰의 인과 관계를 유지한다. 두 어텐션 결과는 쿼리 기반 게이트로 가중합돼, 긴 코드 블록을 단계별로 정제하면서 메모리 사용을 최소화한다. 기존 Parallel Loop Transformer와 달리 토큰‑시프트 메커니즘을 제거해 구현 복잡성을 낮추고, 추론 시에도 두 번의 순환만으로 충분히 높은 성능을 얻는다.
**3. 데이터 구축**
- **일반 텍스트**: Common Crawl 기반 대규모 일반 텍스트를 정규식·중복 제거·AST 검증을 거쳐 정제.
- **코드**: AST 기반 구문 검증, 파일·레포 수준 FIM(Fill‑In‑the‑Middle) 데이터, 저장소 트리플렛(Old‑Patch‑New) 형태의 진화 데이터 등을 포함.
- **고품질 QA**: CodeSimpleQA‑Instruct를 활용해 66M 객관식 QA를 생성, 모델이 사실 기반 질문에 정확히 답하도록 유도.
- **다중 언어(PL) 혼합**: 다양한 프로그래밍 언어를 균형 있게 배분해 언어 다양성을 데이터 증강 효과로 활용한다.
**4. 인프라 및 효율성**
수백만 GPU‑hour 규모의 학습을 지원하기 위해 fused gated attention 커널, KV shard 전송, deterministic 재계산·텐서 지문 검증 등을 도입했다. 이는 초장문(128k) 학습 시 메모리 대역폭을 크게 절감하고, 하드웨어 오류를 조기에 탐지한다.
**5. 실험 및 결과**
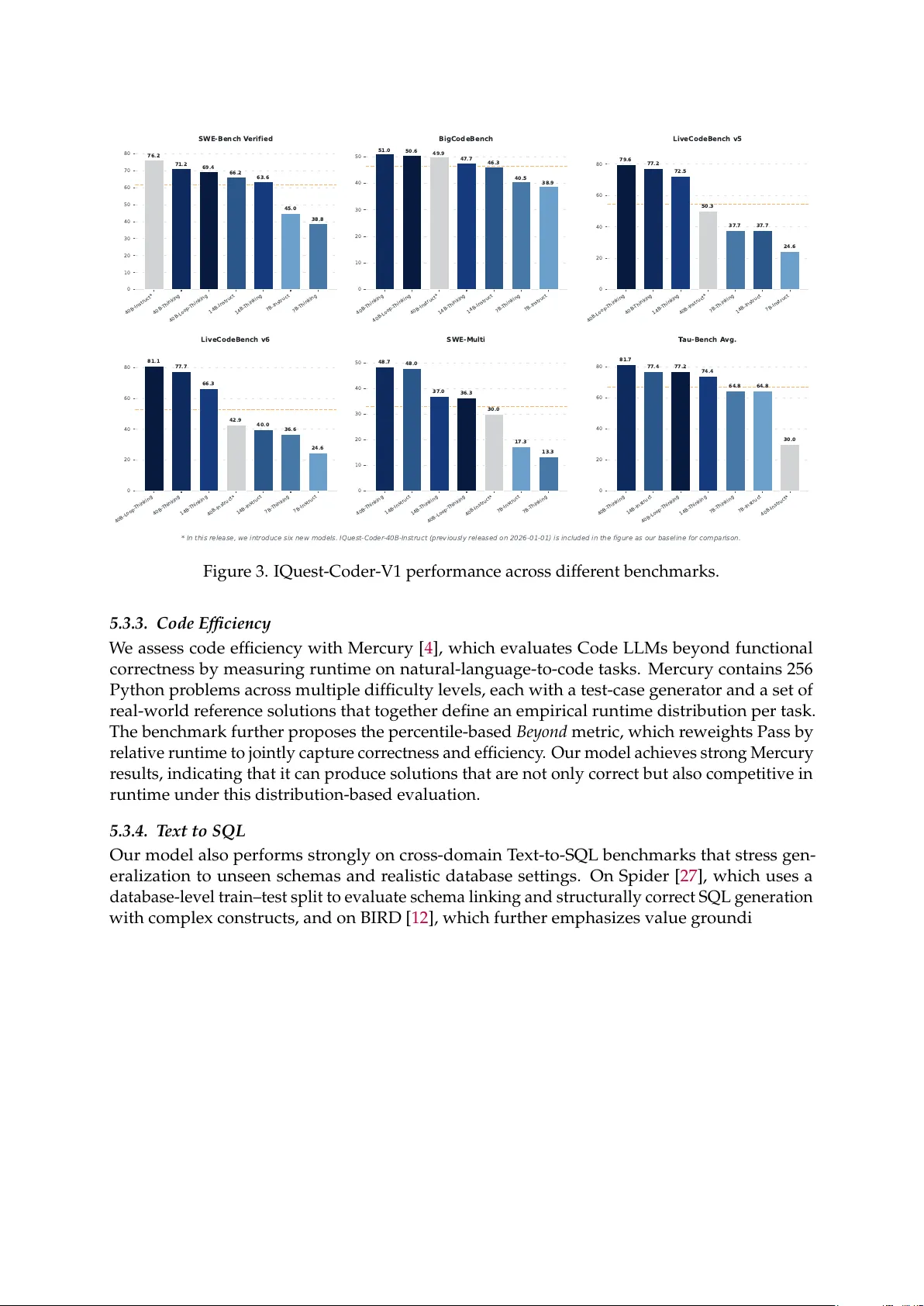
주요 벤치마크(SWE‑Bench, LiveCodeBench v6, BigCodeBench, Bird‑SQL, BFCL, Terminal‑Bench 등)에서 IQuest‑Coder‑V1‑40B‑Loop‑Thinking 모델은 77.2점(SWE‑Bench) 등 최고 성능을 기록했고, Instruct 모델도 73.8점(BFCL) 등 경쟁 모델을 앞섰다. 특히 LiveCodeBench v6에서 87.0점을 획득해 복잡한 멀티‑파일 코드 생성·디버깅 능력이 크게 향상됐음을 보여준다.
**6. 주요 발견**
- **Finding 1**: 저장소 전이 데이터(커밋 흐름)는 정적 파일만 사용할 때보다 작업 계획 수립에 더 강력한 신호를 제공한다.
- **Finding 2**: 고품질 코드 annealing 이후 32k reasoning 데이터를 삽입하면, 모델이 분포 이동(예: 새로운 도메인)에도 안정적인 성능을 유지한다.
- **Finding 3**: 사고 경로 RL은 장기 과제에서 자율 오류 복구 능력을 촉발, 일반 인스트럭션 경로에서는 거의 나타나지 않는다.
**7. 결론 및 전망**
IQuest‑Coder‑V1은 코드 흐름 학습, 초장문 처리, 사고·지시 이중 경로라는 세 축을 결합해 현재 오픈‑소스 코드 LLM이 직면한 장기 추론·에이전트 행동 격차를 크게 줄였다. 전체 학습 체인(Pre‑Stage‑1 → Pre‑Stage‑2 → Mid‑32k → Mid‑128k → Thinking/Instruction)과 모델 체크포인트를 모두 공개함으로써, 연구 커뮤니티가 코드 LLM의 논리·에이전시 능력 형성 메커니즘을 심층적으로 탐구할 수 있는 기반을 제공한다. 향후 연구는 (1) 더 큰 파라미터 규모와 멀티‑모달(코드 + 다이어그램) 통합, (2) 실시간 에이전트 루프 최적화, (3) 안전·정책 제어와 같은 윤리적 측면을 포함한 확장으로 이어질 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기