오마닉: 대형 언어 모델의 다중 홉 추론을 단계별로 평가하는 새로운 벤치마크
오마닉은 4단계 다중 홉 질문과 각 단계의 하위 질문·정답을 제공하는 오픈 도메인 QA 데이터셋이다. 10,296개의 기계 생성 학습 샘플(OmanicSynth)과 967개의 전문가 검증 평가 샘플(OmanicBench)로 구성된다. 최신 LLM들은 CoT 프롬프트에서도 평균 73% 수준의 정확도에 머물며, 지식 부족 시 성능이 급감하고 오류가 뒤쪽 홉으로 전파되는 현상이 확인되었다. 또한 OmanicSynth로 미세조정한 모델은 여섯 개의 외…
저자: Xiaojie Gu, Sherry T. Tong, Aosong Feng
본 논문은 대형 언어 모델(LLM)의 다중 홉 추론을 정밀하게 평가하기 위한 새로운 데이터셋 ‘오마닉(Omanic)’을 제안한다. 기존 HotpotQA·MuSiQue와 같은 다중 홉 QA 벤치마크는 최종 정답만을 제공해 중간 추론 과정을 관찰하기 어렵고, 단계별 오류 원인 분석이 제한적이었다. 이를 해결하고자 연구팀은 (1) 4단계 다중 홉 질문을 설계하고, 각 단계마다 하위 질문과 정답을 명시한 구조적 어노테이션을 제공한다. 데이터는 두 부분으로 구성된다. 첫 번째는 10,296개의 기계 생성 학습 샘플(OmanicSynth)이며, 두 번째는 967개의 전문가 검증 평가 샘플(OmanicBench)이다.
데이터 구축 과정은 다음과 같다. MuSiQue의 2‑hop 질문 정답을 시작점으로 삼아 Wikidata‑5M에서 (주어, 관계, 객체) 삼중항을 추출한다. 이후 Claude‑Sonnet‑4.5를 활용해 도메인 제약(역사·문학·예술 등 8가지)과 사전 정의된 그래프 토폴로지(Bridge, Chain, Star 중 하나) 안에서 새로운 단일 홉 질문을 합성한다. 각 4‑hop 인스턴스는 반드시 하나 이상의 수학적 홉을 포함하도록 설계돼, 수치 연산(비교·집계·계산 등)이 다른 사실 추론과 얽히게 만든다. 생성된 질문은 4개의 선택지를 포함하고, 각 홉마다 3개의 방해 선택지를 추가한다.
품질 관리를 위해 자동 필터링 단계에서 4개의 강력한 LLM을 이용해 정답률이 2개 이상인 샘플을 제거했으며, 이를 통해 난이도 상한을 유지했다. 이후 1,172개의 후보를 10명의 대학생·대학원생 annotator가 300시간 이상 검수했다. 검수 과정에서는 (1) 각 서브질문의 사실 정확성, (2) 수학적 연산의 단계별 계산, (3) 전체 추론 체인의 논리 일관성, (4) 선택지의 설득력 등을 평가하고, 기준에 미달하는 경우 수정·배제했다. 최종적으로 967개의 고품질 평가 샘플이 확보되었다.
실험에서는 최신 상용 모델(GPT‑5.4, Claude‑Sonnet‑4.6, Gemini‑3.1‑flash‑lite, Qwen3‑Max)와 오픈소스 모델(Qwen3‑8B, LLaMA‑3.3‑70B 등)을 직접 답변(Direct)과 체인‑오브‑Thought(CoT) 프롬프트 두 방식으로 평가했다. MCQ 정확도 기준으로 Claude‑Sonnet‑4.6 CoT가 73.11%로 최고였으며, 다른 모델들도 CoT 적용 시 10~20% 정도 정확도가 상승했다. 그러나 전체 정확도는 73%에 머물러, 오마닉이 높은 난이도를 유지함을 확인했다.
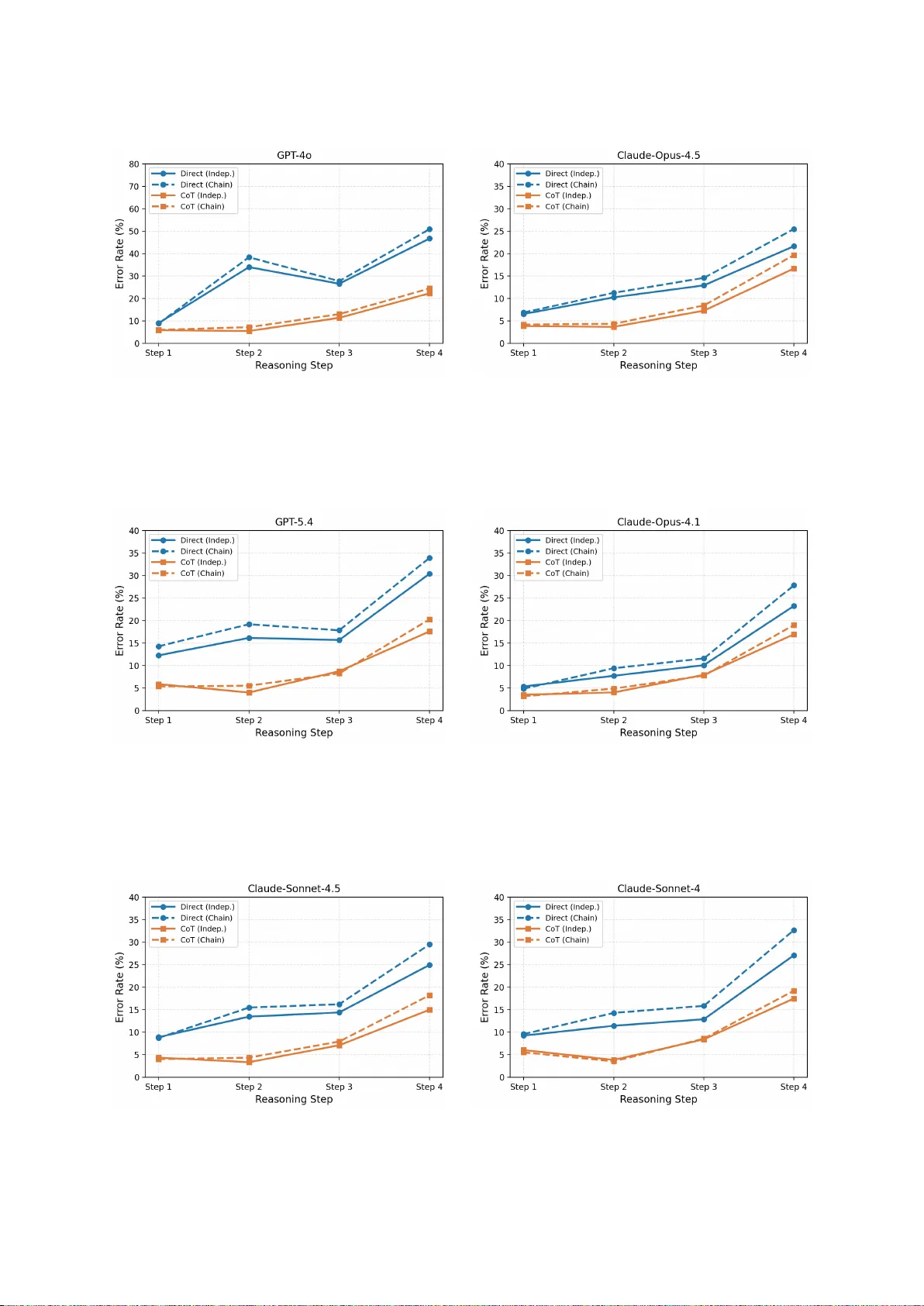
오마닉의 단계별 어노테이션을 활용해 두 가지 연구 질문을 탐색했다. 첫 번째는 CoT가 충분한 지식 기반에 얼마나 의존하는가였으며, 각 단일 홉의 정답 여부에 따라 다중 홉 정확도가 크게 변한다는 ‘지식 바닥(Knowledge Floor)’ 현상을 발견했다. 즉, 모든 단일 홉이 정확할 때 CoT는 +21.9%의 큰 이득을 제공하지만, 오류가 하나라도 발생하면 이득이 급감한다. 두 번째는 오류 전파 현상이다. 독립 평가(각 홉에 금골 답 제공)와 체인 평가(이전 홉의 출력을 다음 홉에 전달) 결과를 비교했을 때, 뒤쪽 홉일수록 오류율이 자연스럽게 높아지며, 체인 평가에서는 오류가 누적돼 4번째 홉에서 33%까지 상승했다. 이는 다중 홉 추론이 뒤쪽 단계일수록 취약함을 정량적으로 보여준다.
전이 학습 실험에서는 OmanicSynth로 SFT( supervised fine‑tuning )한 모델을 기존 추론·수학 벤치마크(MATH, GSM‑8K, etc.)에 적용했다. 모든 외부 벤치마크에서 평균 7.41점(%) 향상이 관찰되었으며, 이는 OmanicSynth가 단순 사실 매칭을 넘어 복합 논리·수학 연산을 학습시키는 고품질 데이터임을 입증한다.
논문의 한계도 명시한다. 현재 영어 전용이며, 4‑hop 제한으로 인해 더 긴 추론 체인(6‑hop, 8‑hop 등)에 대한 평가가 부족하고, 도메인 다양성이 법률·생명과학 등 특수 분야에 미치지 못한다. 데이터 규모도 10k 수준으로 중간 규모에 머물러, 더 큰 규모의 지식 그래프와 결합한 확장이 필요하다.
결론적으로 오마닉은 (1) 단계별 정답 라벨을 제공해 LLM의 추론 과정을 디버깅하고, (2) 사실·수학·그래프 토폴로지를 결합한 복합 추론을 요구해 실제 응용에 가까운 평가를 가능하게 하며, (3) 고품질 인간 검증과 자동 난이도 조절을 통해 벤치마크의 신뢰성을 확보한 점에서 의미가 크다. 향후 다국어·다단계·전문 도메인 확장과 더 큰 규모의 데이터 구축이 진행된다면, LLM의 복합 추론 능력 향상을 위한 핵심 평가 도구로 자리매김할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기