핀오키오: 규범 준수 강화학습을 위한 종단 파이프라인
본 논문은 강화학습 에이전트가 사회적·법적 규범을 준수하도록 설계된 종단 파이프라인 π‑NoCCHIO를 제안한다. AJAR, Jiminy, NGRL을 결합한 하이브리드 구조와 자동 규범·주장 추출 알고리즘, 그리고 ‘규범 회피’ 현상의 정의와 완화 전략을 제시한다. 다양한 시뮬레이션 환경에서 정량·정성 평가를 수행해 제안 방법의 효용성을 입증한다.
저자: Benoît Alcaraz
본 논문은 “핀오키오”라는 이름의 가상의 인형을 강화학습 에이전트에 비유하며, 사회적·법적 규범을 준수하는 지능형 시스템을 설계하기 위한 종단 파이프라인을 제시한다. 서론에서는 AI가 일상에 깊숙이 침투하면서 규범 준수의 필요성이 대두됨을 강조하고, 핀오키오 이야기를 통해 ‘규범적 의식(Jiminy)’과 ‘자율적 목표 추구’를 대비시킨다.
제2장에서는 강화학습, 규범 이론, 형식 논증을 각각 소개하고, 기존 AJAR 프레임워크가 어떻게 논거 그래프를 구성하는지, Jiminy 아키텍처가 규범 감시자로서 어떤 역할을 하는지, NGRL이 보상과 규범을 어떻게 결합하는지를 정리한다.
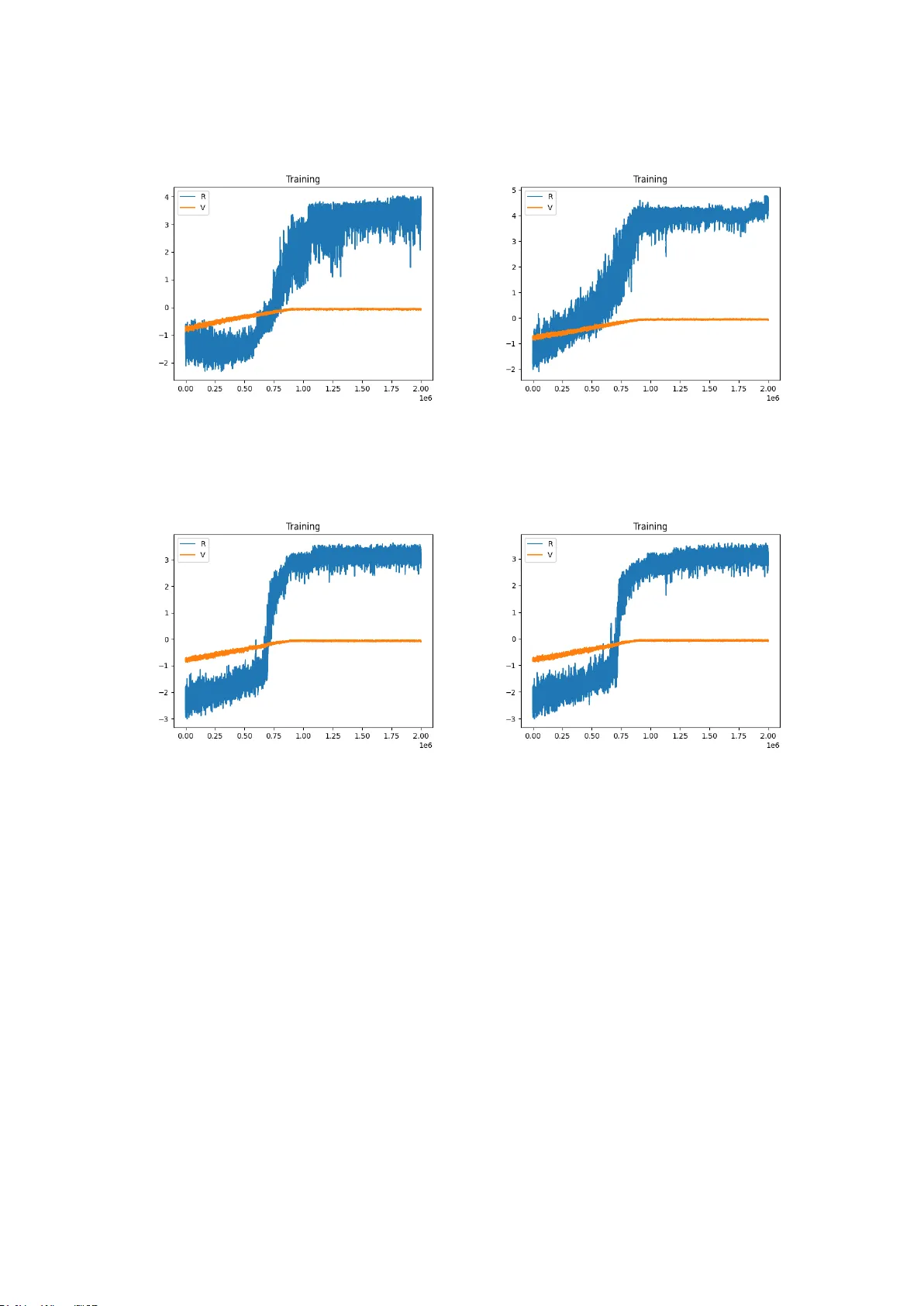
제3장에서는 핵심 설계인 π‑NoCCHIO 아키텍처를 상세히 설명한다. 에이전트는 전통적인 RL 학습 루프와 별도로 ‘Context‑Aware Normative Reasoning’ 모듈을 통해 현재 상태에 대한 사실 집합을 추출하고, 이를 기반으로 주장과 반박을 포함한 논거 그래프를 생성한다. δ‑lexicographic selection 알고리즘은 보상(Q‑값)과 규범 위반 점수 사이의 사전순 우선순위를 정의해, 두 목표를 동시에 최적화한다. 또한 ‘Normative Supervisor’가 에이전트의 행동을 실시간으로 검증하고, 위반 시 즉시 피드백을 제공한다. 실험에서는 Taxi‑A/B/C/D 네 가지 교통 시뮬레이션을 사용해 RL‑Lex와 RL‑DLex(규범 가중치가 강화된 버전)와 비교했으며, π‑NoCCHIO가 보상 수렴 속도와 규범 위반 감소 모두에서 우수함을 보였다.
제4장에서는 규범을 자동으로 추출하는 ‘Argumentative Rule Induction’ 알고리즘을 제시한다. 데이터셋(자동차 속성, 교통 사건 등)에서 n‑argument와 bipolar argumentation 구조를 도출하고, 이를 통해 규범‑관계 그래프를 구축한다. 정량적 평가는 SVM 기반 베이스라인 대비 높은 정확도를, 정성적 평가는 인간 평가자가 생성된 설명을 높은 설득력으로 평가한 결과를 제시한다.
제5장에서는 ‘규범 회피(Norm Avoidance)’ 현상을 정의하고, 이를 모델링하기 위해 네 가지 전이 상태(complaint, defeat, non‑compliance, violation)를 도입한다. 회피를 억제하기 위한 두 가지 전략—hard‑penalty와 compliance‑path augmentation—을 설계하고, 실험을 통해 두 전략이 규범 위반을 현저히 감소시키면서도 전체 보상 손실을 최소화함을 입증한다.
제6장과 7장은 관련 연구와 향후 연구 방향을 논의한다. 규범‑준수 에이전트 파이프라인, 비공식·사회적 규범 학습, 가치 정렬과 윤리학 등과의 연관성을 정리하고, 대규모 다중 에이전트 환경, 형식적 보증, 인간‑에이전트 대화 인터페이스 등으로 확장할 필요성을 강조한다.
마지막으로 결론에서는 π‑NoCCHIO가 강화학습과 형식 논증을 결합한 최초의 종단 솔루션임을 강조하고, 자동 규범 추출과 회피 완화라는 두 핵심 문제를 실험적으로 검증했으며, 현재 한계와 향후 연구 과제를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기