ECsim 코드의 OpenACC 기반 GPU 가속화와 exascale 수준 성능 확보
본 논문은 에너지 보존 반암시적 입자‑격자(PIC) 코드인 ECsim을 OpenACC 지시문만으로 GPU 가속화하고, 이탈리아 Leonardo 슈퍼컴퓨터에서 5배 가속·3배 에너지 절감, 64~1024 GPU까지 70 %·78 % 효율을 달성한 과정을 상세히 보고한다.
저자: Elisabetta Boella, Nitin Shukla, Filippo Spiga
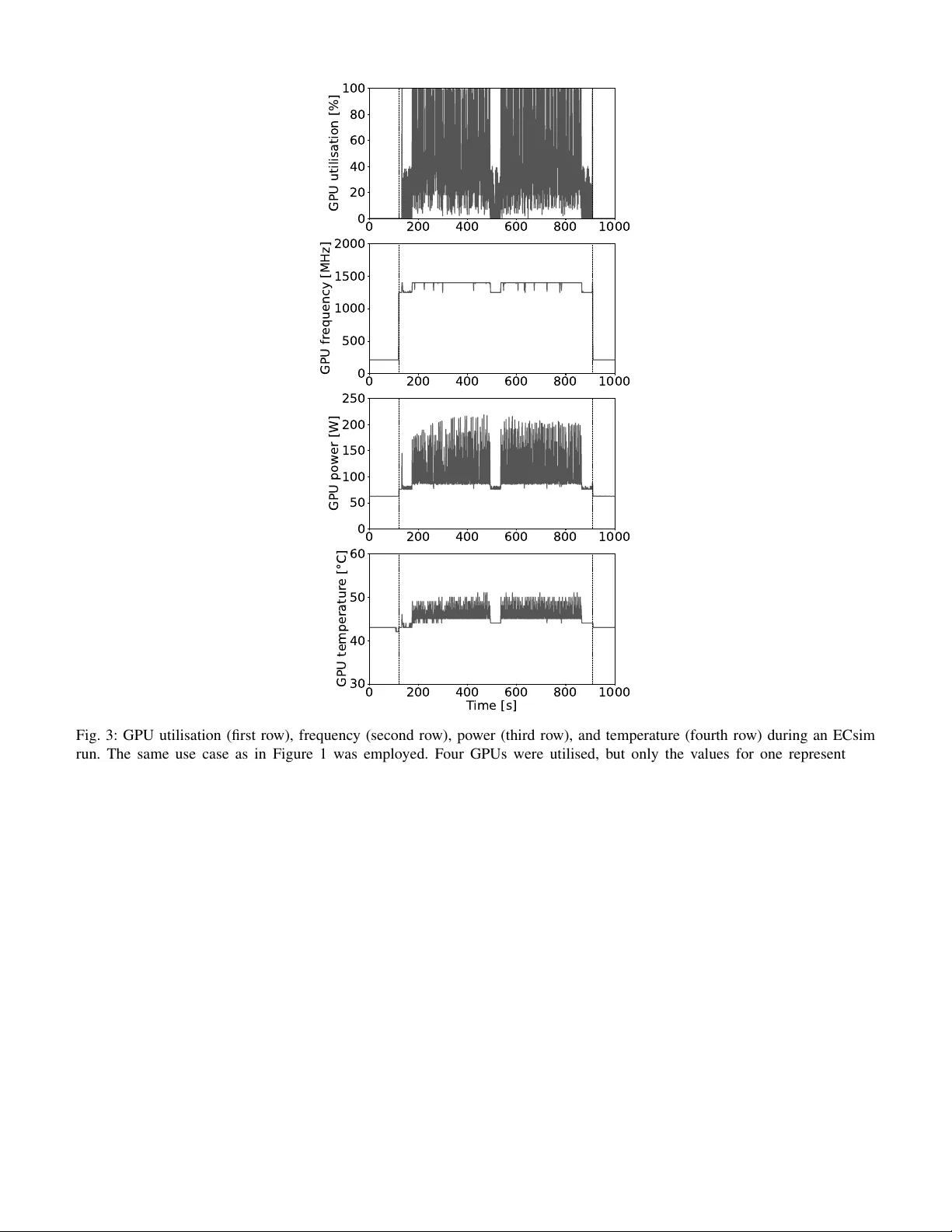
본 논문은 플라즈마 물리학에서 널리 사용되는 입자‑격자(PIC) 방법 중, 에너지 보존을 특징으로 하는 반암시적 알고리즘을 구현한 ECsim 코드를 exascale 수준의 슈퍼컴퓨터에 맞추어 가속화하는 과정을 상세히 기술한다. ECsim은 기존에 MPI 기반으로만 동작했으며, 입자와 격자 간 상호작용을 계산하는 ‘moment gathering’, 전자기장 업데이트를 담당하는 ‘field solver’, 그리고 입자 위치·속도를 갱신하는 ‘particle mover’ 세 가지 핵심 모듈로 구성된다. 특히 ‘moment gathering’ 단계가 전체 실행 시간의 76 %를 차지해 GPU 가속의 주요 목표가 된다.
가속 전략으로 저자들은 OpenACC 지시문을 선택했다. OpenACC는 기존 C/C++ 코드에 최소한의 pragma만 추가하면 GPU 오프로드가 가능하므로, 코드 구조를 크게 변경하지 않고도 높은 성능을 기대할 수 있다. 구체적으로는 입자 이동 루프(`updateVelocity`, `updatePosition`, `fixPosition`)와 전류·질량 행렬 계산 루프(`computeMoments`)에 `#pragma acc parallel loop` 를 삽입하였다. 데이터 전송을 자동화하기 위해 초기에는 명시적 데이터 관리 절차를 생략했으며, 이후 메모리 레이아웃을 최적화하기 위해 3‑차원 포인터를 1‑차원 배열로 평탄화하고, 질량 행렬을 대칭성을 이용해 14개만 저장하도록 설계하였다.
‘moment gathering’에서는 각 입자가 2³=8개의 격자점에 기여하도록 가중치(`W_pN`)를 계산하고, 입자 위치에서의 자기장을 보간한다. 이 과정에서 중첩된 2×2×2 루프를 수동 언롤링해 메모리 코얼레싱을 개선했으며, 회전 행렬(`α`)을 3×3 배열 대신 9개의 스칼라 변수로 분리해 데이터 접근을 단순화했다. 또한 전류(`Ĵ`)와 질량 행렬(`M_ij`)를 각각 4‑차원·4‑차원 배열로 관리하면서, GPU 메모리 사용량을 최소화하기 위해 불필요한 차원을 제거하였다.
성능 평가에서는 이탈리아 CINECA의 pre‑exascale 시스템 Leonardo의 Booster 파티션을 사용했다. 각 노드에는 32코어 Intel Xeon Platinum 8358 CPU와 4개의 NVIDIA A100 GPU가 장착되어 있다. 테스트 케이스는 256 × 128 격자, 4종 플라즈마, 셀당 60 × 60 입자를 100 타임스텝 진행하는 2‑D 전류 필라멘테이션 불안정 시뮬레이션이다. CPU‑MPI 기준(32 MPI 랭크)과 비교했을 때, GPU‑OpenACC 구현은 전체 실행 시간을 5배 단축하고 전력 소비를 3배 절감했다.
다양한 NVIDIA GPU(A100, H100, 최신 GH200)에서의 커널 실행 시간 비교에서는, 특히 GH200의 통합 메모리 아키텍처가 데이터 전송 오버헤드를 크게 낮춰 추가 1.2배~1.4배 가속을 제공했다. 강한 스케일링 실험에서는 1노드에서 64노드(256 GPU)까지 70 % 효율을 유지했으며, 약한 스케일링에서는 1024 GPU까지 78 % 효율을 기록했다. 이는 MPI 통신 비용이 GPU 연산에 비해 상대적으로 작아졌음을 의미한다.
OpenACC 선택 이유에 대해서는 현재 NVIDIA 컴파일러가 OpenACC를 더 안정적으로 지원하고, OpenMP‑offload 대비 최적화 옵션이 풍부하다는 점을 들었다. 또한, 유럽의 주요 pre‑exascale·exascale 시스템이 NVIDIA GPU를 채택하고 있기 때문에, OpenACC 기반 구현이 향후 포팅 비용을 최소화한다는 실용적 장점도 강조한다.
결론적으로, 최소한의 코드 변경으로 ECsim을 GPU 가속화하고, exascale 수준의 성능·에너지 효율을 달성한 본 연구는 반암시적 PIC 코드가 차세대 슈퍼컴퓨팅 환경에 적합하도록 전환될 수 있음을 입증한다. 향후 연구 방향으로는 다중 GPU 간 직접 P2P 메모리 전송, CPU‑GPU 하이브리드 파이프라인, 자동 튜닝 프레임워크와의 연계, 그리고 에너지 보존을 유지하면서도 스무딩 기법을 적용하는 방법론이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기