수학 추론을 위한 비지도 RL, 언제 성공하고 왜 실패하는가: 매니폴드 포위 시각
본 논문은 비지도 강화학습(RL)에서 수학 문제 해결 능력을 끌어올리기 위한 내재 보상 설계와, 모델의 논리적 사전능력에 따른 성공·실패 경계, 그리고 훈련 동역학을 기하학적으로 진단하는 매니폴드 포위 현상을 제시한다. 짧고 확신에 찬 답변을 강제하는 보상이 효과적이며, 고성능 기반 모델에서는 안정적인 매니폴드가 형성돼 성능이 크게 향상된다. 반면, 약한 모델이나 불안정한 보상 조합에서는 매니폴드가 흐트러져 정책 붕괴가 발생한다.
저자: Zelin Zhang, Fei Cheng, Chenhui Chu
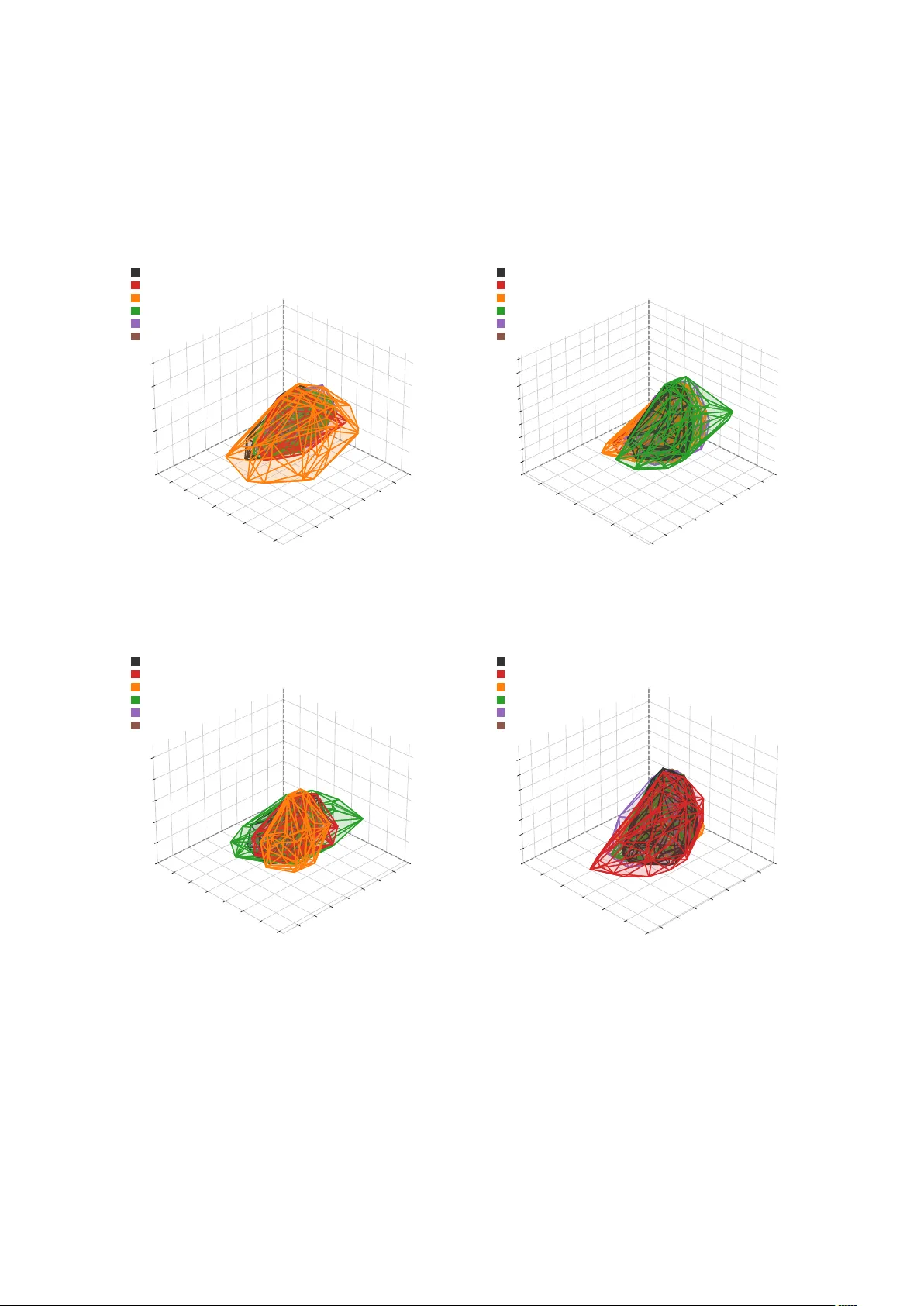
본 논문은 대형 언어 모델(LLM)의 수학 추론 능력을 향상시키기 위한 비지도 강화학습(Unsupervised RL) 접근법을 체계적으로 탐구한다. 기존의 결과 기반 RL(Outcome‑based RL)은 정답 라벨에 의존해 높은 연산 비용과 데이터 확보의 어려움을 야기한다. 이를 극복하고자 저자는 내재 보상(intrinsic reward)을 설계해 모델이 외부 정답 없이도 스스로 간결하고 확신에 찬 답변을 생성하도록 유도한다.
### 1. 내재 보상 설계
보상은 두 축, 즉 ‘불확실성(uncertainty)’과 ‘길이(length)’를 독립적으로 조절한다. 기존 방법인 Shannon Entropy(Ent)와 평균 엔트로피(AvgEnt)는 불확실성을 최소화하지만, Ent는 길이에도 암묵적인 패널티를 부여한다. 새롭게 제안된 Length Penalty(LP)는 토큰 수만을 직접 벌점화해 짧은 답변을 강제한다. Cumulative Rényi Entropy(CH2)는 엔트로피 계산 시 확률을 제곱해 긴 꼬리 확률을 무시함으로써 길이 패널티를 완화한다. 마지막으로 Collision Probability(CP)는 확률 제곱을 누적해 토큰 수가 늘어날수록 보상이 증가하도록 설계해 불확실성 억제와 길이 증가 사이의 갈등을 의도적으로 만들었다.
### 2. 모델 및 데이터 다양성
실험은 세 단계의 논리 사전능력을 가진 모델을 대상으로 진행되었다. 가장 강력한 Qwen‑3 8B/1.7B는 사전 정렬된 ‘think’ 모드와 풍부한 수학 데이터로 학습된 상태이며, 중간 단계인 DeepSeek‑Distill‑Llama‑8B는 Llama‑3 기반을 교사 모델로부터 증류해 논리 능력이 강화된 버전이다. 가장 약한 Llama‑3.1‑8B는 순수 지도 학습(SFT)만 거친 모델이다. 훈련 데이터는 DAPO‑Math‑17K와 DeepMath‑103K를 사용했으며, 평가 벤치마크는 MATH500, Minerva Math, OlympiadBench, AIME24, AMC23, 그리고 OOD 테스트용 AIME26을 포함한다.
### 3. 훈련 및 평가 프로토콜
비지도 RL은 GRPO(Group Relative Policy Optimization)를 활용해 보상 기반 정책 업데이트를 수행한다. 각 프롬프트에 대해 G개의 롤아웃을 생성하고, 보상 평균과 표준편차를 이용해 상대적 어드밴티지를 계산한다. KL 정규화는 제외했으며, 이는 엔트로피 기반 보상과 중복되기 때문이다. 훈련은 조기 종료(Early Stopping) 전략을 적용해 검증 성능이 최고점에 도달하면 즉시 중단한다. 정책 붕괴가 지속적으로 나타나는 경우는 ‘collapse’로 간주하고 상세 수치는 보고하지 않는다.
### 4. 실험 결과
표 2에 따르면, CP를 제외한 모든 내재 보상은 Qwen‑3 모델에서 기존 지도 학습 기반 S‑RL을 능가한다. 특히 LP는 가장 높은 전체 정확도를 기록했으며, Ent와 CH2도 유의미한 향상을 보였다. DeepSeek‑Distill‑Llama‑8B에서는 성능 향상이 제한적이었으며, S‑RL이 여전히 우위에 있었다. 가장 약한 Llama‑3.1‑8B는 대부분의 보상에서 초기 개선이 없거나 곧바로 정책 붕괴가 발생했다. 이는 모델의 논리 사전능력이 충분히 강하지 않으면 내재 보상이 충분히 작동하지 않음을 시사한다.
### 5. 매니폴드 포위 기하학적 진단
훈련 동역학을 이해하기 위해 저자는 토큰 수준 엔트로피 변화를 DTW(Dynamic Time Warping) 기반 클러스터링으로 그룹화하고, 이를 3차원 위상공간에 투영했다. 세 개의 클러스터는 각각 ‘Execution(저엔트로피)’, ‘Logic(중엔트로피)’, ‘Thinking(고엔트로피)’ 상태에 대응한다. 성공적인 훈련에서는 이 세 클러스터가 매끄럽게 연결된 얇은 매니폴드 위를 따라 이동하며, trajectory가 제한된 영역에 머무른다. 반면 실패 사례는 클러스터 간 전이가 무질서하게 발생하거나 매니폴드가 넓게 퍼져 ‘혼돈’ 상태를 만든다. 이러한 매니폴드 포위 현상은 모델이 논리적 일관성을 유지하고 있는지를 시각적으로 판단할 수 있는 새로운 진단 도구를 제공한다.
### 6. 인사이트 및 한계
- **불확실성 억제와 길이 억제의 동시 적용**이 가장 견고한 매니폴드를 형성한다. 이는 모델이 불필요한 토큰을 생성하면서도 확신을 갖지 못하는 상황을 방지한다.
- **모델 사전능력**이 성공·실패를 결정한다. 고성능 모델은 내재 보상의 신호를 효과적으로 활용해 매니폴드 위를 안정적으로 탐색하지만, 약한 모델은 신호를 오해하거나 과도하게 탐색해 붕괴한다.
- **CP와 같은 상충 보상**은 불확실성 최소화와 길이 증가 사이의 갈등을 극대화해 훈련을 불안정하게 만든다. 이는 보상 설계 시 상충 요소를 최소화해야 함을 보여준다.
- **매니폴드 기반 진단**은 정책 붕괴를 사전에 감지하고, 보상 조합을 조정하는 실용적인 피드백 루프를 제공한다.
### 7. 결론
논문은 비지도 RL이 적절한 내재 보상 설계와 모델 사전능력에 따라 수학 추론 성능을 크게 향상시킬 수 있음을 실증한다. 특히, 짧고 확신에 찬 답변을 강제하는 LP와 Ent는 고성능 모델에서 S‑RL을 능가했으며, 매니폴드 포위 현상을 통해 성공과 실패를 기하학적으로 구분할 수 있었다. 향후 연구는 보다 다양한 논리 도메인에 적용하고, 매니폴드 진단을 자동화해 훈련 중 실시간 안정성 모니터링을 구현하는 방향으로 확장될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기