도메인 특화 코드 생성 위한 소형 모델 맞춤 전략 비교
본 논문은 파이썬 생태계 내 일반 프로그래밍, Scikit‑learn 머신러닝, OpenCV 컴퓨터비전 세 분야에서 합성 데이터셋을 이용해 소형 오픈소스 코드‑생성 모델을 맞춤화하는 세 가지 방법(few‑shot 프롬프팅, RAG, LoRA 파인‑튜닝)을 비교한다. 평가 지표는 기능적 정확성을 측정하는 벤치마크와 도메인 특화 코드와의 유사성을 측정하는 메트릭이다. 결과는 RAG과 few‑shot이 비용 효율적으로 도메인 적합성을 높이지만 정확도…
저자: Luís Freire, Fern, a A. Andaló
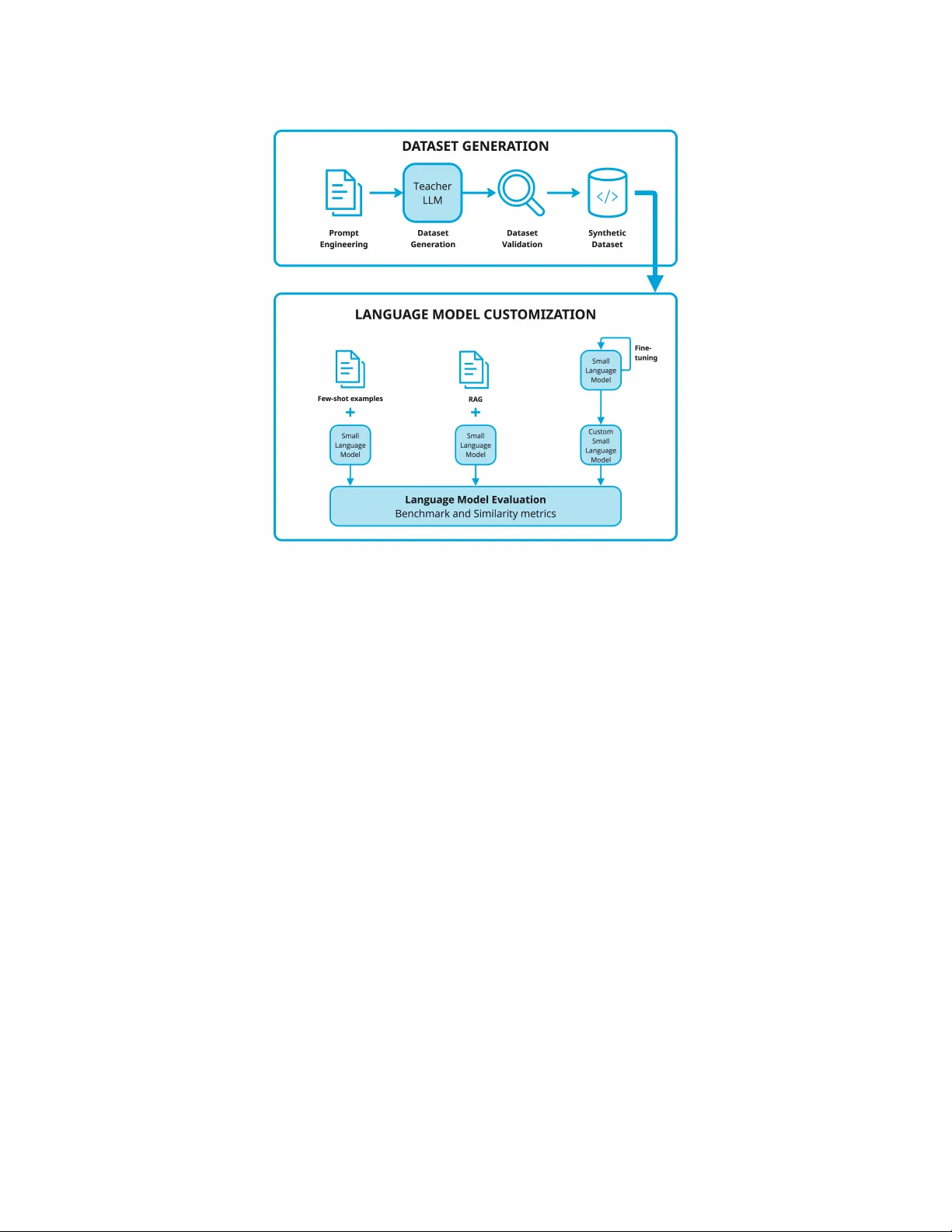
본 논문은 “도메인 특화 텍스트‑투‑코드 생성”이라는 실용적 문제를 다루며, 대형 상용 LLM의 높은 비용·배포 제약을 회피하기 위해 소형 오픈소스 모델을 어떻게 맞춤화할 수 있는지를 체계적으로 조사한다. 연구는 크게 네 부분으로 구성된다.
1) **데이터 구축**
- 교사 모델로 GPT‑4o를 사용해 파이썬 기반의 세 도메인(일반 파이썬, Scikit‑learn, OpenCV)에서 각각 약 21,600개의 프로그래밍 과제를 자동 생성하였다.
- 각 과제는 자연어 문제 설명을 docstring 형태로 포함하고, 필요한 import와 주석이 달린 완전한 파이썬 구현을 제공한다.
- 토픽, 직업군, 난이도, 사용자 인터랙션, 오류 처리 여부 등 5가지 제어 변수를 프롬프트에 삽입해 다양성을 확보하였다.
- 생성된 샘플은 구문·의미 검증 파이프라인을 통해 필터링했으며, 최종적으로 도메인별 5,000개 정도의 샘플을 상세 분석하였다. 통계적으로 샘플 길이는 300~700 토큰 사이였고, 일반 파이썬은 설명이 길고 Scikit‑learn·OpenCV는 코드량이 다소 많았다.
2) **맞춤화 전략**
- **Few‑shot 프롬프팅**: 4~5개의 인‑컨텍스트 예시를 프롬프트에 삽입해 모델에 도메인 지식을 전달한다. 파라미터 업데이트 없이 즉시 적용 가능하지만, 컨텍스트 길이 제한과 예시 선택에 민감하다.
- **Retrieval‑Augmented Generation (RAG)**: 외부 인덱스(FAISS 기반)에서 질의와 가장 유사한 도메인 예시를 실시간 검색해 프롬프트에 추가한다. 검색 엔진 구축·유지 비용이 필요하지만, 최신 라이브러리 버전에 대한 적응성을 제공한다.
- **LoRA 파인‑튜닝**: 선택된 트랜스포머 레이어에 저‑랭크 행렬을 삽입해 파라미터 수를 0.5% 이하로 제한하면서도 도메인 데이터에 대해 3~5 epoch 정도 학습한다. StarCoder와 DeepSeekCoder 두 모델에 적용했으며, GPU 메모리 사용량은 기존 파인‑튜닝 대비 10배 이하였다.
3) **평가 지표**
- **벤치마크 기반 정확도**: HumanEval‑style 테스트 케이스를 자동 실행해 기능적 정답률(pass@1, pass@10)을 측정한다.
- **유사도 기반 도메인 정렬**: CodeBLEU와 AST‑Edit‑Distance를 활용해 생성 코드와 레퍼런스 코드 사이의 구조·시맨틱 유사성을 평가한다. 특히 API 호출 순서와 파라미터 사용 일치를 중점적으로 측정했다.
4) **실험 결과 및 분석**
- **Few‑shot**은 일반 파이썬 도메인에서 약간의 pass@1 상승을 보였지만, Scikit‑learn·OpenCV에서는 API 사용 오류가 빈번해 정확도 향상이 미미했다. 유사도 점수는 약 5% 정도 상승했다.
- **RAG**은 검색된 예시가 도메인 특화 정보를 제공함에 따라 API 사용 정확도가 개선되었으며, pass@1이 few‑shot 대비 2~3% 상승했다. 그러나 검색 비용과 프롬프트 길이 제한으로 인해 대규모 배포 시 스루풋이 감소한다.
- **LoRA 파인‑튜닝**은 모든 도메인에서 가장 높은 pass@1(일반 파이썬 38%, Scikit‑learn 45%, OpenCV 42%)과 CodeBLEU 점수(일반 파이썬 0.71, Scikit‑learn 0.78, OpenCV 0.75)를 기록했다. 특히 복잡한 파이프라인(데이터 전처리 → 모델 학습 → 평가)을 요구하는 Scikit‑learn 과제에서 파인‑튜닝 모델은 정확히 올바른 파라미터와 메서드 체인을 사용했다.
- **비용·시간 측면**: Few‑shot은 인프라 비용이 거의 없으며 즉시 적용 가능하지만 성능 한계가 있다. RAG은 검색 인덱스 구축에 약 8시간, 매 추론당 0.2초 추가 지연이 발생한다. LoRA는 2~3시간의 학습 비용이 필요하지만, 학습 후 로컬 배포 시 추론 비용은 기본 모델과 동일하다.
5) **시사점 및 한계**
- 도메인 특화 코드 생성에서 가장 효율적인 방법은 목표 성능과 배포 환경에 따라 선택해야 한다. 빠른 프로토타이핑이나 비용이 극히 제한된 상황에서는 few‑shot이나 RAG이 충분히 실용적이다. 반면, 높은 정확도와 장기적인 유지보수가 요구되는 기업 환경에서는 LoRA 파인‑튜닝이 최선이다.
- 연구는 합성 데이터에 의존했기 때문에 실제 사용자 요구와의 차이가 존재한다. 또한, 현재는 파이썬 하나의 언어에 국한했으며, 다른 언어(예: JavaScript, Rust)에서의 일반화 가능성은 추가 연구가 필요하다.
결론적으로, 소형 오픈소스 모델을 도메인에 맞게 맞춤화하는 세 가지 전략을 체계적으로 비교함으로써, 비용·성능·배포 용이성 사이의 트레이드오프를 명확히 제시한다. 이는 기업·연구기관이 자체 코딩 어시스턴트를 구축할 때 실용적인 로드맵을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기