스파이킹 신경망을 위한 선형화된 브레그만 최적화와 AdaBreg 적용
본 논문은 스파이킹 신경망(SNN) 학습에 선형화된 브레그만 반복(LBI)을 적용하고, 모멘텀·바이어스 보정 기능을 갖춘 AdaBreg 옵티마이저를 도입한다. SHD, SSC, PSMNIST 세 벤치마크에서 LBI 기반 학습은 파라미터 수를 약 50% 감소시키면서 Adam 대비 0.5~1.5% 수준의 정확도 손실만을 보였다. λ 정규화 파라미터와 학습률 스케줄링이 sparsity와 성능에 미치는 영향을 정량적으로 분석하고, PyTorch 구현의…
저자: Daniel Windhager, Bernhard A. Moser, Michael Lunglmayr
**1. 연구 배경 및 동기**
스파이킹 신경망(SNN)은 이벤트 기반 처리와 저전력 특성으로 뉴로모픽 하드웨어에 적합하지만, 기존 학습 방법은 여전히 수백만 개의 파라미터를 필요로한다. 특히, 가중치가 밀집된 형태로 저장될 경우 하드웨어 매핑 시 메모리와 연산 효율이 저하된다. 따라서 파라미터 수를 줄이면서도 정확도를 유지하는 희소성 학습이 핵심 과제로 떠오르고 있다. 기존의 프루닝(pruning) 기법은 경험적이며, 최적 해에 수렴한다는 이론적 보장이 부족하다.
**2. 선형화된 브레그만 반복(LBI)의 이론적 토대**
LBI는 ℓ₁ 정규화와 같은 비부드한 함수에 대해 Bregman 거리 D_J를 최소화한다. Bregman 거리 정의는 D_J(x,y)=J(x)-J(y)-⟨∇J(y),x-y⟩이며, 여기서 J는 convex regularizer이다. ℓ₁ 정규화의 경우, ∇J(y)는 서브그라디언트 집합에 속한다. LBI는 그림자 변수 v를 도입해 두 단계 업데이트를 수행한다. 첫 단계에서는 현재 파라미터 θ_t에 대한 손실 함수 L의 그래디언트를 v에 누적(v_{t+1}=v_t+μ∇L(θ_t))하고, 두 번째 단계에서는 v에 소프트 쓰레시홀딩 prox_{λ‖·‖₁}을 적용해 새로운 파라미터 θ_{t+1}=prox_{λ‖·‖₁}(v_{t+1})를 얻는다. 이 과정은 매 반복마다 작은 가중치를 0으로 만들면서 중요한 연결만을 남긴다.
**3. AdaBreg 옵티마이저 설계**
전통적인 LBI는 고정 학습률 μ에 의존해 수렴 속도가 느리다. AdaBreg는 Adam의 적응적 1차·2차 모멘트 추정 방식을 차용한다. 구체적으로, m_t←β₁m_{t-1}+(1-β₁)∇L, s_t←β₂s_{t-1}+(1-β₂)∇L²를 계산하고, bias‑correction을 거친 후 v_t←v_{t-1}+μ·(m̂_t/√(ŝ_t+ε)) 로 업데이트한다. 이후 동일한 prox 연산을 적용한다. 이 설계는 학습률 스케줄링에 대한 의존도를 낮추고, 초기 급격한 수렴을 가능하게 하면서도 안정적인 최종 해를 제공한다.
**4. 실험 설정**
- **데이터셋**: SHD(청각 이벤트), SSC(음성 명령), PSMNIST(시간 순서가 뒤섞인 MNIST).
- **네트워크 구조**: LIF 뉴런 기반 3~4계층 SNN, 중간·후기 레이어에 axonal delay 학습 포함. 상세 구조는 표 1에 제시.
- **하이퍼파라미터**: λ∈{0.1,0.5,1,5,10}, μ=5e‑3~1e‑3, β₁=0.9, β₂=0.999, ε=1e‑8. OneCycleLR 스케줄러와 고정 학습률 두 조건을 비교.
- **평가 지표**: 테스트 정확도, 활성 파라미터 비율(비제로 가중치 비율), 학습 곡선(손실, sparsity).
**5. 주요 결과**
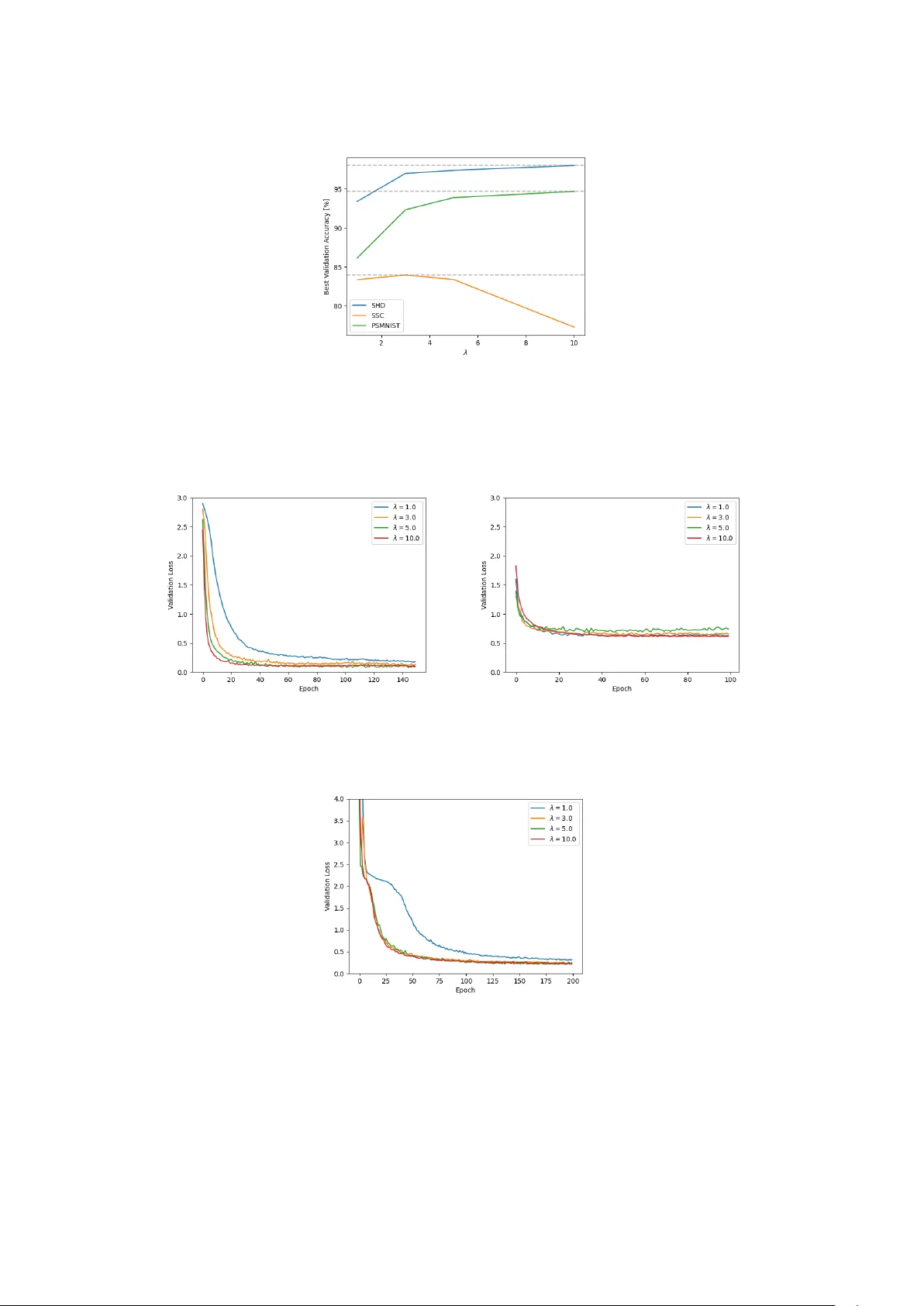
- **손실 및 sparsity**: λ가 클수록 초기 몇 에폭 동안 손실이 빠르게 감소하고, 비제로 가중치 수가 급격히 감소한다. 이후 플래토에 도달해 안정적인 희소성을 유지한다.
- **λ‑학습률 상호작용**: 높은 λ와 높은 초기 학습률을 동시에 사용하면 발산 현상이 발생한다(예: λ=10, lr=5e‑3). 이는 Bregman 거리의 비선형성 때문에 큰 스텝이 과도한 파라미터 변동을 야기하기 때문이다. 따라서 λ 선택은 학습률 및 스케줄링과 공동 최적화가 필요하다.
- **정확도 대비 파라미터 감소**: AdaBreg는 모든 데이터셋에서 평균 48~52%의 활성 파라미터 감소를 달성했으며, Adam 대비 정확도 손실은 0.5~1.5%에 불과했다. 특히 SHD(92.98% vs 93.39%)와 SSC(81.86% vs 82.58%)에서 거의 동일한 성능을 보였다. PSMNIST에서도 95.59% vs 96.21%로 경쟁력을 유지했다.
- **스케줄러 유무 효과**: OneCycleLR 스케줄러를 사용하지 않아도 최종 정확도와 희소성 비율은 크게 변하지 않았다. AdaBreg 자체가 적응적 학습률 조정을 수행하기 때문에 외부 스케줄러가 필수적이지 않다.
- **실용성**: PyTorch에서 Adam → AdaBreg 로 교체하는 한 줄 코드만으로 적용 가능했으며, 기존 SNN 파이프라인을 크게 수정하지 않아도 된다.
**6. 결론 및 향후 과제**
본 논문은 LBI와 AdaBreg를 통해 SNN 학습에 수학적으로 근거 있는 ℓ₁ 기반 희소성을 성공적으로 도입했음을 입증한다. 파라미터 절반 수준으로 감소하면서도 정확도 손실이 미미해, 에너지 제한이 큰 엣지 디바이스에 적합한 학습 방법으로 평가된다. 향후 연구에서는 (1) 하드웨어 수준에서 0‑weight 마스킹을 활용한 전력 절감 효과 측정, (2) 더 복잡한 시계열·멀티모달 데이터에 대한 확장, (3) λ와 학습률을 자동으로 튜닝하는 메타러닝 기법 도입 등을 통해 실용성을 더욱 강화할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기