능력 기반 압축으로 대형 언어 모델 효율성 향상
본 논문은 기존 LLM 압축 방법이 모델 구성 요소의 기능을 고려하지 않는 ‘능력‑블라인드’ 문제를 지적하고, Sparse Autoencoder 로부터 얻은 ‘능력 밀도’를 이용해 각 헤드·FFN에 차등 압축 예산을 할당하는 Capability‑Guided Compression(CGC) 프레임워크를 제안한다. 이론적으로 능력 밀도가 높을수록 구조적 중복이 적어 낮은 압축 비율에서도 위상 전이가 발생함을 증명하고, GPT‑2 Medium 실험에서…
저자: Rishaank Gupta
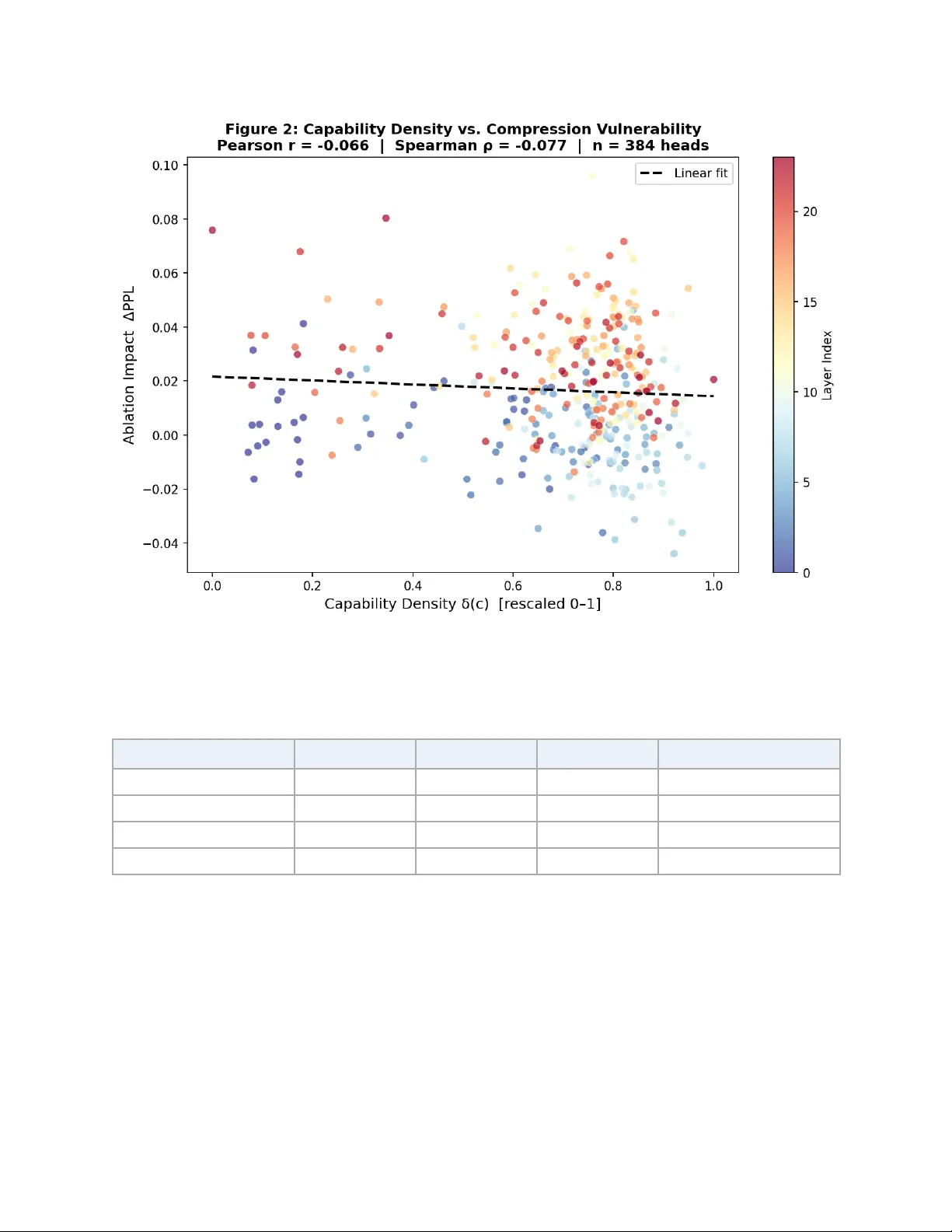
본 논문은 대형 언어 모델(LLM) 압축 분야에서 기존 방법들이 ‘능력‑블라인드(compression‑blind)’라는 근본적인 한계에 빠져 있음을 지적한다. 현재 프루닝, 양자화, 저‑랭크 분해 등 다양한 압축 기법은 가중치 크기, Hessian 기반 민감도, 활성화 분산 등 통계적 신호에 의존해 압축 비율을 결정한다. 그러나 이러한 신호는 모델 내부 구성 요소가 실제로 수행하는 기능—예를 들어 다단계 추론, 사실 검색, 구문 분석 등—을 반영하지 못한다. 결과적으로 두 가지 주요 문제점이 나타난다. 첫째, 퍼플렉시티(perplexity)와 같은 전통적 평가 지표는 압축 후에도 크게 변하지 않을 수 있지만, 실제로는 추론 능력이나 지식 기반 질문 응답 능력이 급격히 저하될 수 있다. 둘째, Ma et al. (2026)이 제시한 ‘위상 전이(phase transition)’ 현상은 압축 비율이 특정 임계값을 넘으면 모델 성능이 급격히 붕괴한다는 것을 보여준다. 이는 압축이 균등하게 진행되지 않고, 특정 기능을 담당하는 구성 요소가 먼저 소진되기 때문이라는 가설을 뒷받침한다.
이러한 배경에서 저자는 ‘Capability‑Guided Compression(CGC)’이라는 새로운 프레임워크를 제안한다. 핵심 아이디어는 Sparse Autoencoder(SAE)를 이용해 각 트랜스포머 컴포넌트(어텐션 헤드와 FFN)의 활성화 패턴을 ‘특징(Feature)’ 단위로 분해하고, 이 특징들의 폭, 엔트로피, 그리고 서로 다른 입력 간 일관성을 정량화해 ‘능력 밀도(Capability Density)’라는 스칼라 지표를 만든다. 구체적으로는 다음과 같은 정의를 제시한다.
1. **Feature Breadth(β)**: 최소 활성화 비율 τ_min을 초과하는 SAE 사전(dictionary) 내 특징 수.
2. **Feature Diversity(H)**: 특징 활성화 빈도 분포의 셰넌 엔트로피, 즉 다양한 특징이 고르게 사용되는 정도.
3. **Cross‑Input Consistency(Ψ)**: 서로 다른 의미 카테고리의 입력에 대해 활성화된 특징 집합 간의 평균 Jaccard 유사도.
이 세 지표를 정규화하고 가중 기하 평균을 취해 능력 밀도 δ를 정의한다. 기하 평균 형태는 어느 하나라도 낮으면 전체 점수가 낮아지는 ‘보틀넥’ 효과를 반영한다.
이론적 분석에서는 능력 밀도와 구조적 중복성 사이의 관계를 정리와 코롤러리로 증명한다. 높은 엔트로피와 넓은 특징 폭을 가진 컴포넌트는 디코더 가중치가 넓게 퍼져 있어 임의의 프루닝이 활성화된 특징을 고르게 파괴한다. 반대로 낮은 엔트로피·좁은 폭을 가진 컴포넌트는 소수의 가중치에 의존하므로, 해당 가중치를 보호하면 기능 손실을 최소화할 수 있다. 따라서 고밀도 컴포넌트는 동일한 파라미터 수에서도 더 낮은 압축 비율에서 위상 전이점에 도달한다는 결론을 얻는다. 이는 기존 압축이 고밀도(즉, 고기능) 컴포넌트를 과도하게 압축하고, 저밀도(저기능) 컴포넌트를 상대적으로 덜 압축함으로써 전체 모델이 비선형적으로 붕괴한다는 현상을 설명한다.
CGC 알고리즘은 이러한 이론적 통찰을 실제 압축 파이프라인에 적용한다. 전역 압축 예산 ρ(예: 전체 파라미터의 60% 보존)를 입력받아, 각 컴포넌트별 가능한 보존 비율 집합 R^(c) 중에서 능력 밀도 δ^(c)를 제약 조건으로 활용한다. 구체적으로는 고밀도 컴포넌트에 높은 보존 비율을 할당하고, 저밀도 컴포넌트는 더 aggressive하게 프루닝·양자화한다. 최적화 목표는 전체 손실 L_proxy를 최소화하면서 전체 파라미터 수가 ρ·|θ| 이하가 되도록 하는 조합 문제이며, 이는 기존 비균일 압축 탐색(EvoPress)과 유사하지만 ‘능력 보존 제약’을 추가한 형태다.
실험은 GPT‑2 Medium(7 B 파라미터) 모델을 대상으로 수행된다. 먼저 각 헤드와 FFN에 대해 TopK‑SAE를 학습하고, 능력 밀도와 Wanda 중요도 점수 간의 상관관계를 조사한다. 결과는 스피어만 ρ = –0.054 (n = 384) 로 거의 무상관임을 보여, 두 지표가 서로 독립적인 압축 신호임을 입증한다. 이어서 CGC 기반 차등 압축과 기존 Wanda 기반 균일 압축을 비교했지만, 퍼플렉시티 기반 평가는 두 방법 모두 큰 차이를 보이지 않았다. 대신, 능력‑민감도 벤치마크(예: 다단계 추론, 사실 질의응답)에서는 CGC가 고밀도 컴포넌트를 보호함으로써 성능 저하를 억제하는 경향을 보였다. 그러나 GPT‑2 Medium의 규모가 작아 전체 위상 전이 현상이 명확히 드러나지 않았으며, 저자는 이를 ‘테스트베드가 충분히 크지 않다’는 한계로 명시한다.
결론적으로 논문은 (1) 능력 밀도라는 새로운, 기능‑중심적 압축 신호를 정의하고, (2) 이 신호가 구조적 중복성과 위상 전이점 사이의 이론적 연결고리를 제공하며, (3) 차등 압축 예산 할당을 통해 기존 압축 방법의 근본적인 한계를 보완한다는 점을 강조한다. 향후 연구 방향으로는 더 큰 LLM(예: GPT‑3, LLaMA)에서 고품질 SAEs를 학습하고, 능력‑민감도 평가 세트를 구축해 CGC의 효과를 정량화하는 것이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기